Welcome to Shanshan Blog!
-
计算广告学 笔记3.1 受众定向
课程地址:计算广告学
课时14 受众定向的概念
受众定向是指按人群来划分对广告的售卖和优化,它是在线广告中最核心的部分。受众定向是在线广告区别于线下广告最本质的部分。
受众定向是为ROI优化中打标签的过程,它是对Ad,User,Context打标签。受众定向中有一种特殊的定向,上下文标签,即通过用户所浏览的网页,判断用户的兴趣。这种定向一般认为是上下文定向,但个人认为上下文标签也可以认为是用户即时的兴趣或是标签。
标签有两大主要作用:1. 建立面向广告主的流量售卖体系,这一点本身就决定了标签不能按系统优化的思路来设计,即所打的标签一定要能被广告主理解。比如对上下文打标签,要对页面进行分类,个人认为更有效的方式是对页面进行supervise learning,即预先定义好标签体系,然后对页面进行分类,而不应该直接用聚类的方法或是Topic Model的方法打出一些无法直接解释的标签,因为无法对广告主进行售卖。这点是广告与其它用户产品不同的地方。2. 为各机器学习模块(如CTR预测)提供原始特征,比如提供性别,年龄等特征供机器学习分析。
举一个例子来说明什么是一个标签体系,广告有三个轴,User,Ad,Context。
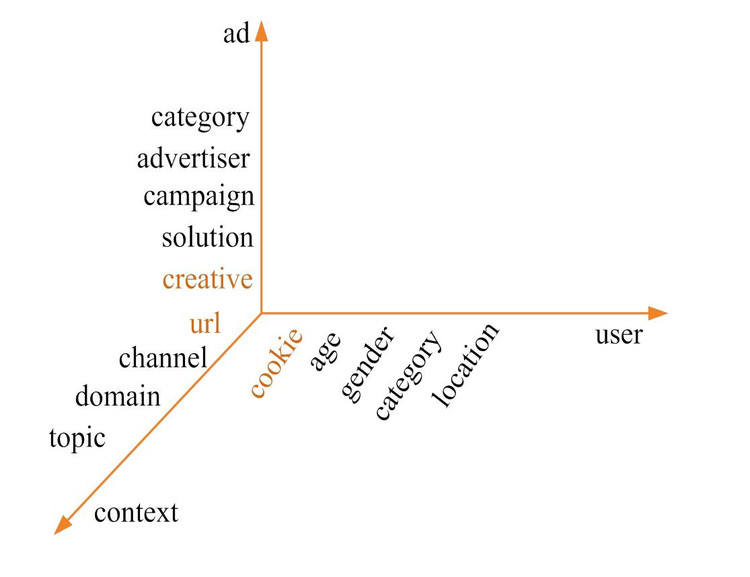
受众定向方式,我们基本可以分为三类。1. 对user提feature,2. 对context提feature,为什么要将这两类分开,我前面讲对可以将context看成是即时受众标签,但因为它们系统上的解决方案是不一样的,所以将它们分开。3. 对Ad和User的组合打标签,即在特定的广告主条件下,用户应该打什么标签,这种标签就引出了我们后面要讲的Demand方的Audience Segmentation,即根据广告主的逻辑给用户打标签。
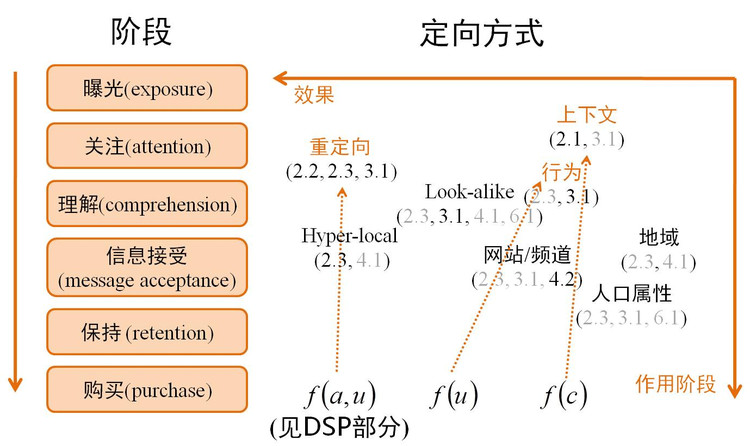
我们逐个看一下图中的定向方法。我们从效果最好的看起,效果最好的是重定向,它是公认的对direct response最好的一种方式,这种方式就是f(a,u),即demand-side的定向方式,它做的事很简单,如果一个用户访问过广告主的网站,就给用户打上某一种标签。2.2明确揭示推荐的原因,比如我是京东用户,我看到京东的广告,我非常清楚为什么这个广告会推给我。2.3 符合用户的意义,这点也是满足的,因为我访问过这个网站,3.1 广告是在用户的理解范围,这点当然也是满足的。国内做重定向的公司很多,比如淘宝的站外广告就很多。重定向从最早产生的motivation上个人认为是有两个层次,第一个层次是做品牌广告,品牌广告就是前面举的例子,我曾经去过一个网站,如果这个网站品牌再由有价值的媒体推送给我,我会感觉自己的决策是正确的,并会对这个网站品牌更有信心。另一层次是效果广告,比如我现在要买一个电视机,我在京东上是处在浏览阶段,或是加入购物车,或是已经下单,它会针对用户所处的阶段,会做非常细分的促销策略,比如用户在浏览阶段,那所投的广告最好是让用户能转化到加入购物车,比如发给用户一些热销或是促销的商品。如果用户已经加入购物车,广告最应该是促进用户下单的。如果用户已经付款了,广告应该将他所购买的相似产品推荐给他。淘宝的Retargeting技术个人感觉还是有些单一,比如你去淘宝某一网店买过玩具,它就会一直推荐玩具品类的广告,但效果也是不错的,然而仍有深挖的空间。
地域和人口属性概念很好理解,它是Ad Serving和合约式广告系统就产生了的定向方式,为了把流量粗分一下,把流量卖出更高的价格,这种定向方式是很粗浅的,人口基本就是性别,年龄等几种不多的类别(注:在社交广告中人口属性会多一些,比如腾讯广告,它掌握比较多的人口信息),人口属性定向成为必备的定向方式是因为这是广告主所熟悉的语言,在线下广告就用的是这种方式,所以用这种方式是最容易被广告主接受的方式。地域基本就是按IP地址分地区。
我们重点探讨上下文和行为,上下文是对context打标签的行为,它的原理:2.1 不要打断或干扰用户的任务,这是上下文之所以成立的一个原理性的原因,3.1 广告是在用户的理解范围之内,比如用户所看的财经网页,广告是E-Trade,用户肯定是有兴趣,也是能理解的,它的效果如果做的好,是比人口属性和地域定向方式要好,但它远远不能与重定向相比。行为定向是根据用户的历史行为进行推荐,比如用户浏览过哪些网页,搜索过哪些关键字,甚至用户线下的一些线下行为。中国的广告线下行为应用的不多,但美国广告线下行为使用的很多。它的效果与上下文总体来讲差不多。网站/频道这种定向非常简单,比如女性,军事频道。它对某些特定的频道效果还可以,比如汽车频道,汽车广告的效果会好很多。
Hyper-local对应对地域定向,传统所说的地域定向一般是到城市级别或到省的级别,但这种定向效果一般,Hyper-local是把地域定向做到非常细的粒度,比如定向清华园的主楼附近,这种定向会产生非常多的新的广告的需求,比如一个咖啡店就可以定向它附近的人群,而不使用这种定向,类似咖啡店,小饭馆的广告主无法投门户广告和搜索引擎广告,它唯一的选择是在路边发广告。
Look-alike是Demand side的定向方式,刚才提到重定向的效果是非常好的,但是它的数据量非常小,并且数据量不由广告平台决定,是由广告主的网站决定的。一些线上业务不是很强,但又有reach它用户的需求的广告主,比如银行和汽车网站,网站流量不大,也可以对它们做retargeting,但是量太小,没什么价值。所以它们希望达到的是广告平台通过海量数据,找到与广告主网站用户相似的人群。比如:银行可以提供一万个信用卡用户,然后广告平台用一万个信用卡用户信息来找到十万个可能对该银行信用卡感兴趣的人群。这种方式可以认为是重定向的扩量的行为,一般来讲,在同样量的基础上,它要比与demand side无关的方式要好。
