Welcome to Shanshan Blog!
-
Hadoop HDFS Command
The Chinese one is from hadoop HDFS常用文件操作命令
HDFS is the primary distributed storage used by Hadoop applications. A HDFS cluster primarily consists of a NameNode that manages the file system metadata and DataNodes that store the actual data. The HDFS Architecture Guide describes HDFS in detail.
Basic HDFS command
hadoop fs -cmd < args >- ls
Files within a directory are order by filename by default.
hadoop fs -ls hadoop fs -ls /data- put
Copy single src, or multiple srcs from local file system to the destination file system. Also reads input from stdin and writes to destination file system.
hadoop fs -put < local file > < hdfs file > hadoop fs -put - < hdsf file> # read from keyboard to hdfs file, Ctrl+D to exit- moveFromLocal
Similar to put command, except that the source localsrc is deleted after it’s copied.
hadoop fs -moveFromLocal < local src > ... < hdfs dst >- copyFromLocal
Similar to put command, except that the source is restricted to a local file reference.
hadoop fs -copyFromLocal < local src > ... < hdfs dst >- get
Copy files to the local file system.
hadoop fs -get < hdfs file > < local file or dir> #the name of local's and hdfs cannot be the same- copyToLocal
smiliar with get
hadoop fs -copyToLocal < local src > ... < hdfs dst >- rm
remove file or directory
hadoop fs -rm < hdfs file > ... hadoop fs -rm -r < hdfs dir>...- mkdir
create directory
hadoop fs -mkdir < hdfs path>- getmerge
Takes a source directory and a destination file as input and concatenates files in src into the destination local file.
hadoop fs -getmerge < hdfs dir > < local file > hadoop fs -getmerge -nl < hdfs dir > < local file >- cp
Copy files from source to destination. This command allows multiple sources as well in which case the destination must be a directory.
hadoop fs -cp < hdfs file > < hdfs file >- mv
Moves files from source to destination.
hadoop fs -mv < hdfs file > < hdfs file >- count
Count the number of directories, files and bytes under the paths that match the specified file pattern.
hadoop fs -count < hdfs path >- du
Displays sizes of files and directories contained in the given directory or the length of a file in case its just a file.
hadoop fs -du < hdsf path> # every file hadoop fs -du -s < hdsf path> #all files sum hadoop fs -du - h < hdsf path>- text
Takes a source file and outputs the file in text format.
hadoop fs -text < hdsf file>- setrep
Changes the replication factor of a file. If path is a directory then the command recursively changes the replication factor of all files under the directory tree rooted at path.
hadoop fs -setrep -R 3 < hdfs path >- stat
Print statistics about the file/directory at
in the specified format. Format accepts filesize in blocks (%b), type (%F), group name of owner (%g), name (%n), block size (%o), replication (%r), user name of owner(%u), and modification date (%y, %Y). %y shows UTC date as “yyyy-MM-dd HH:mm:ss” and %Y shows milliseconds since January 1, 1970 UTC. If the format is not specified, %y is used by default. hdoop fs -stat [format] < hdfs path >- tail
Displays last kilobyte of the file to stdout.
hadoop fs -tail < hdfs file >- archive
compress files
hadoop archive -archiveName name.har -p < hdfs parent dir > < src >* < hdfs dst > hadoop fs -ls /des/hadoop.jar hadoop fs -ls -R har:///des/hadoop.har- balancer
hdfs balancer- dfsadmin
hdfs dfsadmin -help hdfs dfsadmin -report hdfs dfsadmin -safemode < enter | leave | get | wait > # enter:enter safe mode # leave:leave safe mode # get: to know whether to start safe mode # wait: wait for safe mode
-
500 Lines or Less Chapter 17: The Same-Origin Policy 翻译
介绍
同源政策(SOP)是每个现代浏览器安全机制的重要组成部分。它控制在浏览器中运行的脚本可以彼此通信(大致来自同一网站)。首先在Netscape Navigator中引入,SOP现在在Web应用程序的安全性中起着至关重要的作用;没有它,恶意骇客在Facebook上仔细阅读你的私人照片,阅读你的电子邮件或清空你的银行帐户将更容易。
但是SOP远非完美。有时,它太限制了;有些情况(如mashup),其中来自不同来源的脚本应该能够共享资源但它不能。在其他时候它没有足够的限制,留下可以利用跨站点请求伪造等常见攻击的角色情况。此外,SOP的设计多年来已经有机地发展,并且使许多开发人员困惑不解。
本章的目标是捕捉这个重要而又经常被误解的特征的本质。特别是我们将尝试回答以下问题:
-
为什么需要SOP?它阻止的安全违规类型是什么?
-
Web应用程序的行为如何受到SOP的影响?
-
绕过SOP有什么不同的机制?
-
这些机制有多安全?他们介绍的潜在安全问题是什么?
考虑到所涉及的部分的复杂性 - Web服务器,浏览器,HTTP,HTML文档,客户端脚本等,整体覆盖SOP是一项艰巨的任务。我们可能会被所有这些部件的粗细细节陷入僵局(并且在达到SOP之前消耗了我们的500行代码)。但是,如果没有代表关键的细节,我们怎么能做到精准呢?
Modeling with Alloy
本章与本书中的其他内容有所不同。我们将构建一个可执行模型,而不是构建一个工作的实现,作为一个简单而精确的SOP描述。可以执行该模型来探索系统的动态行为,但与实现不同,该模型忽略了可能妨碍基本概念的低级细节。
我们采取的方法是“agile modeling”,因为它与agile programming相似。我们逐步组装模型直至可执行,并制定和运行测试时,所以最终我们不仅拥有模型本身,还包含了它所满足的属性集合。
为了构建这个模型,我们使用Alloy,一种用于建模和分析软件设计的语言。Alloy modelling不能以传统的程序执行方式执行。相反,模型可以(1)模拟以产生表示系统的有效场景或配置的实例,以及(2)检查以查看模型是否满足期望的属性。
尽管有上述的相似之处,agile modeling不同于agile programming:虽然我们将会运行测试,但实际上并不会写任何内容。 Alloy的分析仪自动生成测试用例,需要提供的所有测试用例要检查的属性。这节省了很多麻烦(和文字)。分析器实际上执行所有可能的测试用例,直到一定的范围;这通常意味着产生具有一定数量的对象的所有起始状态,然后选择操作和参数来应用到一些步骤。由于执行了许多测试(通常是数十亿次),并且由于所有可能的状态可能会被配置覆盖,所以这种分析倾向于比常规测试更有效地显示错误(有时被称为”bounded verification”)。
简化
由于SOP在浏览器,服务器,HTTP等环境中运行,所以完整的描述将是压倒性的。因此,我们的模型(如所有模型)抽象出不相关的方面,例如网络数据包的结构和路由。但也简化了一些相关的内容,这意味着该模型无法充分说明所有可能的安全漏洞。
例如,我们将HTTP请求视为远程过程调用,忽略了对请求的响应可能会出错的事实。我们还假设DNS(域名服务)是静态的,所以我们不考虑在交互过程中DNS绑定变化的攻击。原则上,这样做可以扩展我们的模型来涵盖所有这些的内容,在安全分析的本质上,没有模型(即使它代表整个代码库)也可以被保证是完整的。
Roadmap
以下是我们使用的SOP模型的顺序。首先构建我们需要的三个关键组件的模型,以便我们讨论SOP:HTTP,浏览器和客户端脚本。我们将建立在这些基本模型之上,以定义Web应用程序的安全性意义,然后将SOP作为尝试实现所需安全属性的机制。
然后,我们将看到SOP有时太限制,阻碍了Web应用程序的正常运行。因此,我们介绍四种不同的技术,通常用于绕过策略强加的限制。
随意浏览你想要的任何顺序的部分。如果你是Alloy的新人,我们建议从前三部分(HTTP,浏览器和脚本)开始,因为它们介绍了agile language的一些基本概念。在阅读本章的过程中,我们鼓励你使用Alloy Analyzer;运行它们,探索生成的场景,并尝试修改并查看其效果。它可以免费下载。
Model of the Web
HTTP
构建Alloy model的第一步是声明对象。 我们从资源开始:
sig Resource {}关键字
sig将声明标识为Alloy signature。这引入了一组资源对象; 就像没有实例变量的类的对象一样,作为具有身份但没有内容的blob。当分析运行时,确定该集合,正如面向对象语言中的类在程序执行时表示对象时一样。资源由URL(uniform resource locators)命名:
sig Url { protocol: Protocol, host: Domain, port: lone Port, path: Path } sig Protocol, Port, Path {} sig Domain { subsumes: set Domain }这里我们有五个签名声明,为每个基本类型的对象引入一组URL和四个附加集合。URL声明有四个字段。字段与类中的实例变量类似;例如,如果’u’是一个URL,那么’u.protocol’将表示该URL的协议(就像Java中的点)。但事实上,我们稍后会看到,这些字段是相关的。你可以将每个人都想像为两列数据库表。因此
protocol是一个第一列包含URL,第二列包含协议的表。而无害的点操作符实际上是一般的关系连接,所以可以使用协议p编写protocol.p。请注意,与URL不同的路径被视为没有结构 ——简化。关键字
lone(可以读取“小于等于1”)表示每个URL最多只有一个端口。路径是跟随URL中主机名的字符串,(对于简单的静态服务器)对应于资源的文件路径;我们假设它总是存在,但可以是为空。介绍客户端和服务器,每个客户端和服务器都包含从路径到资源的映射:
abstract sig Endpoint {} abstract sig Client extends Endpoint {} abstract sig Server extends Endpoint { resources: Path -> lone Resource }关键字
extend引入了一个子集,所以所有客户端的’Client’集都是所有结点的’Endpoint’集合的子集。扩展是不相交的,所以任何端点都不是客户端和服务器。关键字abstract,一个签名的所有扩展都会耗尽它,所以它在Endpoint声明中的出现说明每个端点必须属于其中一个子集(此时是客户端和服务器)。对于服务器,表达式s.resources将表示从路径到资源(因此声明中的箭头)的映射。回想一下,每个字段实际上是一个包含签名作为第一列的关系,因此该字段表示Server,Path和Resource的三列关系。要将URL映射到服务器,我们引入一组域名服务器,每个域具有从域到服务器的映射:
one sig Dns { map: Domain -> Server }签名声明中的关键字’
one‘意味着,我们将假定只有一个域名服务器,并且有一个由表达式Dns.map给出的单一的DNS映射。与服务资源一样,这可能是动态的(事实上,已知的安全攻击依赖于交互期间更改DNS绑定),但我们正在简化。为了建模HTTP请求,我们还需要cookies的概念,所以让我们来声明一下:
sig Cookie { domains: set Domain }每个cookie的范围是一组域名; 这就捕获了一个cookie可以应用于
* .mit.edu这个事实,它将包括所有具有后缀mit.edu的域。最后,我们可以将它们放在一起构建一个HTTP请求的模型:
abstract sig HttpRequest extends Call { url: Url, sentCookies: set Cookie, body: lone Resource, receivedCookies: set Cookie, response: lone Resource, }{ from in Client to in Dns.map[url.host] }我们正在对单个对象中的HTTP请求和响应进行建模;
url,sentCookies和body由客户端发送,并且服务器发回receivedCookies和response。当编写
HttpRequest签名时,我们发现它包含调用的通用特性,即它们来自特定的东西。所以我们实际上写了一个声明Call签名的小 Alloy module,在这里我们需要导入它:open call[Endpoint]它是一个多态模块,所以它被实例化为
Endpoint,这些集合调用from和to。(该模块完整内容在 Appendix: Reusing Modules in Alloy)遵循
HttpRequest中的字段声明是约束的集合。这些约束中的每个都适用于HTTP请求集合中的所有成员。约束条件是:(1)每个请求都来自一个客户端,(2)每个请求被发送到由DNS主机根据DNS映射指定的服务器。Alloy的一个突出特点是可以随时执行一个模型,无论多么简单或复杂,以生成示例系统实例。让我们使用
run命令来询问Alloy Analyzer执行到目前为止的HTTP模型:run {} for 3 -- generate an instance with up to 3 objects of every signature type一旦分析器发现系统的可能实例,它就会自动生成一个实例图,如图17.1所示。
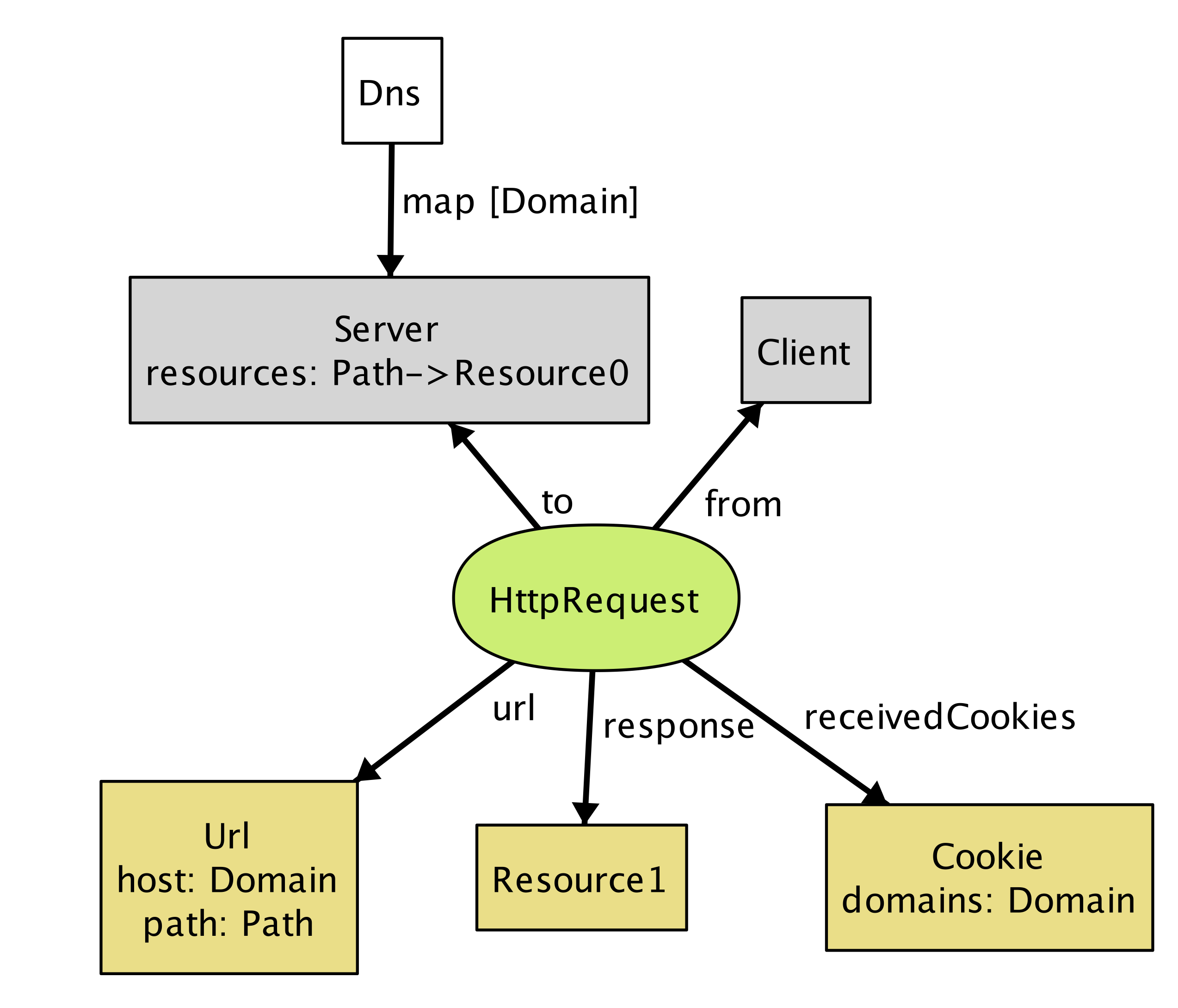
该实例显示一个客户端(由节点客户端表示)向
Server发送一个HttpRequest,作为响应,客户端返回资源对象并指示客户端存储Cookie在Domain。即使这是一个看似细节的小例子,它表明了我们的模型有一个缺陷。请注意,从请求返回的资源(
Resource1)在服务器中不存在。 我们忽略了一个关于服务器的明显事实; 即,对请求的每个响应都是服务器存储的资源。 我们可以回到我们对HttpRequest的定义,并添加一个约束:abstract sig HttpRequest extends Call { ... }{ ... response = to.resources[url.path] }重新运行现在产生没有缺陷的实例。
不是生成样本实例,我们可以要求分析器检查模型是否满足属性。例如,我们需要的属性是当客户端多次发送相同的请求时,它总是收到相同的响应:
check { all r1, r2: HttpRequest | r1.url = r2.url implies r1.response = r2.response } for 3给定
check命令,分析器会探测系统的所有可能的行为(直到指定的边界),并且当它找到违反该属性的行为时,将该实例显示为反例,如图17.2和图17.3所示。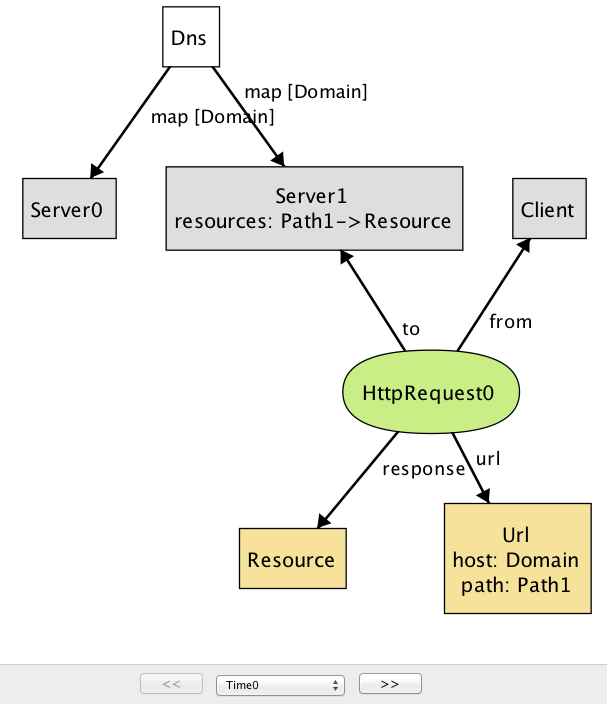
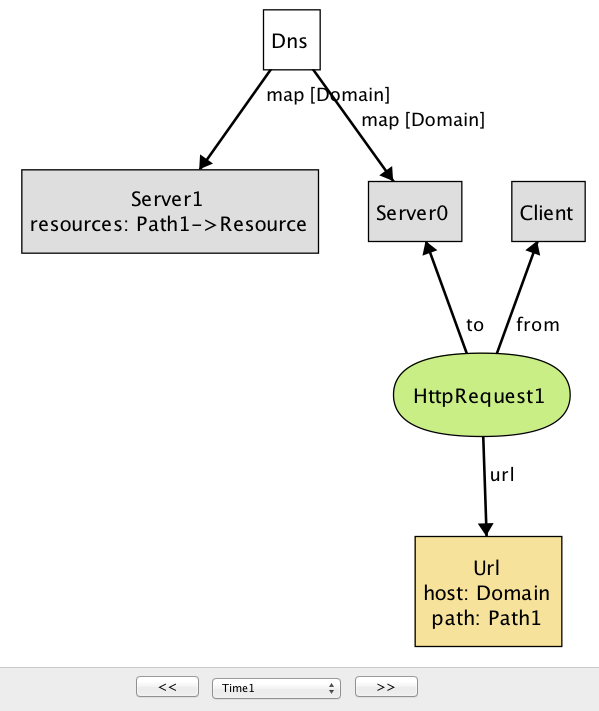
这个反例再次显示了客户端发出的HTTP请求,但是使用了两个不同的服务器。(在 Alloy visualizer中,相同类型的对象通过将数字后缀附加其名称来区分;如果只有一个给定类型的对象,则不添加任何后缀。快照图中出现的每个名称都是一个对象,所以或许可以令人困惑的,
Domain,Path,Resource,Url都是指单个对象,而不是类型。)请注意,虽然DNS将
Domain映射到Server0和Server1(实际上,这是负载平衡的常见做法),但只有Server1映射资源对象的Path,导致HttpRequest1导致空的响应:这是模型中的另一个错误。为了解决这个问题,我们添加了一个Alloy事实记录,DNS映射单个主机的任何两个服务器提供了相同的资源集合:fact ServerAssumption { all s1, s2: Server | (some Dns.map.s1 & Dns.map.s2) implies s1.resources = s2.resources }当我们在添加这个事实之后重新运行
check命令时,分析器不再报告该属性的任何反例。这并不意味着该属性已被证明是真实的,因为在更大的范围内可能有一个反例。但是,由于分析器已经测试了涉及每种类型的3个对象的所有可能的实例,所以属性不太可能是错误的。如果需要,我们可以重新进行更大的分析,以增加信心。例如,使用范围为10的上述检查仍然不产生任何反例,表明该属性是有效的。但是,请记住,由于分析仪范围较大,所以分析仪需要测试更多的实例,因此可能需要更长时间才能完成。
浏览器
现在我们将浏览器介绍到我们的模型中:
sig Browser extends Client { documents: Document -> Time, cookies: Cookie -> Time, }这是我们用动态字段签名的第一个例子。Alloy没有内在的时间或行为的概念。在这个模型中,我们使用一个常用的
Time概念,并将其作为每个时变字段的最终列。例如,表达式b.cookies.t表示在特定时间t存储在浏览器b中的一组Cookie。同样,documents字段在给定时间将一组文档与每个浏览器相关联。(有关我们如何模拟动态行为的更多详细信息,请参阅附录:Appendix: Reusing Modules in Alloy]。)文档是从响应HTTP请求创建的。如果用户关闭选项卡或浏览器,我们将其退出模型,也可能会被破坏。一个文件有一个URL(源自该文档的URL),一些内容(DOM)和一个域:
sig Document { src: Url, content: Resource -> Time, domain: Domain -> Time }在后两个字段中
Timer列可以告诉我们,它们可以随着时间而变化,并且省略第一个(src,表示文档的源URL)表示源URL是固定的。为了建模一个HTTP请求对浏览器的影响,我们引入一个新的签名,因为并不是所有的HTTP请求都将发生在浏览器; 其余的将来自脚本。
sig BrowserHttpRequest extends HttpRequest { doc: Document }{ -- the request comes from a browser from in Browser -- the cookies being sent exist in the browser at the time of the request sentCookies in from.cookies.start -- every cookie sent must be scoped to the url of the request all c: sentCookies | url.host in c.domains -- a new document is created to display the content of the response documents.end = documents.start + from -> doc -- the new document has the response as its contents content.end = content.start ++ doc -> response -- the new document has the host of the url as its domain domain.end = domain.start ++ doc -> url.host -- the document's source field is the url of the request doc.src = url -- new cookies are stored by the browser cookies.end = cookies.start + from -> sentCookies }这种请求有一个新的字段
doc,表示从请求返回的资源在浏览器中创建的文档。与·HttpRequest·一样,行为被描述为约束的集合。其中一些可能发生:例如,调用必须来自浏览器。一些约束调用的参数:例如,cookie必须适当地作用域。一些约束使用一个共同词,将一个关系的值与调用之后的值相关联。例如,要了解约束
documents.end=documents.start + from - > doc,documents是浏览器,文档和时间的3列关系。start和end的领域来自Call声明,并且表示呼叫开始和结束时的时间。表达式document.end在调用结束时给出从浏览器到文档的映射。所以这个约束,在调用之后,映射不变,除了表格映射from到doc。一些约束使用
++关系覆盖运算符:e1 ++ e2包含e2的所有元组,此外,e1中的任何元组是e1的第一个元素不是e2中的元组的第一个元素。例如,约束content.end = content.start ++ doc -> response,在调用之后,context映射将被更新映射doc到response(覆盖任何以前的doc的映射)。如果我们要使用联合运算符+,则相同的文档可能(不正确地)映射到后面的状态下的多个资源。脚本
接下来,我们将在HTTP和浏览器模型的基础上引入客户端脚本,其代表在浏览器文档(
context)中执行的代码段(通常为JavaScript)。sig Script extends Client { context: Document }脚本是一个动态实体,可执行两种不同的动作:(1)它可以进行HTTP请求(例如Ajax请求),(2)它可以使用浏览器来操作文档的内容和属性。客户端脚本的灵活性是Web 2.0快速发展的主要催化剂之一,也是创建SOP的原因之一。没有SOP,脚本会向服务器发送任意请求,或者自由修改浏览器内的文档 —— 如果一个或多个脚本变成恶意软件,这将是坏消息。
脚本可以通过发送
XmlHttpRequest来与服务器进行通信:sig XmlHttpRequest extends HttpRequest {}{ from in Script noBrowserChange[start, end] and noDocumentChange[start, end] }脚本使用
XmlHttpRequest向/从服务器发送/接收资源,但与BrowserHttpRequest不同,它不会立即为浏览器及其文档创建新页面或做其他更改。要说不会修改系统的调用,我们定义谓词noBrowserChange和noDocumentChange:pred noBrowserChange[start, end: Time] { documents.end = documents.start and cookies.end = cookies.start } pred noDocumentChange[start, end: Time] { content.end = content.start and domain.end = domain.start }脚本在文档上执行什么操作?首先,我们引入浏览器操作的通用概念来表示可以由脚本调用的浏览器API函数:
abstract sig BrowserOp extends Call { doc: Document }{ from in Script and to in Browser doc + from.context in to.documents.start noBrowserChange[start, end] }字段
doc是指将被该调用访问或操作的文档。签名中的第二个约束是,doc和脚本执行的文档(from.context)都必须是浏览器当前存在的文档。最后,BrowserOp可以修改文档的状态,但不能修改存储在浏览器中的一组文档或Cookie。 (实际上,Cookie与文档相关联,并使用浏览器API进行修改,但现在我们略去这个细节。)脚本读取和写入文档的各个部分(通常称为DOM元素)。在典型的浏览器中,有许多用于访问DOM的API函数(如
document.getElementById),但重点不在于枚举。相反,我们将简单地将它们分为两种:ReadDom和WriteDom—— 以及模型修改,批量替换整个文档:sig ReadDom extends BrowserOp { result: Resource }{ result = doc.content.start noDocumentChange[start, end] } sig WriteDom extends BrowserOp { newDom: Resource }{ content.end = content.start ++ doc -> newDom domain.end = domain.start }ReadDom返回目标文档的内容,但不修改它;另一方面,WriteDom将目标文档的新内容设置为newDom。此外,脚本可以修改文档的各种属性,例如其宽度,高度,域和标题。对于我们对SOP的讨论,我们只对域属性感兴趣,在后面的部分中介绍。
应用程序例子
如上所述,给定
run或check命令,Alloy Analyzer生成与模型中系统描述一致的方案(如果存在)。默认情况下,分析器可以任意选择任意可能的系统场景(直到指定的边界),并在场景中为签名实例(Server0,Browser1等)分配数字标识符。有时,我们希望分析特定Web应用程序的行为,而不是通过随机配置服务器和客户端来探索场景。例如,假设我们想要构建一个在浏览器中运行的电子邮件应用程序(如Gmail)。除了提供基本的电子邮件功能外,我们的应用程序可能会显示来自第三方广告服务的横幅,该广告服务由潜在的恶意角色控制。
在Alloy中,关键词
one sig引入只包含一个对象的单例签名;我们在上面看到了Dns的一个例子。这个语法用来指定具体的原子。例如,要一个收件箱页面和一个广告横幅(每个都是一个文档),我们可以写:one sig InboxPage, AdBanner extends Document {}声明钟,Alloy生成的场景都包含至少两个
Document对象。同样,我们可以指定特定的服务器,域等,并附加一个约束(
Configuration)来指定它们之间的关系:one sig EmailServer, EvilServer extends Server {} one sig EvilScript extends Script {} one sig EmailDomain, EvilDomain extends Domain {} fact Configuration { EvilScript.context = AdBanner InboxPage.domain.first = EmailDomain AdBanner.domain.first = EvilDomain Dns.map = EmailDomain -> EmailServer + EvilDomain -> EvilServer }例如,最后一个约束规定了如何配置DNS来映射系统中两台服务器的域名。没有这个约束,Alloy Analyzer可能会生成场景
EmailDomain被映射到EvilServer,我们并不感兴趣。(实际上,由于DNS欺骗的攻击,这种映射是可能的,但是我们将从模型中排除它,因为它不在SOP防止的攻击类之外。)我们再介绍两个额外的应用程序:一个在线日历和一个博客站点:
one sig CalendarServer, BlogServer extends Document {} one sig CalendarDomain, BlogDomain extends Domain {}我们应该更新上面的DNS映射的约束以合并这两个服务器的域名:
fact Configuration { ... Dns.map = EmailDomain -> EmailServer + EvilDomain -> EvilServer + CalendarDomain -> CalendarServer + BlogDomain -> BlogServer }此外,电子邮件,博客和日历应用程序都是由单个组织开发的,因此共享相同的基础域名。概念上,
EmailServer和CalendarServer具有子域名电子邮件和日历,将example.com分享共同的超级域名。在我们的模型中,可以通过引入包含其他人的域名来表示:one sig ExampleDomain extends Domain {}{ subsumes = EmailDomain + EvilDomain + CalendarDomain + this }注意,
subsumes的成员包含this,因为每个域名都包含自身。还有关于我们在这里省略的这些应用程序的其他细节(请参阅完整版
example.als)。但是,我们在本章的其余部分重新审视这些应用程序作为示例。安全属性
在进入SOP之前,我们还没有讨论一个重要的问题:当我们说我们的系统是安全的时候是什么意思?