概括地讲,定向方式的趋势是:先是线下对一些对人口分类的一些逻辑,先移到了线上,逐渐产生了上下文定向,行为定向,网站/频道定向等一些定向方式,这些方式都可以称为Supply side定向方式,最后产生的是Demand side定向方式,有重定向和Look-alike定向方式。
Audience Science公司是比较早提出Audience Targeting的概念的,它的核心业务是:1 主要提供面向publish的数据加工服务。比如它的一个大客户NewYork Times,NewYork Times自己有很多用户,也有很多在线数据,但很显然它的核心业务不是做广告,也不是做数据加工,它更愿意把数据交给Audience science,Audience science帮它加工一些有意义的用户标签,比如财经类用户,体育类用户。NewYork Times的BI可以用这些标签,分析哪些用户对哪些内容感兴趣,应该如何优化内容。2. Audience Science还直接运营ad network,并帮助广告主进行campaign管理和优化,这里它就用到了它分析得到的标签。
Audience Science数据标签不像bluekai那样在市场上公开出售,仅供委托他们优化compaign的广告商使用,即它的标签只为它自己的network服务。使用标签impression创造的营收执照一定比例跟publisher分成。
具体的工作流程是:publisher先把自己的流量托管给audience science,并给Audience Science一定的技术服务费,Audience Science把数据加工成标签,首先提供给publisher用,publisher用标签优化它的流量和BI。同时它在自己的Ad Network中对这些数据进行变现,变现的数据过来又可能与publish分成。
-
计算广告学 笔记2 合约广告
课程地址:计算广告学
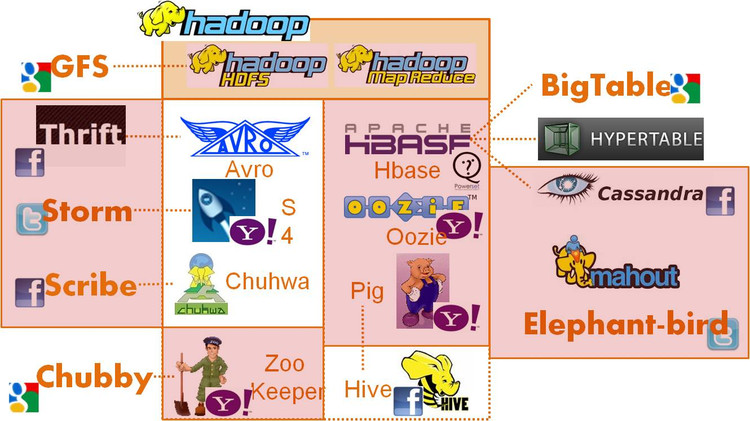
课时10 常用广告系统开源工具
-
离线数据处理: hadoop/hbase/cassandra
-
在线数据处理:storm/s4
-
跨语言通信:thrift/proobuf/avro, elephant bird
-
一致性:zoo keeper/chubby
-
数据查看:hive/pig
-
数据传输:scribe
课时11 合约广告简介
在线广告的方法有:
- 担保式投送(Guaranteed Delivery, GD)
基于合约的广告机智,约定的量未完成需要向广告商补偿 量(Quantity)优先于质(Quality)的销售方式 多采用千次展示付费(Cose per Mille, CPM)方式结算
- 广告投放机(Ad server)
CPM方式必然要求广告投送由服务器端完成决策 受众定向,CTR预测和流量预测是广告投放机的基础 GD合约下,投放机满足各合约的量,并尽可能优化各广告主流量的质
竞价广告(CPM/CPC/CPA):竞价广告,即根据实时竞价,在信息流中以不固定位置出现,并按照广告效果付费的广告形式。竞价期间,出价较高的广告主可获得优先展示资格,其广告效果同时可获得更多保证。
-
CPM(cost per mille):千人展示成本,即广告被展示1000次所需要的费用。
-
CPC(cost per click):单次点击成本,即广告被点击一次所需要的费用。
-
CPA(cost per action):单次下载成本,即APP被下载一次所需要的费用。仅限安卓APP。
课时12 在线分配问题
在线分配问题的核心是:在量的某种类型的限制下,完成对质的优化。
因为有量的限制,它是一个constrained optimization(受限优化)的问题,最早google提出的是AdWords Problem。
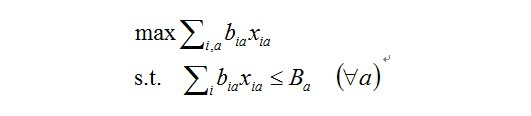
目标函数,b_ia是把一次展示(Impression,i)分给一个(Ad, a)产生的收益(bid * ctr, b,即ecpm),xia是指一次展示(impression, i)是否分给了一个广告(Ad, a),这个值只能为0或是1,因为一次展示只能或是分配给一个广告,或是没分配。sum(i, a)也就是整个系统的收益,max sum(i,a)即是优化的核心问题:如何最大化整个系统的收益。它的限制是:对每个广告商来讲,有一个budget,每个广告商所消耗的资金应该小于他的budget,即式中Ba。
后来研究者把这个问题推广到display problem,display problem中有很多CPM的campaign,它希望优化的是每一个CPM的效果。
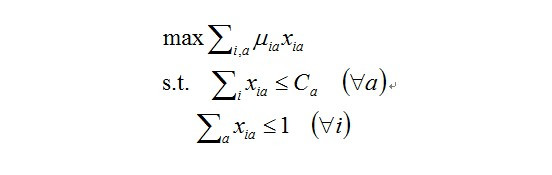
效果即是它收获到的点击量,点击量的计算方法为把所有的展示的Xia乘上点击率起来就是点击量。优化目标有两个constrain,一个是称之为Demand Constrain,它是指每一个广告商来讲,他需要Ca次展示,那么媒体提供的展示数应该小于等于Ca,注意这里是NGD的问题,广告系统提供的展示次数可以小于需求的量,另一个Constrain是Supply Constrain,是对于任何展示,xia加起来小于等于1,可以小于是因为这次广告也可以不分配给任何广告,它可以交给下游的其它变现手段。
拉格朗日方法
http://blog.csdn.net/wangkr111/article/details/21170809
这里引入了对偶函数,原因是因为包含了不等式约束的极值问题.探讨有不等式约束的极值问题求法,问题如下:
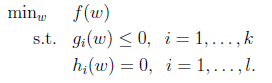
我们定义一般化的拉格朗日公式
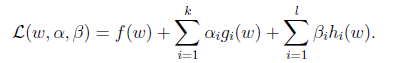
这里的alpha和beta都是拉格朗日算子。如果按这个公式求解,会出现问题,因为我们求解的是最小值,而这里的g(w)已经不是0了,我们可以将alpha调整成很大的正值,来使最后的函数结果是负无穷。因此我们需要排除这种情况,我们定义下面的函数:
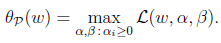
这里的P代表primal。那么我们总是可以调整alpha和beta来theta使得有最大值为正无穷。而只有g和h满足约束时,为f(w)。这个函数的精妙之处在于a_i>0,而且求极大值。 因此我们可以写作
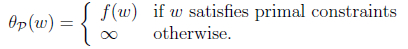
怎么求解? 我们先考虑另外一个问题
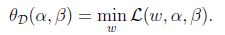
D的意思是对偶,将问题转化为先求拉格朗日关于w的最小值,将alpha和β看作是固定值。之后在求最大值的话:
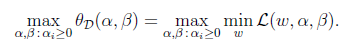
High Water Mark算法
Yahoo!实际系统中用的方法,它分两个阶段,离线计划阶段和在线分配阶段。

课程13 Hadoop简介
Hadoop目标可以概括为:可扩展性: Petabytes (1015 Bytes) 级别的数据量, 数千个节点,经济性: 利用商品级(commodity)硬件完成海量数据存储和计算,可靠性: 在大规模集群上提供应用级别的可靠性。
Hadoop包含两个部分:
- HDFS
HDFS即Hadoop Distributed File System(Hadoop分布式文件系统),HDFS具有高容错性,并且可以被部署在低价的硬件设备之上。HDFS很适合那些有大数据集的应用,并且提供了对数据读写的高吞吐率。HDFS是一个master/slave的结构,就通常的部署来说,在master上只运行一个Namenode,而在每一个slave上运行一个Datanode。
- MapReduce
Map/Reduce模型中Map之间是相互独立的,因为相互独立,使得系统的可靠性大大提高了。
它是用调度计算代替调度,在处理数据时,是将程序复制到目标机器上,而不是拷贝数据到目标计算机器上。
常用的统计模型
机器学习的算法有很多分类,其中有统计机器学习算法,统计机器学习在Hadoop上仅仅实现其逻辑是比较简单的。常用的统计模型可以大致归为下面两个类别:
- 指数族分布
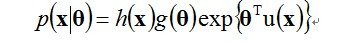
指数族分布是由最大熵的原则推导出来的,即在最大熵的假设下,满足一定条件的分布可以证明出是指数族的分布。指数族分布函数包括:Gaussian multinomial, maximum entroy。
指数族分布在工程中大量使用是因为它有一个比较好的性质,这个性质可以批核为最大似然(Maximum likelihook, ML)估计可以通过充分统计量(sufficient statistics)链接到数据(注:摘自《Pattern Recognition》),要解模型的参数,即对theta做最大似然估计,实际上可以用充分统计量来解最大似然估计:
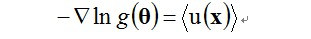
充分估计量大小是与模型的参数的空间复杂度成正比,和数据没有关系。换言之,在你的数据上计算出充分统计量后,最就可以将数据丢弃了,只用充分统计量。比如求高斯分布的均值和方差,只需要求出样本的与样本平方和。
Map Reduce 统计学习模型
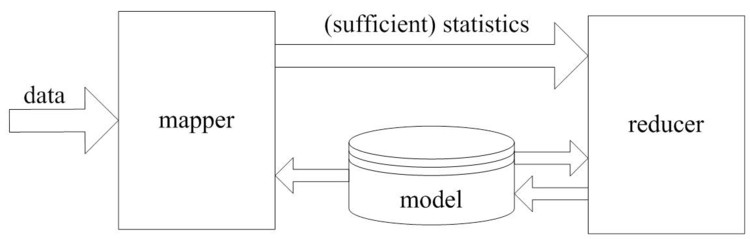
Map的过程是收集充分统计量,充分统计量的形式是u(x),它是指数族函数变换函数的均值。所以我们只需要得到u(x)的累加值,对高斯分布来讲,即得到样本之和,和样本平方和。Reduce即根据最大似然公式解出theta。即在在mapper中仅仅生成比较紧凑的统计量, 其大小正比于模型参数量, 与数据量无关。在图中还有一个反馈的过程,是因为是EM算法,EM是模拟指数族分布解的过程,它本质上还是用u(x)解模型中的参数,但它不是充分统计量所以它解完之后还要把参数再带回去,进行迭代。
-
-
计算广告学 笔记1 广告的基本知识
- 课时1 广告的目的
- 课时2 广告的有效性模型
- 课时3 广告与营销的差别
- 课时4 在线广告的特点
- 课时5 在线广告市场
- 课时6 计算广告核心问题和挑战
- 课时7 广告,搜索和推荐的比较
- 课时8 投资回报ROI分析
- 课时9 在线广告系统模块
课程地址:计算广告学
课时1 广告的目的
广告,推荐,搜索,这三个领域我们称为wide scale challenge(大规模数据挑战)。广告中文字推荐高于图片广告 但对于推荐系统图片广告高于文字广告
“广告是由已确定的出资人通过各种媒介进行的有关产品(商品、服务和观点)的,通常是有偿的、有组织的、综合的、劝服性的非人员的信息传播活动。” —— 广告(Advertising)的定义来自于阿伦斯的《现代广告学》。
-
广告的主体:广告主(advertiser),媒介(medium),受众(audience)
-
本质:借助某种广泛受众的媒介的力量,完成较低成本的用户接触(reach)
品牌广告和效果广告
-
品牌广告(Brand Awareness):目的在于提升较长时期内的离线转换率。能够为企业长期带来利润空间。
-