毫无疑问,这是一个棘手的问题。我们将转向信息安全 - 机密性和完整性两个深入研究的概念。这两个概念都是谈论如何允许信息通过系统的各个部分。大致来说,机密性意味着只有对被认为可信任的部分才能访问关键的数据,而完整性意味着信任的部分只能依赖于没有被恶意篡改的数据。
数据流属性
为了更精确地指定这些安全属性,我们首先需要定义从系统的一部分流向另一部分的数据的意义。模型中,我们已经描述了两个端点之间的通过通话进行的交互;例如,浏览器通过HTTP请求与服务器交互,脚本通过调用浏览器API操作与浏览器交互。直观地,在每个呼叫期间,一条数据可以作为呼叫的参数或返回值从一个端点流向另一端点。为了表示这一点,我们将
DataflowCall的概念引入模型,并将每个调用与一组参数关联并返回数据字段:sig Data in Resource + Cookie {} sig DataflowCall in Call { args, returns: set Data, --- arguments and return data of this call }{ this in HttpRequest implies args = this.sentCookies + this.body and returns = this.receivedCookies + this.response ... }例如,在
HttpRequest的每次调用期间,客户端将sentCookies和body传输到服务器,并接收receivedCookies和response作为返回值。更一般地,参数从调用的发送者流向接收者,返回值是从接收者到发送者的流。这意味着端点访问新数据的唯一方法是接收作为端点接受的调用参数或端点调用的返回值。我们引入
DataflowModule的概念,并分配字段访问来表示在每个时间步长模块可以访问的数据元素集合:sig DataflowModule in Endpoint { -- Set of data that this component initially owns accesses: Data -> Time }{ all d: Data, t: Time - first | -- This endpoint can only access a piece of data "d" at time "t" only when d -> t in accesses implies -- (1) It already had access in the previous time step, or d -> t.prev in accesses or -- there is some call "c" that ended at "t" such that some c: Call & end.t | -- (2) the endpoint receives "c" that carries "d" as one of its arguments or c.to = this and d in c.args or -- (3) the endpoint sends "c" that returns "d" c.from = this and d in c.returns }我们还需要限制模块可以提供的数据元素作为参数或返回值。否则,我们可能会遇到奇怪的情况,一个模块可以使用无法访问的参数进行调用。
sig DataflowCall in Call { ... } { -- (1) Any arguments must be accessible to the sender args in from.accesses.start -- (2) Any data returned from this call must be accessible to the receiver returns in to.accesses.start }现在我们描述系统不同部分之间的数据流,说明我们关心的安全属性。但是请记住,机密性和完整性是好情绪相关的概念; 这些属性只有在我们可以将系统中的某些代理人视为受信任(或恶意)的情况下才有意义。同样,并不是所有的信息都重要:我们需要区分我们认为是关键或恶意的数据元素(或两者):
sig TrustedModule, MaliciousModule in DataflowModule {} sig CriticalData, MaliciousData in Data {}机密属性是关键数据流入系统不可信部分:
// No malicious module should be able to access critical data assert Confidentiality { no m: Module - TrustedModule, t: Time | some CriticalData & m.accesses.t }诚信属性是保密性的双重性:
// No malicious data should ever flow into a trusted module assert Integrity { no m: TrustedModule, t: Time | some MaliciousData & m.accesses.t }Threat Model
威胁模型描述了攻击者可能执行的以试图破坏系统的安全属性的一组操作。构建威胁模型是安全系统设计中重要的一步;它允许我们识别我们关于系统及其环境的假设,并优先考虑需要减轻的不同类型的风险。
在我们的模型中,我们考虑可以充当服务器,脚本或客户端的攻击者。作为服务器,攻击者可能会设置恶意网页,以征求不知情用户的访问权限,而这些访问者又可能会无意中向攻击者发送敏感信息作为HTTP请求的一部分。攻击者可能会创建一个恶意脚本,调用DOM操作从其他页面读取数据,并将这些数据中继到攻击者的服务器。最后,作为一个客户端,攻击者可以冒充普通用户,并向服务器发送恶意请求,以尝试访问用户的数据。我们不认为攻击者窃取不同网络端点之间的连接;虽然在实践中是一个威胁,但是SOP并不是为了防止它而设计,因此它不在我们模型的范围之内。
检查属性
现在我们已经定义了安全属性和攻击者的行为,让我们展示如何使用Alloy Analyzer来自动检查这些属性,即使存在攻击者。当使用检查命令提示时,分析器会探测系统中所有可能的数据流跟踪,并生成一个反例(如果存在),演示如何违反:
check Confidentiality for 5例如,根据机密属性检查示例应用程序的模型时,分析器将生成图17.4和图17.5中的方案,它显示了
EvilScript如何访问关键数据(MyInboxInfo)。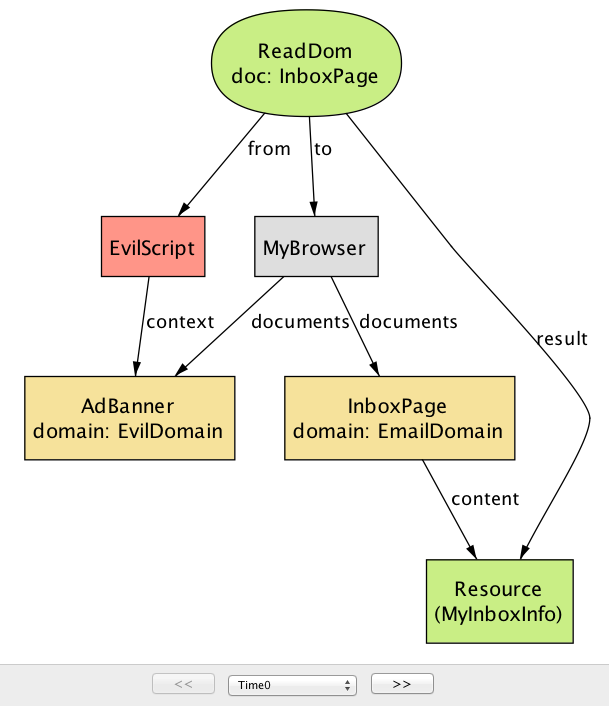
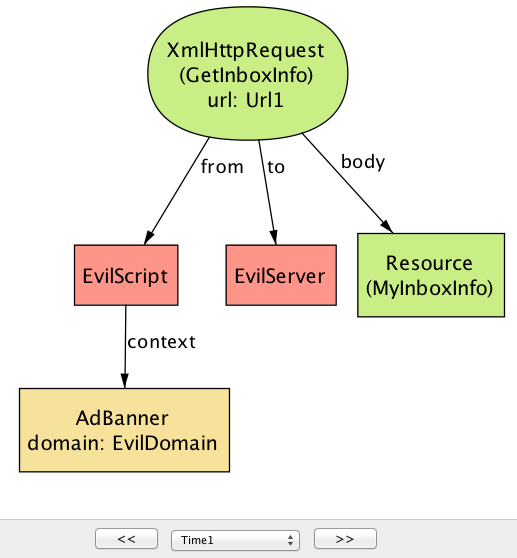
这个反例有两个步骤。第一步(图17.4)中,
EvilScript从EvilDomain在AdBanner内部执行,读取来自EmailDomain的InboxPage内容。第二步(图17.5)中,EvilScript通过进行调用XmlHtttpRequest向EmilServer发送相同的内容(MyInboxInfo)。这里的核心问题是,在一个域下执行的脚本能够从另一个域读取文档的内容; 正如我们将在下一节中看到的,这正是SOP旨在防止的情景之一。单个assertion可能有多个反例。图17.6,显示了系统可能违反机密性质的不同方式。
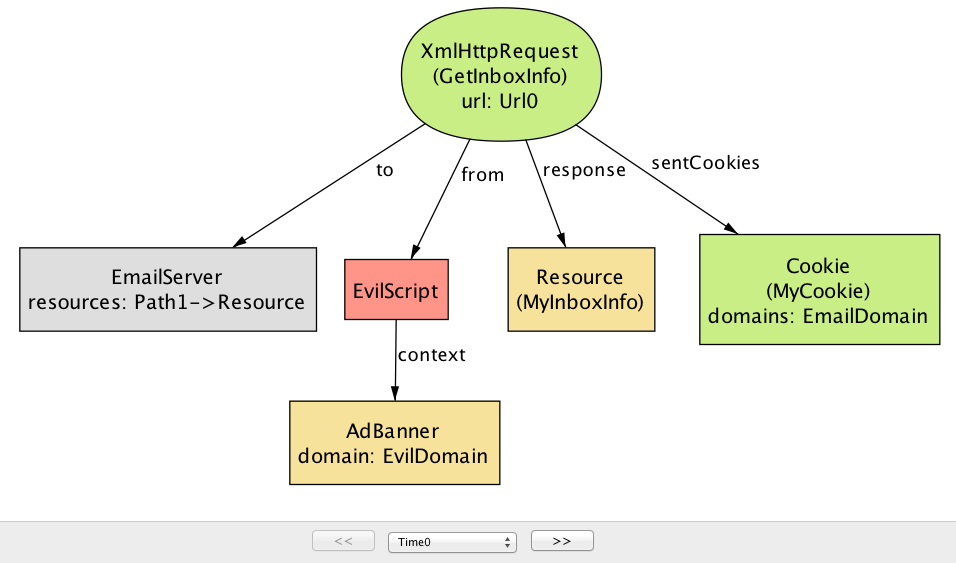
在这个场景下,
EvilScript不是阅读收件箱页面的内容,而是直接向EmailServer发送GetInboxInfo请求。请注意,该请求包括一个cookie(MyCookie),该cookie是作用于与目标服务器相同的域。这是危险的,因为如果cookie表示用户的身份(例如,会话cookie),则vilScript可以有效地伪装成用户,并欺骗服务器响应用户的私有数据(MyInboxInfo)。问题再次与脚本可用于访问跨不同域的信息的自由方式相关,即,在一个域下执行的脚本能够向具有不同域的服务器发出HTTP请求。这两个反例告诉我们,需要额外的措施来限制脚本的行为,特别是其中一些脚本可能是恶意的。这正是SOP进入的地方。
同源政策
在我们说明SOP之前,首先要介绍源代码的概念,它由协议,主机和可选端口组成:
sig Origin { protocol: Protocol, host: Domain, port: lone Port }为方便起见,我们定义一个函数,给定一个URL,返回相应的来源:
fun origin[u: Url] : Origin { {o: Origin | o.protocol = u.protocol and o.host = u.host and o.port = u.port } }SOP有两个部分,限制脚本的能力(1)进行DOM API调用,(2)发送HTTP请求。 策略的第一部分指出,脚本只能读取和写入与脚本相同来源的文档:
fact domSop { all o: ReadDom + WriteDom | let target = o.doc, caller = o.from.context | origin[target] = origin[caller] }我们可以看到,SOP旨在防止由恶意脚本引起的两种类型的漏洞;没有它,网络将更危险。
然而事实证明,SOP太受限制了。例如,有时你希望允许不同来源的两个文档之间的通信。通过上述源代码定义,
foo.example.com的脚本将无法读取bar.example.com的内容,或向www.example.com发送HTTP请求,因为这些都被视为不同的主机。为了在必要时允许某种形式的跨源通信,浏览器实现了放松SOP的各种机制。其中一些比其他更为深思熟虑,有些则陷入困境,如果使用不当,可能会破坏SOP的安全利益。下面我们将介绍最常见的机制,并讨论其潜在的安全隐患。
绕过SOP的技术
SOP是功能和安全之间紧张关系的典型例子;我们想确保网站健壮和功能齐全,但是有时会妨碍其安全的机制。实际上,当SOP最初被引入时,开发人员遇到了构建跨域通信(例如mashup)合法使用的站点的麻烦。
在本节中,我们将讨论Web开发人员设计经常使用的四种技术,以绕过SOP规定的限制:(1)
document.domain; (2)JSONP; (3)邮寄;和(4)CORS。这些是有价值的工具,但是如果使用时不小心,可能会使Web应用程序容易让SOP受到各种攻击。四项技术的每种都是很复杂的,如果充分详细描述,需要一章。所以在这里我们只是给出一个简短的印象,说明它们如何工作,潜在的安全问题,以及如何防止这些问题。特别是,我们要求 Alloy Analyzer检查每种技术是否被攻击者滥,破了坏我们之前定义的两个安全属性:
check Confidentiality for 5 check Integrity for 5基于分析仪生成的反例,我们将讨论安全使用这些技术的准则,防止陷入安全隐患。
域属性
作为我们列表中的第一种技术,我们使用
document.domain属性绕过SOP。这种技术背后的思想是允许不同来源的两个文档通过将document.domain属性设置为相同值来访问对方的DOM。因此,例如,如果两个文档中的脚本将document.domain属性设置为example.com(假设两个都有源URL,则email_example.com的脚本可以从calendar.example.com读取或写入文档,DOM 也是相同的协议和端口)。我们将
document.domain属性设置为SetDomain的浏览器操作类型的行为:// Modify the document.domain property sig SetDomain extends BrowserOp { newDomain: Domain }{ doc = from.context domain.end = domain.start ++ doc -> newDomain -- no change to the content of the document content.end = content.start }newDomain字段表示属性应该设置的值。cunz 一个警告:脚本只能将域属性设置为其主机名的右侧,完全限定的片段。(即,email.example.com可以将其设置为example.com而不是google.com)我们使用事实来获取子域的这个规则:// Scripts can only set the domain property to only one that is a right-hand, // fully-qualified fragment of its hostname fact setDomainRule { all d: Document | d.src.host in (d.domain.Time).subsumes }如果不符合此规则,任何网站都可以将
document.domain属性设置为任何值,这意味着,恶意网站可以将域属性设置为您的银行域,将您的银行帐户加载到iframe中,和(假设银行页面已设置其域属性)读取你的银行页面的DOM。我们回到原来的SOP定义,放宽对DOM访问的限制,以便考虑到
document.domain属性的影响。如果两个脚本将属性设置为相同的值,并且它们具有相同的协议和端口,则这两个脚本可以彼此交互(即,读取和写入对方的DOM)。fact domSop { -- For every successful read/write DOM operation, all o: ReadDom + WriteDom | let target = o.doc, caller = o.from.context | -- (1) target and caller documents are from the same origin, or origin[target] = origin[caller] or -- (2) domain properties of both documents have been modified (target + caller in (o.prevs <: SetDomain).doc and -- ...and they have matching origin values. currOrigin[target, o.start] = currOrigin[caller, o.start]) }currOrigin[d, t]是一个返回文档d起始位置的函数,document.domain是在时间t的主机名。值得指出的是,这两个文档的
document.domain属性必须在加载浏览器后明确设置。文档A从example.com加载,文档B从calendar.example.com将其域属性修改为example.com。即使这两个文件现在具有相同的域属性,则无法相互交互,除非文档A将其属性设置为example.com。起初,这似乎是一个奇怪的行为。但是,如果没有发生各种不利的事情。例如,网站可能会受到其子域的跨站点脚本攻击:文档B中的恶意脚本可能将其域属性修改为example.com并操纵文档A的DOM,即使后者从不打算进行与文件B交互。分析:现在我们已经放宽了SOP,允许在某些情况下进行跨原籍交流,SOP的安全是否仍然保障?Alloy Analyzer告诉我们,是否可以让攻击者滥用
document.domain属性来访问或篡改用户的敏感数据。实际上,考虑到SOP的新的简单的定义,分析器会为机密性产生一个反例场景:
check Confidentiality for 5这种情况包括五个步骤;前三个步骤显示了
document.domain的典型用法,其中来自不同来源的两个文档CalendarPage和InboxPage通过将其域属性设置为共同值来进行通信(ExampleDomain)。最后两个步骤引入BlogPage文档,该文档已被恶意脚本妥协,该脚本会尝试访问其他两个文档的内容。在场景开始时(图17.7和图17.8),
InboxPage和CalendarPage有两个不同值(分别为EmailDomain和ExampleDomain)的域属性,因此浏览器将阻止它们访问彼此的DOM。在文档(InboxScript和CalendarScript)中运行的脚本都执行SetDomain操作,以将其域属性修改为ExampleDomain(由于ExampleDomain是原始域的超级域),所以它可以被允许。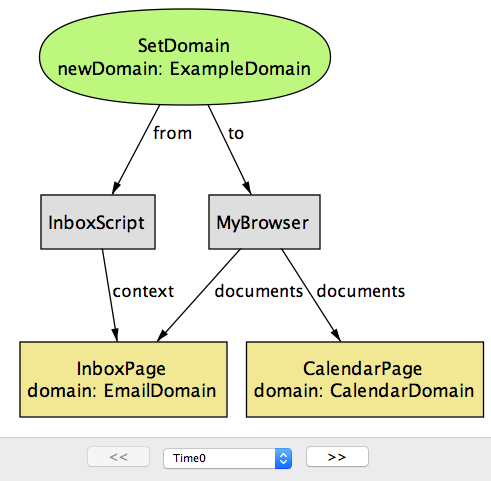
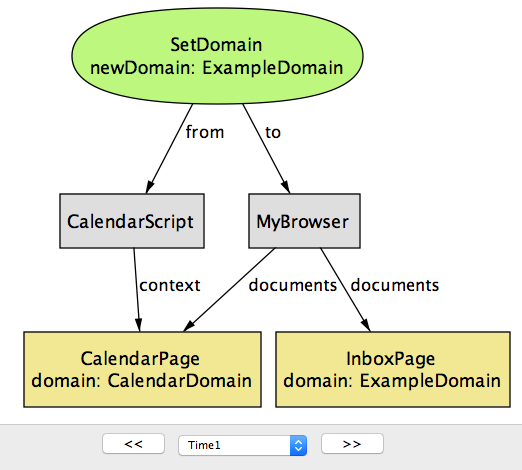
完成此操作后,现在可以通过执行
ReadDom或WriteDom操作来访问对方的DOM,如图17.9所示。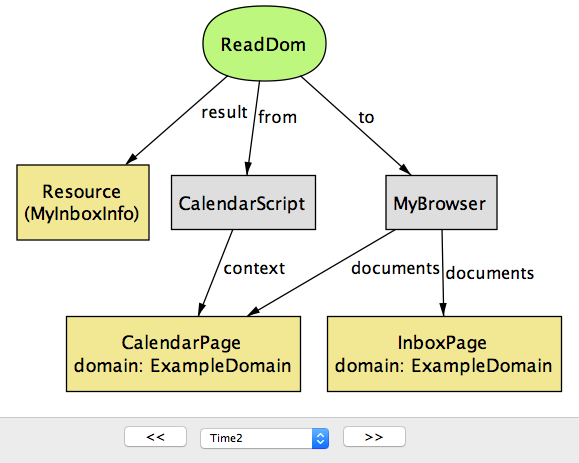
请注意,当你将
email.example.com和calendar.example.com的域设置为example.com时,不仅允许这两个页面在彼此之间进行通信,还允许具有example.com的任何其他页面作为 超域(例如blog.example.com)。攻击者也意识到这一点,并构建了一个在攻击者博客页面(BlogPage)内运行的特殊脚本(EvilScript)。下一步(图17.10)中,脚本执行SetDomain操作,将BlogPage的domain属性修改为ExampleDomain。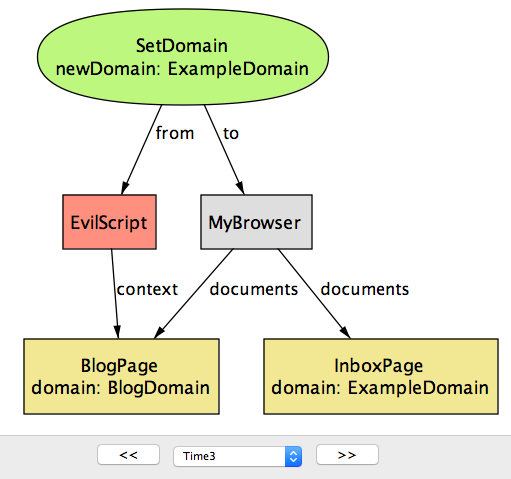
现在
BlogPage与其他两个文档具有相同的域属性,可以成功执行ReadDOM操作来访问其内容(图17.11。)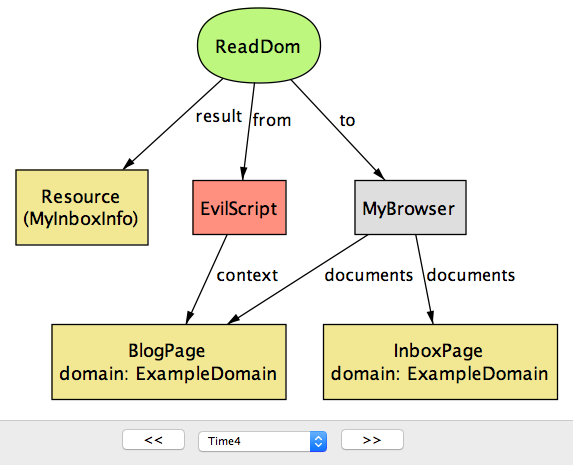
这种攻击指出了跨原始通信的域属性方法的一个关键弱点:使用此方法的应用程序的安全性与所有共享相同基础域的页面中最薄弱的链接一样强大。我们将尽快讨论另一种称为
PostMessage的方法,它可以用于更一般的跨原始通信类,同时也更安全。JSON with Padding (JSONP)
在引入CORS之前,JSONP可能是绕过
XMLHttpRequest的SOP限制最流行的技术,如今仍然被广泛使用。JSONP利用HTML中的脚本包含标记(如<script>)免于SOP*; 也就是说,你可以从任何URL中包含脚本,浏览器可以在当前文档中轻松执行:(*没有这种豁免,不可能从其他域加载JavaScript库,如JQuery)。
<script src="http://www.example.com/myscript.js"></script>可以使用脚本标签来获取代码,但是如何使用它从不同的域接收任意数据(如JSON对象)?问题是浏览器期望
src的内容是一段JavaScript代码,因此简单地将其指向数据源(如JSON或HTML文件)会导致语法错误。一种解决方法是将浏览器识别为字符串的所需数据包装为有效的JavaScript代码;这个字符串称为填充(名为“JSON with padding”)。这个填充可以是任何任意的JavaScript代码,但是通常来说,它是在响应数据上执行的回调函数的名称:
<script src="http://www.example.com/mydata?jsonp=processData"></script>www.example.com上的服务器将其识别为JSONP请求,并将请求的数据包装在jsonp参数中:processData(mydata)这是一个有效的JavaScript语句(即在“mydata”上应用函数“processData”),并由当前文档的浏览器执行。
在我们的模型中,JSONP被建模为一种HTTP请求,其包括字段
padding中的回调函数的标识符。在收到JSONP请求后,服务器返回一个包含回调函数(cb)内部请求的资源(有效载荷)的响应。sig CallbackID {} // identifier of a callback function // Request sent as a result of <script> tag sig JsonpRequest in BrowserHttpRequest { padding: CallbackID }{ response in JsonpResponse } sig JsonpResponse in Resource { cb: CallbackID, payload: Resource }当浏览器收到响应时,它会在有效载荷上执行回调函数:
sig JsonpCallback extends EventHandler { cb: CallbackID, payload: Resource }{ causedBy in JsonpRequest let resp = causedBy.response | cb = resp.@cb and -- result of JSONP request is passed on as an argument to the callback payload = resp.@payload }(
EventHandler是一种特殊类型的调用,必须在另一个调用之后的某个时间进行,由causeBy表示;我们将使用事件处理程序来模拟脚本响应浏览器事件执行的操作。)请注意,执行的回调函数与响应中包含的回调函数(
cb = resp.@cb)相同,但不一定与原始JSONP请求中的padding相同。换句话说,为了使JSONP通信工作,服务器负责正确地构建包含原始填充作为回调函数的响应(如确保JsonRequest.padding = JsonpResponse.cb)。原则上,服务器可以选择包括任何回调函数(或任何JavaScript),包括与请求中padding无关的函数。这突出了JSONP的潜在风险:接受JSONP请求的服务器必须是可靠和安全的,因为它可以在客户端文档中执行任何JavaScript代码。分析:检查Alloy Analyzer的
Confidentiality属性返回一个反例,显示JSONP潜在安全风险。这种情况下,日历应用程序(CalendarServer)使用JSONP端点(GetSchedule)使其资源可用于第三方站点。要限制对资源的访问权限,如果请求包含正确标识该用户的cookie,则CalendarServer将仅向用户发回具有调度的响应。请注意,一旦服务器将HTTP端点提供为JSONP服务,任何人都可以提供JSONP请求,包括恶意站点。在这种情况下,
EvilServer的广告标题页面包含脚本标签,该脚本标签导致GetSchedule请求,并将回调函数称为padding的Leak。通常,AdBanner的开发人员无法直接访问CalendarServer的受害用户的会话cookie(MyCookie)。但是,由于JSONP请求被发送到CalendarServer,浏览器会自动将MyCookie作为请求的一部分;已收到与MyCookie的JSONP请求的CalendarServer将返回被包含在padding leak的受害者的资源(MySchedule)(图17.12)。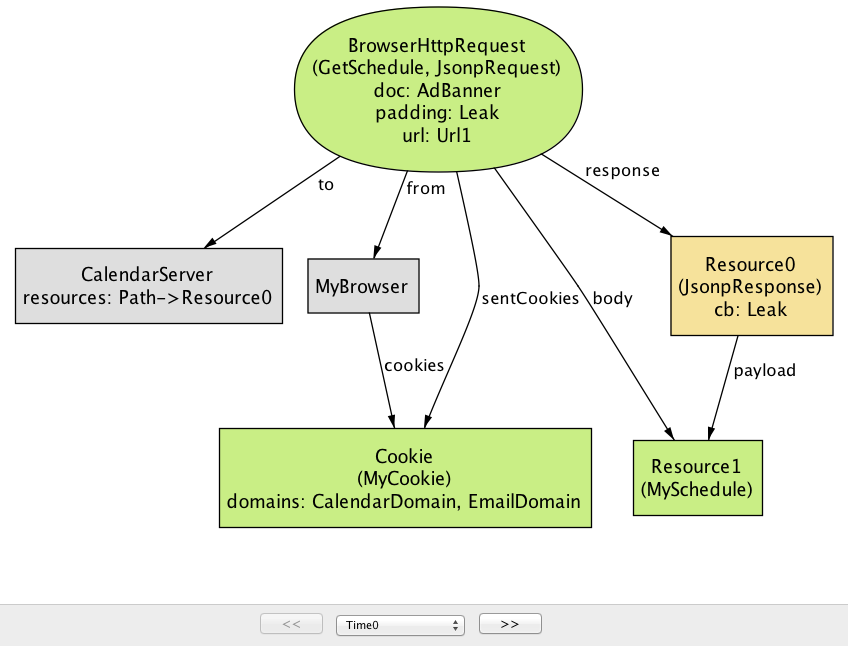