效果广告(Direct Response):有短期内明确用户转化行为诉求的广告。
课时2 广告的有效性模型
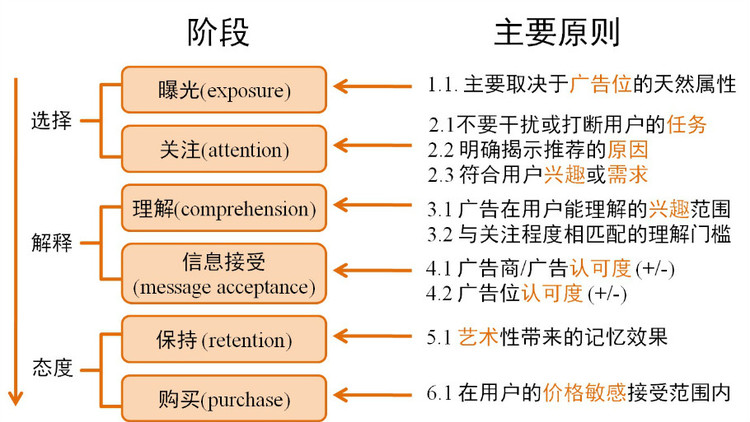
-
曝光:它是指广告是否被用户所看到,它是由广告位的天然属性所决定,无法通过算法的方式进行优化。
-
关注(attention)是指用户在看到广告后,是否注意到这个广告。可通过算法优化
-
理解是指用户的确理解广告的内容
-
信息接受是指用户理解广告的内容,并认同广告中的内容。
-
保持是指在相当长的时间内,都能想起一个品牌,并可能购买这个品牌的商品。
-
购买的效果取决于是否在用户的价格敏感接受范围
对广告有两点基本的评价指标,点击率和后续的转化率。
课时3 广告与营销的差别
两者的区别是广告主要针对的是潜在用户,而销售是针对对商品有明确需求的人。
广告的目的是通过媒介传播企业形象或产品信息,而销售的目的是提升产品销量。 广告的效果是特定人群的有效reach,而销售的效果是收入和利润。
课时4 在线广告的特点
在线广告的特点
-
技术和计算导向: 在线广告和线下广告产品运行的形态有很大不同,在线广告一直在被技术和产品驱动,与之相对的线下广告是被创意和客户关系驱动。数字媒体的特点使在线广告可以进行精细的受众定向,即对不同的用户推荐不同的广告。技术使得广告决策和交易朝着计算驱动的方向发展,计算已经成为广告中主导的部分,而商业逻辑作为辅助的部分。
-
可衡量性:广告的点击是广告效果的直接收集途径,可以很直接地从点击率中看到广告的效果。
-
标准化:技术投放和精准定向促进了在线广告的标准化
课时5 在线广告市场
第三个阶段:Supply产生了广告交易的平台,就是AdExchange,Demand方对应产生了DSP(Demand Side Platform)。
Supply有三种技术变现的方式:
-
托管给Ad Network,比如,一个网站有一个广告位,它可以在AdSense里注册这个广告位,即托管给AdSense,AdSense的下游是Automated Trading Desk(ATD),ATD从多个AdExchange中买流量,并有优化ROI的功能。
-
托管给广告交易市场,即托管给AdExchange。比如google display network会将它竞价比较低的流量导给AdExchange,让AdExchange进行实时竞价,实时竞价的好处是一些小的流量可能会以比较高的价格卖出。AdExchange会接受DSP的出价,而DSP与Agency是一起的。
-
SSP(Supply Side Platform)。它产生的原因是AdSense这些网站是优化自己广告平台的营收,而不是网站的营收,而网站当然有优化自己营收的诉求,而SSP就是站到媒体的利益方来设计优化方案。
课时6 计算广告核心问题和挑战
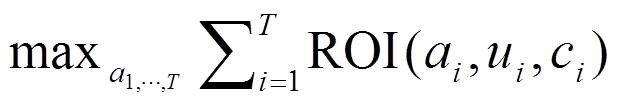
公式中a表示Sponsor(advertiser),c表示媒体(context),u代表受众(user)。公式的含义是:给定user,给定context,选择一组ad,使得ROI最高。
从优化角度看它涉及:
-
特征提取:受众定向,即把u和c打上标签的过程。
-
微观优化:对一次展示进行优化,得到最好的广告,最关键的技术是CTR预测。
-
宏观优化:因为在线广告是用户,媒体,广告商三方博弈,所以竞价市场机制的设计非常重要。
-
受限优化:在量一定的情况下,怎么来优化质,在线分配就是这个问题。
-
强化学习:如何知道在新的广告主或新的用户群预测它的点击率,很直觉的想法是尝试,分配一定的流量给广告,看是男性用户点击率高还是女性。但是在尝试的过程中会损失一部分收入,因为不是按最优策略出广告的了。尝试的过程即探索,使用探索的结果即利用。
-
个性化重定向。
从系统角度涉及:
-
候选查询:要使用实时索引技术,使广告能很快地进入索引,很快指两个方面,新的广告要能尽快上线,广告预算用完的广告要尽快下线。
-
特征存储:在线高并发要用到一些No-Sql技术。
-
离线学习:很多时候要用到Hadoop。
-
在线学习:一些比较快的反馈,比如得到用户上一个搜索词,要用到流计算技术。
-
交易市场:要用到实时竞价。
在线广告计算的主要挑战有:
-
大规模(Scale):线投放系统中的高并发挑战 (例: Rightmedia每天处理百亿次广告交易,它会向多个DSP去请求,即每天要进行千亿次的请求),响应速度在常见的web应用中可能是最高的。
-
动态性(Dynamics):需要所建立的模型支持快速变化,比如涉及到CTR预测,那么模型参数是否能快变,特征是否能快速改变都是有挑战的。
-
丰富的查询信息 (Rich query)
-
探索与发现 (Explore & exploit):用户反馈数据局限于在以往投放中出现过的(a, u, c)组合,需要主动探索未观察到的领域,以提高模型正确性。
课时7 广告,搜索和推荐的比较

广告明显比搜索容易部分的是不需要复杂的爬虫技术和PageRank。而它比搜索困难的地方是它需要建模的数据量比搜索要大。搜索,广告与推荐三者的主要区别在于它们的准则不同,搜索主要是针对相关性,广告主要针对ROI。
推荐和广告比较大的区别是:推荐进行的是同质化的推荐,另外推荐还有优化流(downstream)的概念,比如用户在看新闻时,会根据推荐跳到另一个新闻页面,而在这个新闻页面上可以继续推荐,优化流是指优化整个根据推荐看新闻过程的点击率。而对于广告来讲,推荐出的广告点击后,就跳到目标页面了,就不可能有优化downstream的机会了。
课时8 投资回报ROI分析

点击率(CTR),点击率是用户(u),广告(a),上下文(c)三者的函数,点击价值是用户(u)和广告(a)的函数,可以认为与上下文(c)无关,因为用户已经跳到商品所在的页面了。
eCPM,点击率与点击价值之积是eCPM(expect CPM),它是非常重要的一个值。Return是每次eCPM的累加值。
不同的分解对应不同的市场形态。CPM市场:是固定的eCPM,由媒体和代理商结算,是由代理商自己估算展示的价值,风险是在Demand方,这种方式对媒体有利。这种方式对品牌广告有一定优势,因为品牌广告受到广告影响是一个长期的过程,很难估算ROI。CPC市场:它是将ROI分成点击率和点击价值,广告系统负责估计点击率,而广告主负责估计点击价值。广告主只需要告诉广告系统一次点击的价值是多少。
课时9 在线广告系统模块
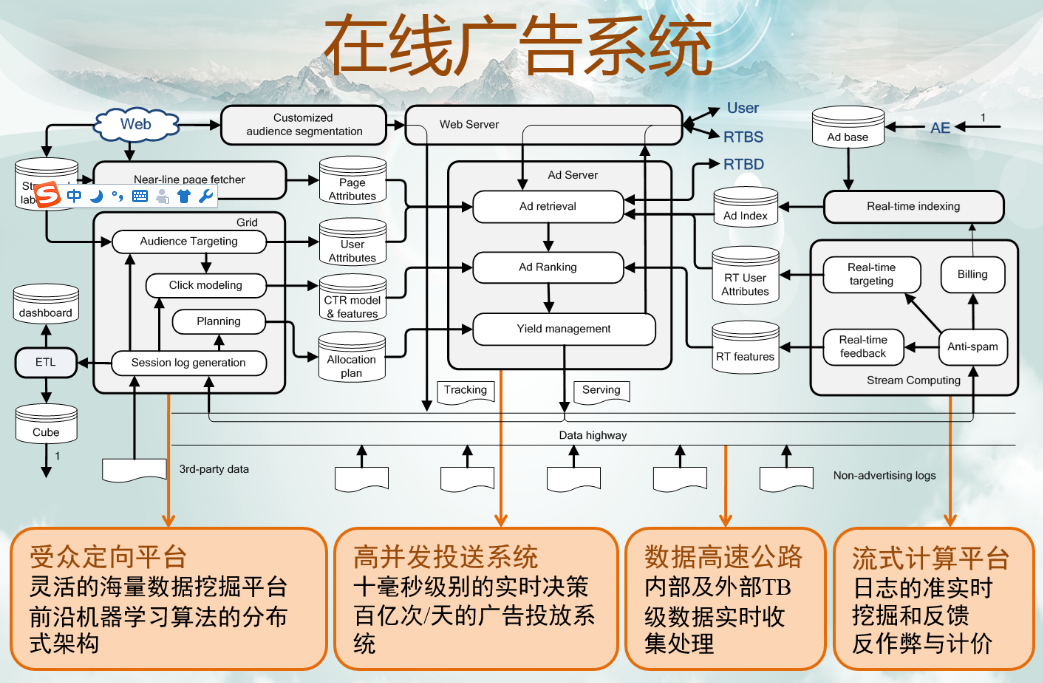
搭建一个广告系统有以下几个重要组成部分:
-
高并发的投送系统,即在线的AdServer,它通过请求中的user和context信息来决定展示哪些ads。它的特点是高并发,要做到10ms级别的实时决策,百亿次/天的广告投放系统。
-
受众定向平台,它进行离线的数据挖掘分析,一般要用到Hadoop。比如进行点击率预测的分析。
-
数据高速公路,它是联系在线与离线的部分,它比较简单,可以用开源工具实现,它的作用是准实时地将日志推送到其它平台上,目的一是快速地反馈到线上系统中,二是给BI人员快速看结果。它还可能收集其它平台的日志,比如搜索广告会收集搜索日志。
-
流式计算平台,它是比Hadoop快的一个准实时分析平台,它要实现的功能:反作弊,计价,实时索引。
ad serving:ad call的产生一是用户直接产生,二是通过exchange过来。
retrieval:根据ad call的实际情况找到符合定位情况的广告
ranking:准则是eCPM
session log generation:定位要根据用户行为来决定,这个LOG就是将某用户一天的行为写成一份日志,成为算法的基础。
log提供给data warehouse 或BI,BI是数据和人的接口,根据人的需求提供差别性的查询报表。
session log也可以做受众定向,还可以做点击率模型,进行预算,计算eCPM,供ranking使用
page fetcher: 广告不需要全网的爬虫,只需要有广告投放的页面。会爬出有广告投放的attribution(标签)。标签为广告的retrieval服务。
customized audience segmentation: 广告比较独特的一点。很多时候媒体划分的人群等分类与广告主的分类需求差别很大,这就需要为广告主个性化的分类的服务。广告主的信息要注入到媒体当中。
RTBD和RTBS:前者是自己实时向别人做ad call,这样自己就是一个exchange,而后者是别人向我做ad call,我根据ad call向DSP询价。这两者是RTB的两个方面。
-
Scala Tutorial
Scala Tutorial
```scala // first scala
object hello { def main(args: Array[String]): Unit = {
println(“hello\tworld\n”)
}
}// synatix /* Scala 基本语法需要注意以下几点: 区分大小写 - Scala是大小写敏感的,这意味着标识Hello 和 hello在Scala中会有不同的含义。 类名 - 对于所有的类名的第一个字母要大写。
如果需要使用几个单词来构成一个类的名称,每个单词的第一个字母要大写。
示例:class MyFirstScalaClass 方法名称 - 所有的方法名称的第一个字母用小写。
如果若干单词被用于构成方法的名称,则每个单词的第一个字母应大写。
示例:def myMethodName() 程序文件名 - 程序文件的名称应该与对象名称完全匹配。
保存文件时,应该保存它使用的对象名称(记住Scala是区分大小写),并追加”.scala”为文件扩展名。 (如果文件名和对象名称不匹配,程序将无法编译)。
示例: 假设”HelloWorld”是对象的名称。那么该文件应保存为’HelloWorld.scala” def main(args: Array[String]) - Scala程序从main()方法开始处理,这是每一个Scala程序的强制程序入口部分。 */
//换行— ;
//package package test class HelloWorld //import all import test._
//variable /* Byte 8位有符号补码整数。数值区间为 -128 到 127 Short 16位有符号补码整数。数值区间为 -32768 到 32767 Int 32位有符号补码整数。数值区间为 -2147483648 到 2147483647 Long 64位有符号补码整数。数值区间为 -9223372036854775808 到 9223372036854775807 Float 32位IEEE754单精度浮点数 Double 64位IEEE754单精度浮点数 Char 16位无符号Unicode字符, 区间值为 U+0000 到 U+FFFF String 字符序列 Boolean true或false Unit 表示无值,和其他语言中void等同。用作不返回任何结果的方法的结果类型。Unit只有一个实例值,写成()。 Null null 或空引用 Nothing Nothing类型在Scala的类层级的最低端;它是任何其他类型的子类型。 Any Any是所有其他类的超类 AnyRef AnyRef类是Scala里所有引用类(reference class)的基类 */
//变量声明