下一步中,浏览器将JSONP响应解释为对
Leak(MySchedule)的调用(图17.13)。 其余的攻击很简单;Leak可以简单地将输入参数转发到EvilServer,允许攻击者访问受害者的敏感信息。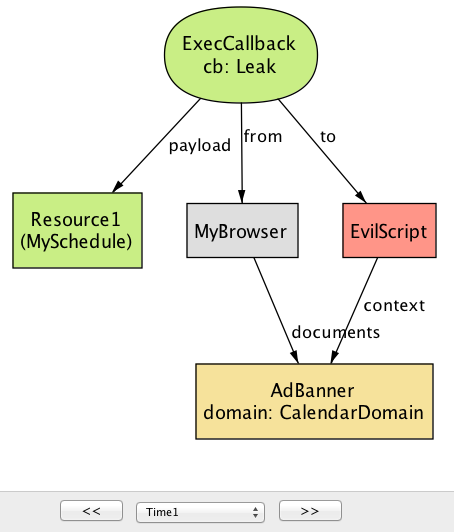
这种攻击是跨站点请求伪造(CSRF)的示例,显示了JSOPN的固有缺陷; 网站上的任何网站都可以通过添加
<script>标签并访问padding的有效内容来简单地制作JSONP请求。风险可以通过两种方式得到缓解:(1)确保JSONP请求不会返回敏感数据,或者(2)使用另一种机制代替cookie(例如秘密令牌)来授权请求。PostMessage
PostMessage是HTML5中的新功能,允许来自两个文档(可能不同的来源)的脚本相互通信。它为设置
domain属性提供了更有条理的替代方法,但也带来了自身的安全隐患。PostMessage是一个浏览器API函数,它有两个参数:(1)要发送的数据(message)和(2)接收消息的文档的起源(targetOrigin):sig PostMessage extends BrowserOp { message: Resource, targetOrigin: Origin }要从另一个文档接收消息,接收文档将注册浏览器由于
PostMessage而调用的事件处理程序:sig ReceiveMessage extends EventHandler { data: Resource, srcOrigin: Origin }{ causedBy in PostMessage -- "ReceiveMessage" event is sent to the script with the correct context origin[to.context.src] = causedBy.targetOrigin -- messages match data = causedBy.@message -- the origin of the sender script is provided as "srcOrigin" param srcOrigin = origin[causedBy.@from.context.src] }浏览器将两个参数传递给
ReceiveMessage:与要发送的消息对应的资源(data)和发件人文档的起源(srcOrigin)。签名包含四个约束,以确保每个ReceiveMessage相对于其相应的PostMessage格式正确。分析:再次,询问Alloy Analyzer
PostMessage是否是一种执行跨原始通信的安全方式。这次,分析仪返回Integrity属性的反例,这意味着攻击者可以利用PostMessage中的弱点将恶意数据引入受信任的应用程序。请注意,默认情况下,
PostMessage机制不限制允许发送PostMessage的人员;换句话说,只要后者已经注册了一个ReceiveMessage处理程序,任何文档都可以发送消息到另一个文档。例如,在由Alloy生成的以下实例中,AdBanner中运行的EvilScript将恶意PostMessage发送到目标来源为EmailDomain的文档(图17.14)。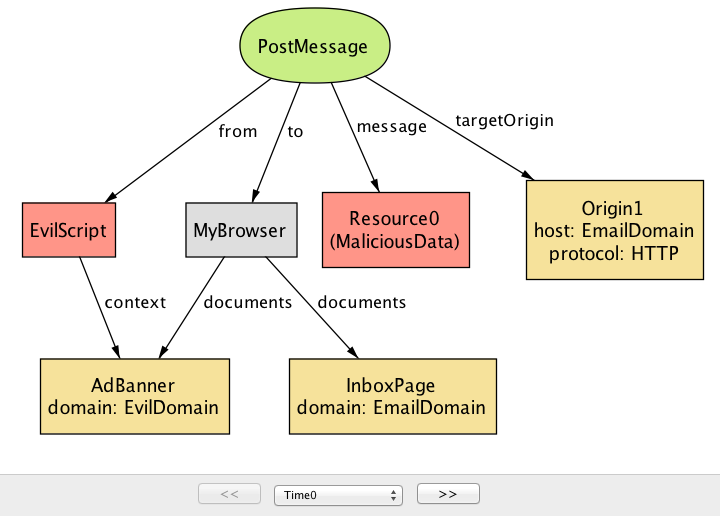
然后,浏览器将该消息转发到具有相应来源(在本例中为
InboxPage)的文档。除非InboxScript专门检查srcOrigin的值以过滤不需要的邮件,InboxPage将接受恶意数据,可能导致进一步的安全攻击。(例如,它可能嵌入一个JavaScript来执行XSS攻击)。如图17.14所示。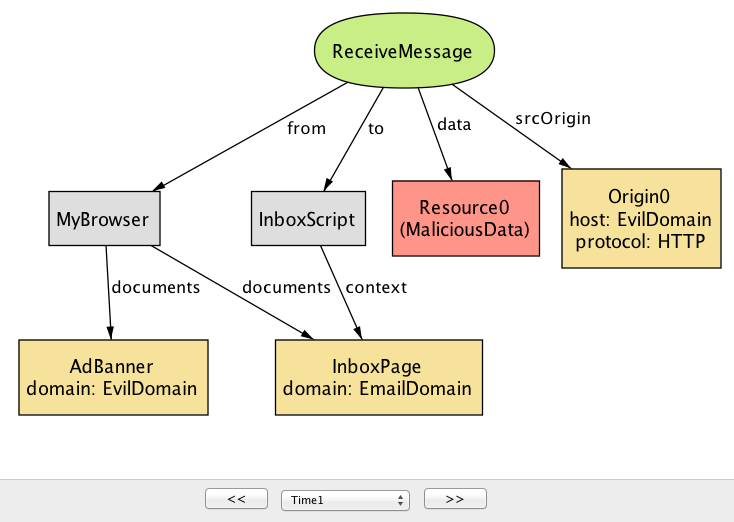
如此示例所示,默认情况下
PostMessage不安全,接收文档有责任另外检查srcOrigin参数,以确保该消息来自可信赖的文档。不幸的是,实践中许多站点都省略了这个检查,使恶意文件能够将不良内容注入PostMessage。然而,省略原始检查不仅仅是程序员无知的结果。对传入的
PostMessage执行适当的检查很棘手;在某些应用中,难以预先确定可接收消息的可信来源的列表。同样,这突出显示了安全性和功能性之间的紧张关系:PostMessage可用于安全的跨原始通信,但仅当已知可信来源的白名单时。Cross-Origin Resource Sharing (CORS)
CORS是一种允许服务器与来自不同来源的站点共享其资源的机制。特别地,CORS可以由来自一个来源的脚本用于向具有不同来源的服务器发出请求,有效地绕过了跨原始Ajax请求的SOP限制。
简单来说,典型的CORS过程包括两个步骤:(1)从外部服务器访问资源的脚本在其请求中包括指定脚本的起源的“Origin”,以及(2)服务器包括“Access-Control-Allow-Origin”标头作为其响应的一部分,指示允许访问服务器资源的一组源。通常,没有CORS,浏览器将阻止脚本首先发出符合SOP的跨原始请求。然而,启用CORS后,浏览器允许脚本发送请求并访问其响应,但只有当“Origin”是“Access-Control-Allow-Origin”中指定的源时才允许。
(除了GETs和POST之外,CORS还包括一个前瞻性请求概念,这里不讨论这些概念来支持复杂类型的跨原始请求。)
在Alloy中,我们将CORS请求建模为特殊的
XmlHttpRequest,其中有两个额外的字段origin和allowedOrigins:sig CorsRequest in XmlHttpRequest { -- "origin" header in request from client origin: Origin, -- "access-control-allow-origin" header in response from server allowedOrigins: set Origin }{ from in Script }然后我们使用一个Alloy fact
corsRule来描述是什么构成一个有效的CORS请求:fact corsRule { all r: CorsRequest | -- the origin header of a CORS request matches the script context r.origin = origin[r.from.context.src] and -- the specified origin is one of the allowed origins r.origin in r.allowedOrigins }分析:CORS可能会以允许攻击者破坏受信任站点的安全性的方式被误用? 出现提示时,Alloy Analyzer为
Confidentiality属性返回一个简单的反例。在这里,日历应用程序的开发人员决定通过使用CORS机制与其他应用程序共享一些资源。不幸的是,
CalendarServer被配置为返回CORS响应中的access-control-allow-origin头的Origin(它代表所有原始值的集合)。因此,允许任何来源的脚本(包括EvilDomain)向CalendarServer发出跨站点请求并读取其响应(图17.16)。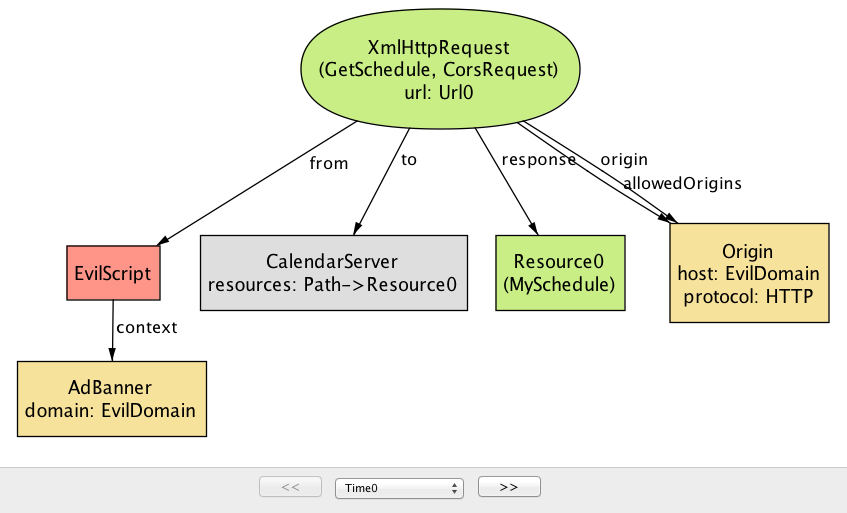
此示例突出了开发人员使用CORS的一个常见错误:使用通配符值“”作为“access-control-allow-origin”标头的值,允许任何站点访问服务器上的资源。如果资源是公开的,并且任何人都可以访问,则该访问模式是适当的。然而,事实证明,即使是私人资源,许多站点也使用“”作为默认值,无意中允许恶意脚本通过CORS请求访问它们。
为什么开发人员会使用通配符?事实证明,指定允许的来源可能是棘手的,因为在设计时可能不清楚哪个起始应该在运行时被授予访问权限(类似于上面提到的PostMessage问题)。例如,服务可以允许第三方应用程序动态地订阅其资源。
结论
在本章中,我们着手构建一个文档,通过以一种
Alloy语言构建模型,从而对SOP及其相关机制提供了清晰的了解。我们的SOP模型不是传统意义上的实现,不能像其他章节所示的工件一样部署使用。相反,我们想要展示我们的“agile modeling”方法背后的关键要素:(1)开始使用系统的小型抽象模型,并根据需要逐步添加细节,(2)指定系统预期的属性,(3)严格分析,探索系统设计中的潜在缺陷。当然,这一章是在SOP第一次引入之后写的很久,但是我们认为,如果在系统设计的早期阶段完成这种建模,这种类型的建模可能会更有益处。除了SOP之外,Alloy已被用于对不同领域的各种系统进行建模和推理,从网络协议,语义网,字节码安全到电子投票和医疗系统。对于这些系统,Alloy的分析发现设计缺陷和错误,在某些情况下,开发人员很早就发现了。我们邀请读者访问Alloy Page页面,并尝试构建自己喜欢的系统的模型!
引用
-
Sooel Son and Vitaly Shmatikov. The Postman Always Rings Twice: Attacking and Defending postMessage in HTML5 Websites. Network and Distributed System Security Symposium (NDSS), 2013.↩
-
Sebastian Lekies, Martin Johns, and Walter Tighzert. The State of the Cross-Domain Nation. Web 2.0 Security and Privacy (W2SP), 2011.↩
-
-
500 Lines or Less Chapter 19: Web Spreadsheet 翻译
Audrey是一名自学的程序员和翻译人员,与Apple合作,担任云服务本地化和自然语言技术的独立承包商。Audrey曾经设计和领导了Perl 6实施,并任职于Haskell,Perl 5和Perl 6的计算机语言设计。目前,Audrey是全职g0v贡献者,领导台湾首个电子规则制定项目。
本章介绍一个网页电子表格,由99个行的Web浏览器支持的三种语言编写:HTML,JavaScript和CSS。
该项目的ES5版本可作为jsFiddle。
(本章还有繁体中文)。
介绍
当Tim Berners-Lee在1990年发明了网络时,网页是用HTML编写的,标有带有角括号的标签的文本,为内容分配逻辑结构。标记在
<a>…</a>内的文本成为超链接,将用户引到网络上的其他页面。在20世纪90年代,浏览器向HTML词汇添加了各种演示标签,包括来自Netscape Navigator的
<blink>…</blink>和来自Internet Explorer的<marquee>…</marquee>等不好的标签,从而在可用性方面引起广泛的问题和浏览器兼容问题。为了将HTML限制到其原始目的 - 描述文档的逻辑结构 - 浏览器制造商最终同意支持两种其他语言:CSS来描述页面的演示风格,以及JavaScript(JS)来描述其动态交互。
从那时起,三种语言二十年来变得更加简洁和强大。特别是,JS引擎的改进使其部署了诸如AngularJS之类的大型JS框架。
今天,跨平台的Web应用程序(如Web电子表格)与上个世纪的平台特定应用程序(如VisiCalc,Lotus 1-2-3和Excel)一样无处不在和流行。
Web应用程序在AngularJS的99条线路中提供了多少功能?让我们看看它的进步!