var str : String = “Test” var num : Int = 123 var flo : Float = 12.3f val bo : Boolean = true
//访问修饰符:private, protected, public
//运算符和C++的都一样
//if, else if 和 C++ 都一样 // scala 里没有break和continue,但有一个Breaks类 import scala.util.control._
object hello { def main(args: Array[String]): Unit = {
println(“hello\tworld\n”) var str : String = “Test” var num : Int = 13 var flo : Float = 12.3f val bo : Boolean = true var loop = new Breaks; loop.breakable { for (num <- 13 to 17) { println(num) if (num == 15) loop.break; } } }
}//function
object func { def divideInt(a : Int, b : Int) : Int = { var sum : Int = 0 sum = a * b return sum
} def emptyRes(a : Int) : Unit = { println(a)
}
def main(args: Array[String]) { println(divideInt(1, 2)) } } //unit means return emptyRes
// scala 的string是不可变的,所以要操作的话,只能使用String Builder 类 object str { def main(args: Array[String]) { var buf = new StringBuilder buf += ‘a’ buf ++= “ahdhd” println(buf.toString) } }
// ‘a’字符用+=,”aaaa”字符串用++=
// scala 闭包和Python的匿名函数是一个意思
//Array import Array._
object arrayExample { var z = Array(“cece”, “shanshan”, “haha”) var z2 = new ArrayString z(0) = “cece” z(1) = “shanshan” z(2) = “haha” for (i <- 0 to (z.length - 1)) { println(z(i)) }
// 多维数组 var myMatrix = ofDim[Int](3,3) for (i <- 0 to 2) { for (j <- 0 to 2) { print(myMatrix(i)(j)) } println() } }//Scala里有和Python中数组相似的函数 //例如concat,range, apply, fill
// collection // 定义整型 List val x = List(1,2,3,4)
// 定义 Set var x = Set(1,3,5,7)
// 定义 Map val x = Map(“one” -> 1, “two” -> 2, “three” -> 3)
// 创建两个不同类型元素的元组 val x = (10, “Runoob”)
// 定义 Option val x:Option[Int] = Some(5)
-
Protocol Tutorial
- Define A Message Type
- What’s Generated From Your .proto?
- Scalar Type
- Enumerations
- Using Other Message Types
- Nested Types
- Packages
- Options
- Generating Classes
Protocol buffers are Google’s language-neutral, platform-neutral, extensible mechanism for serializing structured data – think XML, but smaller, faster, and simpler. You define how you want your data to be structured once, then you can use special generated source code to easily write and read your structured data to and from a variety of data streams and using a variety of languages.
You can get it from Developer Google
Define A Message Type
Here’s the .proto file you use to define the message type.
message SearchRequest { required string query = 1; optional int32 page_number = 2; // Which page number do we want? optional int32 result_per_page = 3; }The
SearchRequestmessage definition specifies three fields (name/value pairs), one for each piece of data that you want to include in this type of message. Each field has a name and a type.Specifying Field Types
In the above example, all the fields are scalar types: two integers (page_number and result_per_page) and a string (query). However, you can also specify composite types for your fields, including enumerations and other message types.
Assigning Tags
Each field in the message definition has a unique numbered tag. These tags are used to identify your fields in the message binary format, and should not be changed once your message type is in use. Note that tags with values in the range 1 through 15 take one byte to encode, including the identifying number and the field’s type. Tags in the range 16 through 2047 take two bytes. So you should reserve the tags 1 through 15 for very frequently occurring message elements. Remember to leave some room for frequently occurring elements that might be added in the future.
### Specifying Field Rules
You specify that message fields are one of the following:
-
required: a well-formed message must have exactly one of this field.
-
optional: a well-formed message can have zero or one of this field (but not more than one). optinoal to set default value:
optional int32 result_per_page = 3 [default = 10];- repeated: this field can be repeated any number of times (including zero) in a well-formed message. The order of the repeated values will be preserved.
What’s Generated From Your .proto?
When you run the protocol buffer compiler on a .proto, the compiler generates the code in your chosen language you’ll need to work with the message types you’ve described in the file, including getting and setting field values, serializing your messages to an output stream, and parsing your messages from an input stream.
-
For C++, the compiler generates a .h and .cc file from each .proto, with a class for each message type described in your file.
-
For Java, the compiler generates a .java file with a class for each message type, as well as a special Builder classes for creating message class instances.
-
Python is a little different – the Python compiler generates a module with a static descriptor of each message type in your .proto, which is then used with a metaclass to create the necessary Python data access class at runtime.
-
For Go, the compiler generates a .pb.go file with a type for each message type in your file.