概述
电子表格目录包含我们在三个网络语言的2014版本的展示:HTML5 for structure,CSS3 for presentation以及JS ES6 “Harmony” standard for interaction。它还使用Web存储器进行数据持久性和Web工作人员在后台运行JS代码。在撰写本文时,这些网络标准由Firefox,Chrome和Internet Explorer 11+以及iOS 5+和Android 4+以上的移动浏览器支持。
现在让我们在浏览器中打开电子表格(图19.1):

基本概念
二维的电子表格,列以A开头,行从1开始。每个单元格都有一个唯一的坐标(如A1)和内容(如“1874”),属于四种类型之一:
-
文本:B1中的“+”和D1中的“ - >”对齐,向左对齐。
-
数字:“1874”在A1,“2046”在C1,向右对齐。
-
公式:E1中的
=A1+C1,计算为值“3920”,以浅蓝色背景显示。 -
空值:第2行中的所有单元格当前为空。
单击“3920”将其设置为E1,在输入框中显示其公式(图19.2)。

现在我们把焦点放在A1上并将其内容改为“1”,使E1重新计算其值为“2047”(图19.3)。

按ENTER键将焦点设置为A2,将其内容更改为
=Date(),然后按TAB将B2的内容更改为=alert(),然后再次按TAB将焦点设置为C2(图19.4)。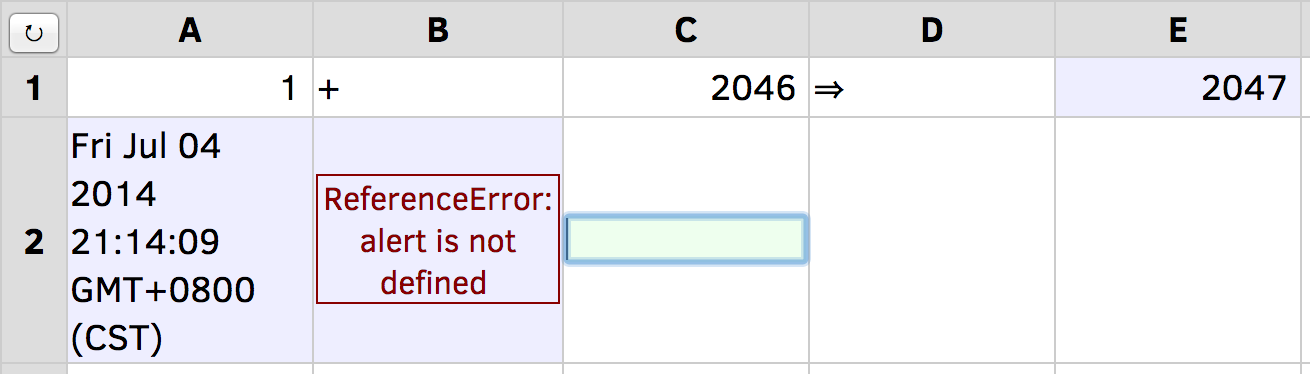
这显示了公式可以计算出数字(E1中为“2047”),文本(A2中的当前时间,与左对齐)或错误(B2中的红色字母,与中心对齐)。
接下来,让我们尝试输入
=for(;;){},一个永远不会终止的无限循环的JS代码。尝试更改后,电子表格会自动恢复C2的内容,从而防止这种情况。现在使用Ctrl-R或Cmd-R重新加载浏览器中的页面,以验证电子表格内容是否持久,在浏览器会话中保持不变。要将电子表格重置为原始内容,请按左上角的“弯曲箭头”按钮。
渐进式增强
在我们深入99行代码之前,有必要在浏览器中禁用JS,重新加载页面,并记下差异(图19.5)。
-
不是一个大网格,只有一个2x2表格留在屏幕上,单个内容单元格。
-
行和列标签被
和替换。 -
按重置按钮不起作用。
-
按TAB或点击第一行内容仍然显示可编辑的输入框。
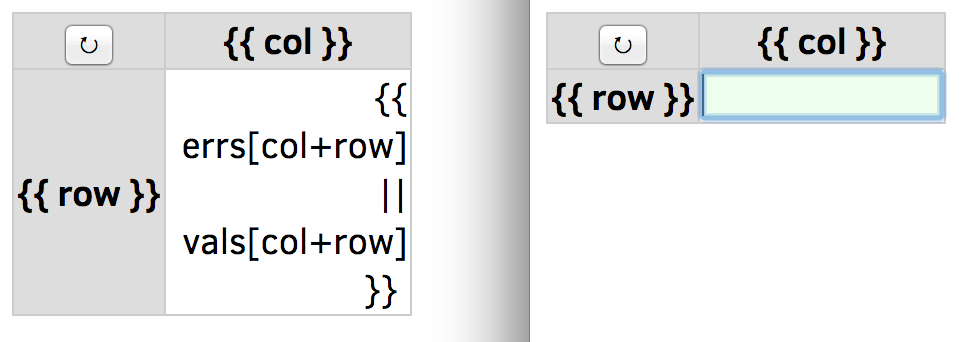
当我们禁用动态交互(JS)时,内容结构(HTML)和演示风格(CSS)仍然有效。如果一个网站在禁用JS和CSS时仍然是有用的,我们说它坚持渐进的增强原则,使其内容可以访问最多的受众。
因为我们的电子表格是一个没有服务器端代码的Web应用程序,所以我们必须依靠JS提供所需的逻辑。但是,当CSS不完全支持时,例如使用屏幕阅读器和文本模式浏览器,它可以正常工作。

如图19.6所示,如果我们在浏览器中启用JS并禁用CSS,效果是:
-
所有的背景和前景色都消失了。
-
输入框和单元格值都显示,而不是一次只显示一个。
-
否则,应用程序仍然与完整版本相同。
代码演练
图19.7显示了HTML和JS组件之间的链接。为了理解图表,我们来浏览四个源代码文件,按浏览器加载它们的顺序。
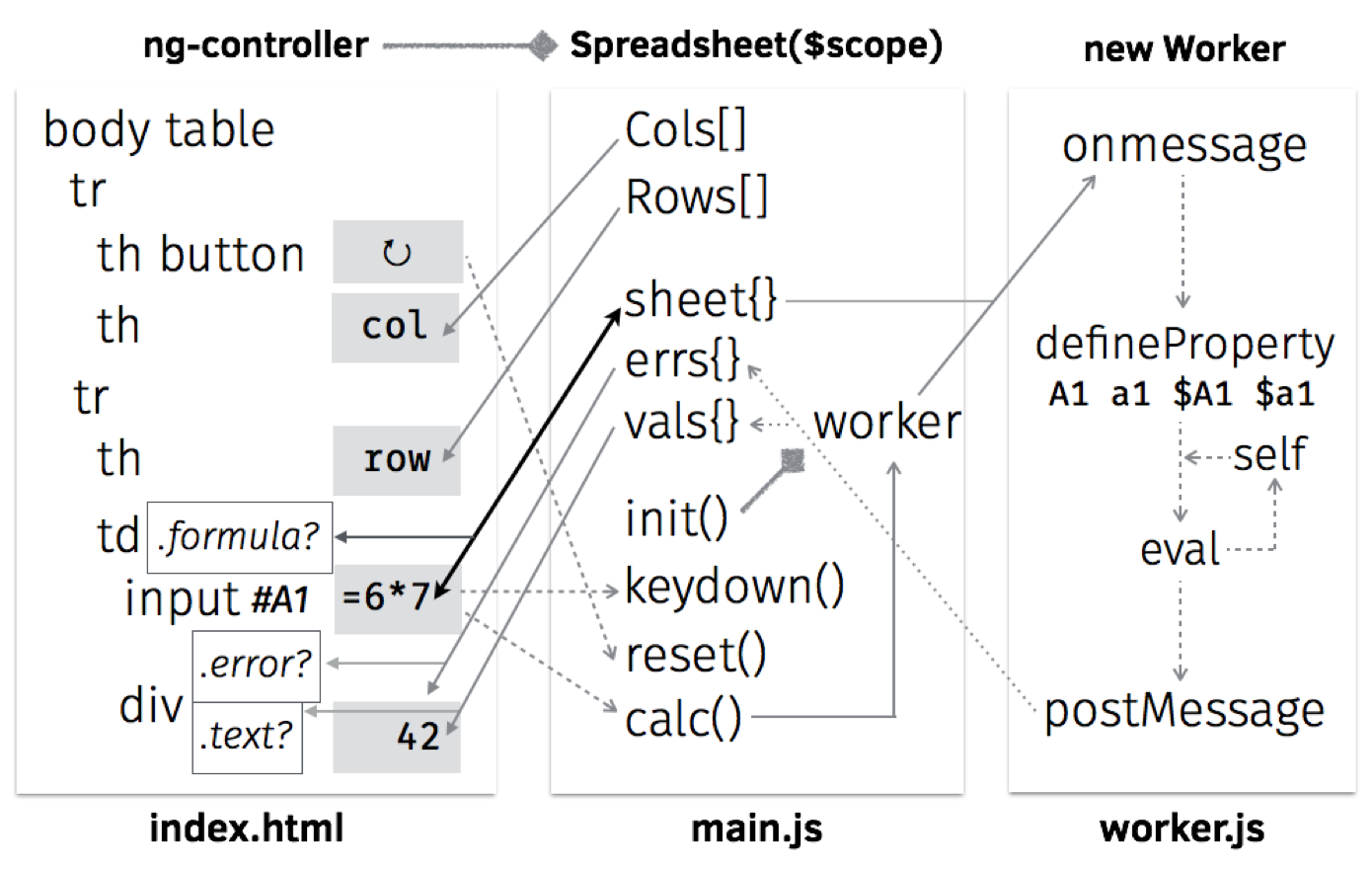
-
index.html: 19 lines
-
main.js: 38 lines (excluding comments and blank lines)
-
worker.js: 30 lines (excluding comments and blank lines)
-
styles.css: 12 lines
HTML
index.html中的第一行声明使用UTF-8编码以HTML5编写:<!DOCTYPE html><html><head><meta charset="UTF-8">没有
charset声明,浏览器可能会将重置按钮的Unicode符号显示为,这是mojibake的示例:由解码问题引起的乱码文本。接下来的三行是JS声明,像往常一样放在
head:<script src="lib/angular.js"></script> <script src="main.js"></script> <script> try { angular.module('500lines') } catch(e){ location="es5/index.html" } </script><script src="…">标记从与HTML页面相同的路径加载JS资源。 例如,如果当前URL是http://abc.com/x/index.html,那么lib/angular.js指向http://abc.com/x/lib/angular.js。try{ angular.module('500lines') }行测试main.js是否正确加载;如果失败,它会告诉浏览器导航到es5/index.html。这种基于重定向的优雅降级技术确保了对于没有ES6支持的2015年前的浏览器,我们可以使用转换为ES5版本的JS程序作为后备。接下来的两行加载CSS资源,关闭
head,并开始包含用户可见部分的body部分:<link href="styles.css" rel="stylesheet"> </head><body ng-app="500lines" ng-controller="Spreadsheet" ng-cloak>np-app和ng-controller属性告诉AngularJS调用500lines模块的Spreadsheet函数,这将返回一个模型:一个在文档视图中提供绑定的对象。(ng-cloak属性将隐藏文档,直到绑定到位)。作为一个具体的例子,当用户点击下一行定义的
<button>时,其ng-click属性将触发并调用由JS模型提供的两个命名函数:reset()和calc():<table><tr> <th><button type="button" ng-click="reset(); calc()"></button></th>接下来一行使用
ng-repeat来显示顶行列标签列表:<th ng-repeat="col in Cols"></th>例如,如果JS模型将
Cols定义为["A","B","C"],则将有相应标记的三个标题单元格(th)。``符号告诉AngularJS插入表达式,用col的当前值填充th里的每个内容。类似地,接下来的两行遍历
Rows-[1,2,3]中的值,依此类推 - 为每个行创建一行,并以最小的数字标记th最左边的单元格:</tr><tr ng-repeat="row in Rows"> <th></th>因为
<tr ng-repeat>尚未用</tr>关闭标签,所以行变量仍然可用于表达式。下一行创建一个数据单元格(td),并在其ng-class属性中使用col和row变量:<td ng-repeat="col in Cols" ng-class="{ formula: ('=' === sheet[col+row][0]) }">在HTML中,
class属性描述了一组允许CSS以不同方式对其进行风格化的类名称。ng-class会计算表达式(('=' === sheet[col+row][0])); 如果它是真的,那么<td>将公式作为一个附加类,有.formula类选择器的8行代码的style.css定义浅蓝色背景。上述的表达式检查当前的单元格是否是正确的公式,通过测试如果
=是sheet[col+row]中的字符串[0],此处的sheet是有坐标(如E1)作为属性,单元格内容(如"=A1+C1")为值的JS模型对象。 请注意,因为col是一个字符串而不是一个数字,col+row里的+表示连接而不是加法。在
<td>内,我们给用户一个输入框来编辑存储在sheet[col+row]中的单元格内容:<input id="" ng-model="sheet[col+row]" ng-change="calc()" ng-model-options="{ debounce: 200 }" ng-keydown="keydown( $event, col, row )">关键属性是
ng-model,可以实现JS模型和输入框的可编辑内容之间的双向绑定。实际上,这意味着每当用户在输入框中进行更改时,JS模型将更新sheet[col+row]以匹配内容,并触发calc()函数重新计算所有公式单元格的值。为了避免在用户按住键时重复调用
calc(),ng-model-options将更新速率限制为每200毫秒一次。这里的
id属性用坐标col+row进行插值。HTML元素的id属性必须与同一文档中所有其他元素的id不同。这确保#A1ID选择器引用单个元素,而不是一组元素,如类选择器.formula。当用户按UP/DOWN/ENTER键时,keydown()中的键盘导航逻辑将使用ID选择器来确定要关注的输入框。在输入框之后,我们放置一个
<div>来显示当前单元格的计算值,在JS模型中由对象errs和val表示:<div ng-class="{ error: errs[col+row], text: vals[col+row][0] }"> </div>如果在计算公式时发生错误,则文本插值使用
errs[col+row]中包含的错误消息,ng-class将错误类应用于元素,允许CSS以不同的方式设计(用红色字母对齐到 中心等)。当没有错误时,
||的右侧的vals[col+row]被插入。如果它是一个非空字符串,则初始字符([0])将求值为true,将text类应用于左对齐文本的元素。因为空字符串和数值没有初始字符,所以
ng-class不会为它们分配任何类,所以CSS可以使用正确的对齐方式将它们设置为默认情况。最后,我们用
</tr>关闭列级别的ng-repeat循环,用</tr>关闭行级循环,并用以下结束HTML文档:</td> </tr></table> </body></html>JS:主控制器
main.js文件根据index.html中的<body>元素的要求定义了500lines模块及其`Spreadshee控制器功能。作为HTML视图和后台工作者之间的桥梁,它有四个任务:
-
定义列和行的尺寸和标签。
-
提供键盘导航和重置按钮的事件处理程序。
-
当用户更改电子表格时,将其新内容发送给工作人员。
-
当计算结果从工作人员到达时,更新视图并保存当前状态。
图19.8中的流程图详细地显示了控制器与工作者的交互:
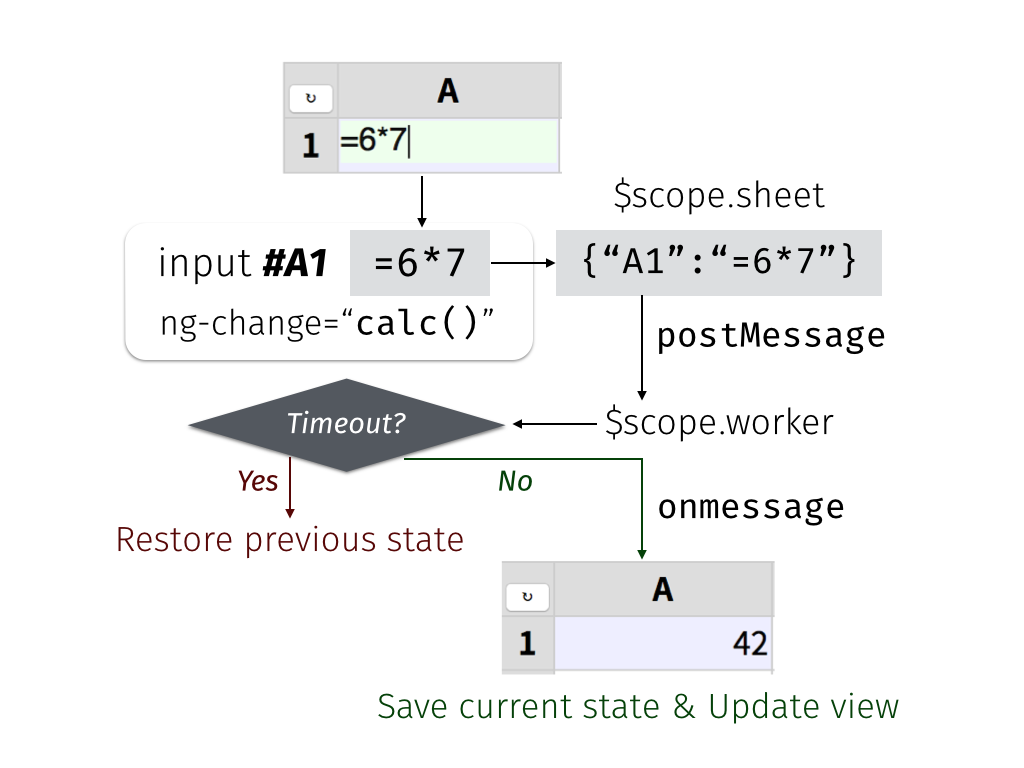
我们来看看代码。在第一行,我们要求AngularJS
$scope的范围:angular.module('500lines', []).controller('Spreadsheet', function ($scope, $timeout) {$scope里的$是变量名的一部分。我们还从AngularJS请求$timeout服务函数; 稍后,我们将使用它来防止无限循环的公式。将
Cols和Row放入模型中,只需将它们定义为$scope的属性:// Begin of $scope properties; start with the column/row labels $scope.Cols = [], $scope.Rows = []; for (col of range( 'A', 'H' )) { $scope.Cols.push(col); } for (row of range( 1, 20 )) { $scope.Rows.push(row); }语法ES6 for…of 可以轻松地从起始点遍历到终点循环,和辅助函数
range定义为生成器:function* range(cur, end) { while (cur <= end) { yield cur;function*表示range每次用while循环yield一个值返回一个迭代器。每当for循环需要下一个值时,它将在yield后恢复执行:// If it’s a number, increase it by one; otherwise move to next letter cur = (isNaN( cur ) ? String.fromCodePoint( cur.codePointAt()+1 ) : cur+1); } }为了生成下一个值,我们使用
isNaN来查看cur是否是一个字母(NaN代表“不是一个数字”)。如果是这样,我们得到这个字母的code point value,增加一个值,convert the codepoint返回下一个字母。 否则,我们只需增加一个数字。接下来,我们定义处理键盘导航的
keydown()函数:// UP(38) and DOWN(40)/ENTER(13) move focus to the row above (-1) and below (+1). $scope.keydown = ({which}, col, row)=>{ switch (which) {arrow function从
<input ng-keydown>输入参数($event, col, row),使用destructuring assignment将$event.which赋值which,并检查它是否在三个键盘方向码中:case 38: case 40: case 13: $timeout( ()=>{如果是,我们使用
$timeout处理焦点变化,在ng-keydown和ng-change之后。因为$timeout要求函数作为输入,()=>{…}构造了通过检查移动方向来检查焦点变化的逻辑函数。const direction = (which === 38) ? -1 : +1;const表示在函数运行期间direction不会被改变。移动方向要么是向上(-1,从A2到A1),如果键码是38(UP),否则是向下(+1,从A2到A3)。接下来,我们使用ID选择器语法(例如
"#A3")检索目标元素,该方法用一对反引号的template string构成,连接#,当前col和目标row + direction:const cell = document.querySelector( `#${ col }${ row + direction }` ); if (cell) { cell.focus(); } } ); } };我们对
querySelector的结果进行额外的检查,因为从A1向上移动将产生没有相应元素的选择器#A0,因此不会触发焦点更改 —— 在底行按下DOWN也是如此。接下来,我们定义了
reset()函数,因此reset按钮可以恢复工作表的内容:// Default sheet content, with some data cells and one formula cell. $scope.reset = ()=>{ $scope.sheet = { A1: 1874, B1: '+', C1: 2046, D1: '->', E1: '=A1+C1' }; }init()函数尝试从localStorage恢复其先前状态的表格内容,如果是第一次运行应用程序,则默认为初始内容:// Define the initializer, and immediately call it ($scope.init = ()=>{ // Restore the previous .sheet; reset to default if it’s the first run $scope.sheet = angular.fromJson( localStorage.getItem( '' ) ); if (!$scope.sheet) { $scope.reset(); } $scope.worker = new Worker( 'worker.js' ); }).call();上面的
init()函数中有几个重要的事:-
我们使用
($scope.init = ()=>{…}).call()定义函数并立即调用它。 -
因为localStorage只存储字符串,所以我们使用
angular.fromJson()从JSON表示中解析表结构。 -
在
init()的最后一步,我们创建一个新的Web worker线程并将其分配给workerscope属性。虽然workers在视图中没有直接使用,但是通常使用$scope来共享模型函数中使用的对象,这种情况下在init()和calc()之间。
虽然
sheet保存用户可编辑的单元格内容,但是errs和vals包含对用户只读的计算结果 - 错误和值:// Formula cells may produce errors in .errs; normal cell contents are in .vals [$scope.errs, $scope.vals] = [ {}, {} ];使用这些属性,我们可以定义每当用户更改表单时触发的
calc()函数:// Define the calculation handler; not calling it yet $scope.calc = ()=>{ const json = angular.toJson( $scope.sheet );这里我们来看一下表单状态的快照,并将其存储在一个JSON字符串的常量
json中。接下来,我们从$timeout构造一个promise,如果需要超过99毫秒的时间,它将取消即将进行的计算:const promise = $timeout( ()=>{ // If the worker has not returned in 99 milliseconds, terminate it $scope.worker.terminate(); // Back up to the previous state and make a new worker $scope.init(); // Redo the calculation using the last-known state $scope.calc(); }, 99 );由于我们确保通过HTML中的
<input ng-model-options>属性每隔200毫秒调用一次calc(),所以这会使init()恢复到最后一个已知状态的时间为101毫秒,构建新的worker。workeer的任务是从
sheet内容中计算errs和val。因为main.js和worker.js通过消息传递进行通信,所以我们需要一个onmessage处理程序来接收结果,一旦它们准备就绪:// When the worker returns, apply its effect on the scope $scope.worker.onmessage = ({data})=>{ $timeout.cancel( promise ); localStorage.setItem( '', json ); $timeout( ()=>{ [$scope.errs, $scope.vals] = data; } ); };如果调用
onmessage,我们知道json中的sheet快照是稳定的(即不包含无限循环公式),所以我们取消99毫秒的超时时间,将快照写入localStorage,并安排一个$timeout函数将errs和vals更新到用户可见视图。在程序处理到位后,我们可以将
sheet的状态发布给worker,在后台开始计算:// Post the current sheet content for the worker to process $scope.worker.postMessage( $scope.sheet ); }; // Start calculation when worker is ready $scope.worker.onmessage = $scope.calc; $scope.worker.postMessage( null ); });JS: Background Worker
使用Web worker计算公式有三个原因,而不是使用主要的JS线程来完成任务:
-
当工作人员在后台运行时,用户可以自由地继续与电子表格进行交互,而不会被主线程中的计算阻塞。
-
因为我们接受公式中的任何JS表达式,所以worker提供了一个沙箱来阻止公式干扰包含页面,例如弹出一个
alert()对话框。 -
公式可以将任何坐标称为变量。其他坐标可能包含可能以循环引用结尾的另一个公式。为了解决这个问题,我们使用worker的全局范围对象
self,并将这些变量定义为self的getter函数来实现循环预防逻辑。
考虑到这些,让我们来看看worker的代码。
工人的唯一目的是定义
onmessage。处理程序使用sheet,计算errs和vals,并将其返回主JS线程。我们首先在收到消息时重新初始化三个变量:let sheet, errs, vals; self.onmessage = ({data})=>{ [sheet, errs, vals] = [ data, {}, {} ];为了将坐标转换为全局变量,我们首先使用
for... in循环遍历表中的每个属性:for (const coord in sheet) {ES6引入
const,let声明块作用域常量和变量;const coord意味着循环中定义的函数将在每次迭代中捕获coord的值。相比之下,早期版本的JS中的
var coord将声明一个函数作用域变量,并且在每个循环迭代中定义的函数最终将指向同一个coord变量。惯用的公式变量是不区分大小写的,可以选择一个
$前缀。因为JS变量是区分大小写的,所以我们使用map来遍历相同坐标的四个变量名:// Four variable names pointing to the same coordinate: A1, a1, $A1, $a1 [ '', '$' ].map( p => [ coord, coord.toLowerCase() ].map(c => { const name = p+c;注意上面的简写箭头函数语法:
p => ...和(p) => { ... }1一样:// Worker is reused across calculations, so only define each variable once if ((Object.getOwnPropertyDescriptor( self, name ) || {}).get) { return; } // Define self['A1'], which is the same thing as the global variable A1 Object.defineProperty( self, name, { get() {{ get() { … } }是{ get() { … } }的简写。因为我们之定义了get和set,变量变成只刻度并且不能被其他公式更改。get开始于检查vals[coord],并且返回计算的值:if (coord in vals) { return vals[coord]; }如果没有,我们需要从
sheet[coord]计算vals[coord]。首先我们将其设置为
NaN,所以自引用就是设置A1位=A1,而不是无限的循环中。vals[coord] = NaN;接下来,我们检查
sheet[coord]是否是一个数字,将其转换为带前缀+的数字,将数字分配给x,并将其字符串表示与原始字符串进行比较。如果它们不同,那么我们将x设置为原始字符串:// Turn numeric strings into numbers, so =A1+C1 works when both are numbers let x = +sheet[coord]; if (sheet[coord] !== x.toString()) { x = sheet[coord]; }如果
x的初始字符为=,那么它是一个公式单元格。 我们使用eval.call()来评估part=after,使用第一个参数null来指示eval在全局范围内运行,求值时隐藏x和sheet的词法范围变量:// Evaluate formula cells that begin with = try { vals[coord] = (('=' === x[0]) ? eval.call( null, x.slice( 1 ) ) : x);如果求值成功,结果存储在
vals[coord]中。对于非公式单元格,vals[coord]的值x可以是数字或字符串。如果
eval返回错误,catch块将测试是否因为该公式引用了一个尚未在self中定义的空单元格:} catch (e) { const match = /\$?[A-Za-z]+[1-9][0-9]*\b/.exec( e ); if (match && !( match[0] in self )) {如果用户稍后在
[coord]中给出缺少的单元格,则临时值将被Object.defineProperty覆盖。其他类型的错误存储在
errs[coord]中:// Otherwise, stringify the caught exception in the errs object errs[coord] = e.toString(); }出现错误时,
vals[coord]的值将保持为NaN,因为赋值没有完成执行。最后,
get访问器返回存储在vals[coord]中的计算值,它必须是数字,布尔值或字符串:// Turn vals[coord] into a string if it's not a number or Boolean switch (typeof vals[coord]) { case 'function': case 'object': vals[coord]+=''; } return vals[coord]; } } ); })); }使用为所有坐标定义的访问器,worker再次通过坐标,使用
self [coord]调用每个访问器,然后将生成的err和vals发回主JS线程:// For each coordinate in the sheet, call the property getter defined above for (const coord in sheet) { self[coord]; } return [ errs, vals ]; }CSS
styles.css文件只包含几个选择器及其演示设计。首先,我们对表格进行设计,以将所有单元格边框合并在一起,在相邻单元格之间不留空格:
table { border-collapse: collapse; }标题和数据单元都具有相同的边框样式,但是我们可以通过背景颜色来区分它们:标题单元格是浅灰色的,默认情况下数据单元格是白色的,而公式单元格则是浅蓝色的背景:
th, td { border: 1px solid #ccc; } th { background: #ddd; } td.formula { background: #eef; }显示的宽度对于每个单元格的计算值是固定的。空单元格接收到最小高度,并且长行被剪切后跟省略号:
td div { text-align: right; width: 120px; min-height: 1.2em; overflow: hidden; text-overflow: ellipsis; }文本对齐和装饰由每个值的类型确定,如文本和错误类选择器所反映的:
div.text { text-align: left; } div.error { text-align: center; color: #800; font-size: 90%; border: solid 1px #800 }对于用户可编辑的输入框,我们使用绝对定位将其覆盖在其单元格的顶部,并使其透明,因此具有单元格值的底层div通过以下方式显示:
input { position: absolute; border: 0; padding: 0; width: 120px; height: 1.3em; font-size: 100%; color: transparent; background: transparent; }当用户将焦点放在输入框上时,弹出前景:
input:focus { color: #111; background: #efe; }此外,底层的div折叠成一行,所以它完全被输入框所覆盖:
input:focus + div { white-space: nowrap; }结论
由于这本书500 Lines or Less,99行代码的web spreadsheet 是一个最小的例子 —— 请随意尝试并扩展它。
这里有一些想法,在401行的剩余空间中都可以轻松使用:
-
使用ShareJS,AngularFire或GoAngular的合作在线编辑器。
-
Markdown语法支持文本单元格,使用角标记。
-
来自OpenFormula标准的通用公式函数(SUM,TRIM等)。
-
通过SheetJS与流行的电子表格格式(如CSV和SpreadsheetML)进行互操作。
-
从Google电子表格和EtherCalc导入和导出到在线电子表格服务。
A Note on JS versions
This chapter aims to demonstrate new concepts in ES6, so we use the Traceur compiler to translate source code to ES5 to run on pre-2015 browsers.
If you prefer to work directly with the 2010 edition of JS, the as-javascript-1.8.5 directory has main.js and worker.js written in the style of ES5; the source code is line-by-line comparable to the ES6 version with the same line count.
For people preferring a cleaner syntax, the as-livescript-1.3.0 directory uses LiveScript instead of ES6 to write main.ls and worker.ls; it is 20 lines shorter than the JS version.
Building on the LiveScript language, the as-react-livescript directory uses the ReactJS framework; it is 10 lines more longer than the AngularJS equivalent, but runs considerably faster.
If you are interested in translating this example to alternate JS languages, send a pull request—I’d love to hear about it!