Scalar Type
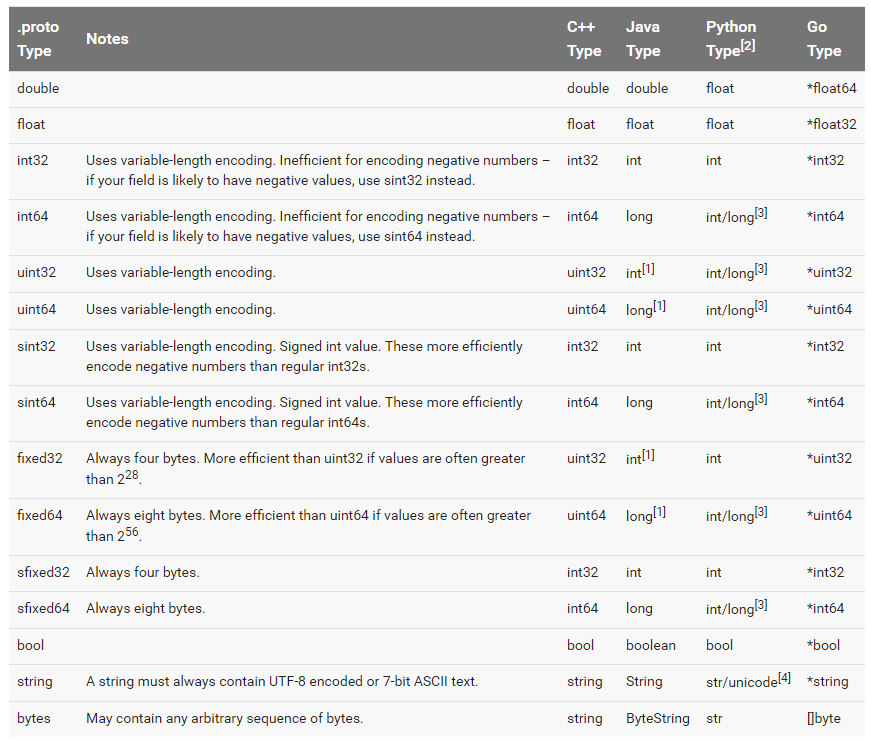
You can get more encoding from Encoding
Enumerations
For example, let’s say you want to add a
corpusfield for eachSearchRequest, where the corpus can be UNIVERSAL, WEB, IMAGES, LOCAL, NEWS, PRODUCTS or VIDEO. You can do this very simply by adding an enum to your message definition - a field with an enum type can only have one of a specified set of constants as its value (if you try to provide a different value, the parser will treat it like an unknown field). In the following example we’ve added an enum called Corpus with all the possible values, and a field of type Corpus:message SearchRequest { required string query = 1; optional int32 page_number = 2; optional int32 result_per_page = 3 [default = 10]; enum Corpus { UNIVERSAL = 0; WEB = 1; IMAGES = 2; LOCAL = 3; NEWS = 4; PRODUCTS = 5; VIDEO = 6; } optional Corpus corpus = 4 [default = UNIVERSAL]; }Using Other Message Types
If you wanted to include
Resultmessages in eachSearchResponsemessage – to do this, you can define aResultmessage type in the same .proto and then specify a field of type Result inSearchResponse:Importing Definitions
In the above example, the Result message type is defined in the same file as SearchResponse – what if the message type you want to use as a field type is already defined in another .proto file?
You can use definitions from other .proto files by importing them. To import another .proto’s definitions, you add an import statement to the top of your file:
import "myproject/other_protos.proto";Nested Types
message SearchResponse { message Result { required string url = 1; optional string title = 2; repeated string snippets = 3; } repeated Result result = 1; }Packages
You can add an optional
packagespecifier to a.protofile to prevent name clashes between protocol message types.package foo.bar; message Open { ... }You can then use the package specifier when defining fields of your message type:
message Foo { ... required foo.bar.Open open = 1; ... }The way a package specifier affects the generated code depends on your chosen language:
-
In C++ the generated classes are wrapped inside a C++ namespace. For example, Open would be in the namespace foo::bar.
-
In Java, the package is used as the Java package, unless you explicitly provide a option java_package in your .proto file.
-
In Python, the package directive is ignored, since Python modules are organized according to their location in the file system.
Options
Individual declarations in a .proto file can be annotated with a number of options. Options do not change the overall meaning of a declaration, but may affect the way it is handled in a particular context. The complete list of available options is defined in
google/protobuf/descriptor.proto.Here are a few of the most commonly used options:
java_package(file option): The package you want to use for your generated Java classes. If no explicitjava_packageoption is given in the .proto file, then by default the proto package (specified using the “package” keyword in the .proto file) will be used. However, proto packages generally do not make good Java packages since proto packages are not expected to start with reverse domain names. If not generating Java code, this option has no effect.option java_package = "com.example.foo";java_outer_classname(file option): The class name for the outermost Java class (and hence the file name) you want to generate. If no explicit java_outer_classname is specified in the .proto file, the class name will be constructed by converting the .proto file name to camel-case (sofoo_bar.protobecomesFooBar.java). If not generating Java code, this option has no effect.option java_outer_classname = "Ponycopter";Generating Classes
The Protocol Compiler is invoked as follows:
protoc --proto_path=IMPORT_PATH --cpp_out=DST_DIR --java_out=DST_DIR --python_out=DST_DIR path/to/file.protoYou can provide one or more output directives:
-
--cpp_outgenerates C++ code inDST_DIR. See the C++ generated code reference for more. -
--java_outgenerates Java code inDST_DIR. See the Java generated code reference for more. -
--python_outgenerates Python code inDST_DIR. See the Python generated code reference for more.
-
StructType for Spark to create a DataFrame
It is from stack overflow
StructType
I assume you start with some kind of flat schema like this:
root |-- lat: double (nullable = false) |-- long: double (nullable = false) |-- key: string (nullable = false)First lets create example data:
import org.apache.spark.sql.Row import org.apache.spark.sql.functions.{col, udf} import org.apache.spark.sql.types._ val rdd = sc.parallelize( Row(52.23, 21.01, "Warsaw") :: Row(42.30, 9.15, "Corte") :: Nil) val schema = StructType( StructField("lat", DoubleType, false) :: StructField("long", DoubleType, false) :: StructField("key", StringType, false) ::Nil) val df = sqlContext.createDataFrame(rdd, schema)An easy way is to use an udf and case class:
case class Location(lat: Double, long: Double) val makeLocation = udf((lat: Double, long: Double) => Location(lat, long)) val dfRes = df. withColumn("location", makeLocation(col("lat"), col("long"))). drop("lat"). drop("long") dfRes.printSchemaand we get
root |-- key: string (nullable = false) |-- location: struct (nullable = true) | |-- lat: double (nullable = false) | |-- long: double (nullable = false)A hard way is to transform your data and apply schema afterwards:
val rddRes = df. map{case Row(lat, long, key) => Row(key, Row(lat, long))} val schemaRes = StructType( StructField("key", StringType, false) :: StructField("location", StructType( StructField("lat", DoubleType, false) :: StructField("long", DoubleType, false) :: Nil ), true) :: Nil ) sqlContext.createDataFrame(rddRes, schemaRes).showand we get an expected output
+------+-------------+ | key| location| +------+-------------+ |Warsaw|[52.23,21.01]| | Corte| [42.3,9.15]| +------+-------------+