-
-
500 Lines or Less Chapter 14: A Simple Object Model 翻译
Carl Friedrich Bolz是伦敦国王学院的研究员,对各种动态语言的实现和优化有着广泛的兴趣。他是PyPy / RPython的核心作者之一,致力于Prolog,Racket,Smalltalk,PHP和Ruby的实现。他的Twitter名是@cfbolz。
介绍
面向对象编程是本章使用的主要编程范例之一,许多语言都提供某种形式的面向对象。而表面上,不同的面向对象编程语言为程序员提供的机制非常相似,细节可能会有很大变化。大多数语言的共同点是存在对象和继承机制。然而,类不是每种语言直接支持的功能。例如,在基于原型的语言(如Self或JavaScript)中,类的概念不存在,而对象则直接相互继承。
了解不同对象模型之间的差异是有趣的。他们透露出不同语言之间的相似之处。将新语言的模型放入其他语言模型的上下文中,可以快速了解新模型,并为编程语言设计获得更好的感觉。
本章探讨了一系列非常简单的对象模型的实现。它以简单的实例和类开始,并且可以调用实例上的方法。这是在早期的OO语言(如Simula 67和Smalltalk)中建立的“经典”面向对象方法。然后,这个模型逐步扩展,接下来的两个步骤探索不同的语言设计选择,最后一步提高了对象模型的效率。最终的模型不是真正的语言,而是Python的对象模型的理想化的简化版本。
本章介绍的对象模型将在Python中实现。该代码适用于Python 2.7和3.4。为了更好地了解行为和设计选择,本章还将介绍对象模型的测试。测试可以用py.test或者鼻子来运行。
选择Python作为实现语言是非常不切实际的。一个“真正的”虚拟机通常以低级语言(如C/C ++)实现,并且需要非常注意工程细节以使其高效。然而,更简单的实现语言更容易专注于实际行为差异,而不是被实现细节陷入困境。
基于方法的模型
我们将开始的对象模型是Smalltalk的一个非常简化的版本。Smalltalk是由Alan Kay在上世纪七十年代施乐公司设计的面向对象编程语言。它推广了面向对象编程,并且是当今编程语言中许多功能的来源。Smalltalk语言设计的核心原则之一是“一切都是对象”。Smalltalk今天使用的最直接的后继者是Ruby,它使用更多的C语法,但保留了Smalltalk的大多数对象模型。
本节中的对象模型将具有它们的类和实例,能够将属性读取和写入对象,调用对象方法的能力以及类作为另一个类的子类的能力。从一开始,类是普通的对象,本身可以具有属性和方法。
关于术语的说明:在本章中,我将使用“实例”一词来表示 - “不是类的对象”。
开始的办法是写一个测试来指定要实现的行为应该是什么。本章提出的所有测试将由两部分组成。首先,一些常规的Python代码定义和使用几个类,并利用Python对象模型的日益高级的功能。二,相应的测试使用对象模型,我们将在本章中实现,而不是普通的Python类。
使用普通Python类和使用对象模型之间的映射将在测试中手动完成。例如,在Python中,而不是写入
obj.attribute,在对象模型中,我们将使用方法obj.read_attr(“attribute”)。这种映射将在实际语言中由语言的解释器或编译器完成。本章进一步的简化是,我们在实现对象模型的代码和用于编写对象中使用的方法的代码之间没有明确的区别。在一个实际的系统中,两者通常以不同的编程语言来实现。
我们以一个简单的测试来开始读写对象字段。
def test_read_write_field(): # Python code class A(object): pass obj = A() obj.a = 1 assert obj.a == 1 obj.b = 5 assert obj.a == 1 assert obj.b == 5 obj.a = 2 assert obj.a == 2 assert obj.b == 5 # Object model code A = Class(name="A", base_class=OBJECT, fields={}, metaclass=TYPE) obj = Instance(A) obj.write_attr("a", 1) assert obj.read_attr("a") == 1 obj.write_attr("b", 5) assert obj.read_attr("a") == 1 assert obj.read_attr("b") == 5 obj.write_attr("a", 2) assert obj.read_attr("a") == 2 assert obj.read_attr("b") == 5测试必须实现的三件事。
Class和Instance类分别表示对象模型的类和实例。有两个类的特殊实例:OBJECT和TYPE。OBJECT对应于Python中的对象,是继承层次结构的最终基类。TYPE对应于Python中的类型,是所有类的类型。要对
Class和Instance操作,他们通过继承一个共享的基类Base来实现一个共享接口,它暴露了许多方法:class Base(object): """ The base class that all of the object model classes inherit from. """ def __init__(self, cls, fields): """ Every object has a class. """ self.cls = cls self._fields = fields def read_attr(self, fieldname): """ read field 'fieldname' out of the object """ return self._read_dict(fieldname) def write_attr(self, fieldname, value): """ write field 'fieldname' into the object """ self._write_dict(fieldname, value) def isinstance(self, cls): """ return True if the object is an instance of class cls """ return self.cls.issubclass(cls) def callmethod(self, methname, *args): """ call method 'methname' with arguments 'args' on object """ meth = self.cls._read_from_class(methname) return meth(self, *args) def _read_dict(self, fieldname): """ read an field 'fieldname' out of the object's dict """ return self._fields.get(fieldname, MISSING) def _write_dict(self, fieldname, value): """ write a field 'fieldname' into the object's dict """ self._fields[fieldname] = value MISSING = object()Base类实现存储对象的类,以及包含对象的字段值的字典。现在我们需要实现Class和Instance。Instance的构造函数使类被实例化,并初始化field dict为空字典。否则实例只是一个单薄的子类,它不会添加任何额外的功能。Class的构造函数使用类的名称,基类,类和元类的字典。对于类,字段由对象模型的用户传递到构造函数中。类构造函数也是一个基类,现在还不需要这个测试,下一节我们将使用它。class Instance(Base): """Instance of a user-defined class. """ def __init__(self, cls): assert isinstance(cls, Class) Base.__init__(self, cls, {}) class Class(Base): """ A User-defined class. """ def __init__(self, name, base_class, fields, metaclass): Base.__init__(self, metaclass, fields) self.name = name self.base_class = base_class由于类也是一种对象,它们(间接地)从
Base继承。因此,类需要的是另一个类的一个实例:它的元类。现在我们通过了第一个测试。唯一缺少的一点是基类
TYPE和OBJECT的定义,它们都是Class的实例。对于这些,我们将会从Smalltalk模型中脱颖而出,该模型具有相当复杂的元类系统。相反,我们将从Python的ObjVlisp中引入的模型。在ObjVlisp模型中,
OBJECT和TYPE是交织在一起的。OBJECT是所有类的基类,意思是它没有基类。TYPE是OBJECT的子类。默认情况下,每个类都是TYPE的一个实例。TYPE和OBJECT都是TYPE的实例。 但是,程序员也可以将TYPE子类化成一个新的元类:# set up the base hierarchy as in Python (the ObjVLisp model) # the ultimate base class is OBJECT OBJECT = Class(name="object", base_class=None, fields={}, metaclass=None) # TYPE is a subclass of OBJECT TYPE = Class(name="type", base_class=OBJECT, fields={}, metaclass=None) # TYPE is an instance of itself TYPE.cls = TYPE # OBJECT is an instance of TYPE OBJECT.cls = TYPE要定义新的元类,就可以对
TYPE进行子类化。然而,在本章的其余部分,我们不会这样做; 我们只需要使用TYPE作为每个类的元类。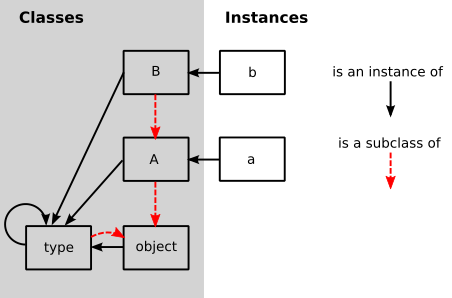
现在第一次测试通过了。第二个测试检查读和写属性是否也适用于类。这很容易写,并立即通过。
def test_read_write_field_class(): # classes are objects too # Python code class A(object): pass A.a = 1 assert A.a == 1 A.a = 6 assert A.a == 6 # Object model code A = Class(name="A", base_class=OBJECT, fields={"a": 1}, metaclass=TYPE) assert A.read_attr("a") == 1 A.write_attr("a", 5) assert A.read_attr("a") == 5isinstance 检查
到目前为止,我们没有利用对象有类的事实。下一个测试实现了
isinstance机制:def test_isinstance(): # Python code class A(object): pass class B(A): pass b = B() assert isinstance(b, B) assert isinstance(b, A) assert isinstance(b, object) assert not isinstance(b, type) # Object model code A = Class(name="A", base_class=OBJECT, fields={}, metaclass=TYPE) B = Class(name="B", base_class=A, fields={}, metaclass=TYPE) b = Instance(B) assert b.isinstance(B) assert b.isinstance(A) assert b.isinstance(OBJECT) assert not b.isinstance(TYPE)要检查对象
obj是否是某个类cls的实例,只要检查cls是obj类的父类还是类本身就足够了。要检查一个类是否是另一个类的父类,移动该类的父类。当且仅当在该链中找到其他类时,才是父类。类的父类链,包括类本身,被称为该类的“方法解析顺序”。 可以方便地递归计算:class Class(Base): ... def method_resolution_order(self): """ compute the method resolution order of the class """ if self.base_class is None: return [self] else: return [self] + self.base_class.method_resolution_order() def issubclass(self, cls): """ is self a subclass of cls? """ return cls in self.method_resolution_order()使用该代码,测试通过。
调用方法
该对象模型还缺少调用对象方法的功能。在本章中,我们将实现一个简单的单继承模型。
def test_callmethod_simple(): # Python code class A(object): def f(self): return self.x + 1 obj = A() obj.x = 1 assert obj.f() == 2 class B(A): pass obj = B() obj.x = 1 assert obj.f() == 2 # works on subclass too # Object model code def f_A(self): return self.read_attr("x") + 1 A = Class(name="A", base_class=OBJECT, fields={"f": f_A}, metaclass=TYPE) obj = Instance(A) obj.write_attr("x", 1) assert obj.callmethod("f") == 2 B = Class(name="B", base_class=A, fields={}, metaclass=TYPE) obj = Instance(B) obj.write_attr("x", 2) assert obj.callmethod("f") == 3要正确实现发送到对象的方法,我们将遍历对象的类的方法解析顺序。在方法解析顺序中的一个类的字典中找到的第一个方法被调用:
class Class(Base): ... def _read_from_class(self, methname): for cls in self.method_resolution_order(): if methname in cls._fields: return cls._fields[methname] return MISSING与
Base中的callmethod代码一起,这通过了测试。为了确保参数方法工作,并且正确实现覆盖方法,我们可以使用以下稍复杂的测试,其已经通过:
def test_callmethod_subclassing_and_arguments(): # Python code class A(object): def g(self, arg): return self.x + arg obj = A() obj.x = 1 assert obj.g(4) == 5 class B(A): def g(self, arg): return self.x + arg * 2 obj = B() obj.x = 4 assert obj.g(4) == 12 # Object model code def g_A(self, arg): return self.read_attr("x") + arg A = Class(name="A", base_class=OBJECT, fields={"g": g_A}, metaclass=TYPE) obj = Instance(A) obj.write_attr("x", 1) assert obj.callmethod("g", 4) == 5 def g_B(self, arg): return self.read_attr("x") + arg * 2 B = Class(name="B", base_class=A, fields={"g": g_B}, metaclass=TYPE) obj = Instance(B) obj.write_attr("x", 4) assert obj.callmethod("g", 4) == 12基于属性的模型
现在我们的对象模型的最简单版本正在运行,我们思考改进的方法。本节将介绍基于方法的模型和基于属性的模型之间的区别。另一方面,这是Smalltalk,Ruby和JavaScript以及Python和Lua之间的核心区别之一。
基于方法的模型具有作为程序执行原语的方法调用:
result = obj.f(arg1, arg2)基于属性的模型将方法调用分为两个步骤:查找属性并调用结果:
method = obj.f result = method(arg1, arg2)该差异可以在以下测试中显示:
def test_bound_method(): # Python code class A(object): def f(self, a): return self.x + a + 1 obj = A() obj.x = 2 m = obj.f assert m(4) == 7 class B(A): pass obj = B() obj.x = 1 m = obj.f assert m(10) == 12 # works on subclass too # Object model code def f_A(self, a): return self.read_attr("x") + a + 1 A = Class(name="A", base_class=OBJECT, fields={"f": f_A}, metaclass=TYPE) obj = Instance(A) obj.write_attr("x", 2) m = obj.read_attr("f") assert m(4) == 7 B = Class(name="B", base_class=A, fields={}, metaclass=TYPE) obj = Instance(B) obj.write_attr("x", 1) m = obj.read_attr("f") assert m(10) == 12虽然设置与方法调用的相应测试相同,但是调用方法的方式是不同的。首先,在对象上查找具有该方法名称的属性。该查找操作的结果是绑定方法,封装对象以及类中发现的函数的对象。 接下来,使用回调调用该绑定方法。
要实现此行为,我们需要更改
Base.read_attr实现。如果在字典中找不到属性,则在类中查找该属性。如果在类中找到,并且该属性是可调用的,则需要将其转换为绑定方法。 为了模拟一个绑定的方法,我们只需使用一个闭包。除了更改Base.read_attr之外,我们还可以更改Base.callmethod以使用新的方法调用方法来确保所有测试仍然通过。class Base(object): ... def read_attr(self, fieldname): """ read field 'fieldname' out of the object """ result = self._read_dict(fieldname) if result is not MISSING: return result result = self.cls._read_from_class(fieldname) if _is_bindable(result): return _make_boundmethod(result, self) if result is not MISSING: return result raise AttributeError(fieldname) def callmethod(self, methname, *args): """ call method 'methname' with arguments 'args' on object """ meth = self.read_attr(methname) return meth(*args) def _is_bindable(meth): return callable(meth) def _make_boundmethod(meth, self): def bound(*args): return meth(self, *args) return bound代码的其余部分不需要更改。
元对象协议
除了由程序直接调用的“普通”方法外,许多动态语言支持特殊方法。这些方法不是直接调用,而是被对象系统调用。在Python中,这些特殊方法通常具有以两个下划线开头和结尾的名称;例如
__init__。可以使用特殊方法来覆盖原始操作,并为其提供自定义行为。因此,它们将对象模型机器确切地告诉对象。Python的对象模型有几十种特殊的方法。Meta-object协议由Smalltalk引入,但更常用于Common Lisp的对象系统,如CLOS。这也是名称元对象协议,用特殊方法的集合创造。
在本章中,我们将添加三个meta-hooks到我们的对象模型,用于微调当读取和写入属性时会发生什么。我们首先添加的特殊方法是
__getattr__和__setattr__,它们紧跟Python命名后。自定义读和写和属性
当通过正常方式找不到正在查找的属性时,对象模型调用
__getattr__;即既不在实例上也不在课堂上。它获取被查找的属性的名称作为参数。相当于__getattr__方法是早期Smalltalk系统的一部分doesNotUnderstand。__setattr__的情况有点不同。由于设置属性始终创建它,所以在设置属性时始终会调用__setattr__。为了确保__setattr__方法始终存在,OBJECT类有一个__setattr__的定义。它的实现设置属性,将属性写入对象的字典。在某些情况下,这也使得用户定义的__setattr__可以委托给OBJECT .__ setattr__。这两种特殊方法的测试如下:
def test_getattr(): # Python code class A(object): def __getattr__(self, name): if name == "fahrenheit": return self.celsius * 9. / 5. + 32 raise AttributeError(name) def __setattr__(self, name, value): if name == "fahrenheit": self.celsius = (value - 32) * 5. / 9. else: # call the base implementation object.__setattr__(self, name, value) obj = A() obj.celsius = 30 assert obj.fahrenheit == 86 # test __getattr__ obj.celsius = 40 assert obj.fahrenheit == 104 obj.fahrenheit = 86 # test __setattr__ assert obj.celsius == 30 assert obj.fahrenheit == 86 # Object model code def __getattr__(self, name): if name == "fahrenheit": return self.read_attr("celsius") * 9. / 5. + 32 raise AttributeError(name) def __setattr__(self, name, value): if name == "fahrenheit": self.write_attr("celsius", (value - 32) * 5. / 9.) else: # call the base implementation OBJECT.read_attr("__setattr__")(self, name, value) A = Class(name="A", base_class=OBJECT, fields={"__getattr__": __getattr__, "__setattr__": __setattr__}, metaclass=TYPE) obj = Instance(A) obj.write_attr("celsius", 30) assert obj.read_attr("fahrenheit") == 86 # test __getattr__ obj.write_attr("celsius", 40) assert obj.read_attr("fahrenheit") == 104 obj.write_attr("fahrenheit", 86) # test __setattr__ assert obj.read_attr("celsius") == 30 assert obj.read_attr("fahrenheit") == 86为了通过这些测试,需要改变
Base.read_attr和Base.write_attr方法:class Base(object): ... def read_attr(self, fieldname): """ read field 'fieldname' out of the object """ result = self._read_dict(fieldname) if result is not MISSING: return result result = self.cls._read_from_class(fieldname) if _is_bindable(result): return _make_boundmethod(result, self) if result is not MISSING: return result meth = self.cls._read_from_class("__getattr__") if meth is not MISSING: return meth(self, fieldname) raise AttributeError(fieldname) def write_attr(self, fieldname, value): """ write field 'fieldname' into the object """ meth = self.cls._read_from_class("__setattr__") return meth(self, fieldname, value)如果方法存在,则调用
__getattr__更改读取属性的过程,并使用fieldname作为参数,而不是引发错误。请注意,__getattr__仅在类中查找,而不是递归调用self.read_attr("__getattr__")。那是因为如果没有在对象上定义__getattr__,后者会导致read_attr的无限递归。属性的写入推到
__setattr__方法里。为了使它工作,OBJECT需要一个__setattr__方法来调用默认行为,如下所示:def OBJECT__setattr__(self, fieldname, value): self._write_dict(fieldname, value) OBJECT = Class("object", None, {"__setattr__": OBJECT__setattr__}, None)OBJECT__setattr__的行为就像以前的write_attr行为。通过这些修改,通过新的测试。描述符协议
上述测试提供了不同范围之间的自动转换,属性名称需要在
__getattr__和__setattr__方法中显式检查。为了解决这个问题,描述符协议是在Python中引入的。虽然在对象上调用
__getattr__和__setattr__读取属性,但是描述符协议对从对象获取属性的结果调用了一种特殊方法。可以将其视为将方法绑定到一般化的对象 - 实际上,使用描述符协议来实现将方法绑定到对象。除了绑定的方法之外,Python中描述符协议的最重要的用例是staticmethod,classmethod和property的实现。在本小节中,我们将介绍处理绑定对象的描述符协议的子集。这是使用特殊方法
__get__完成的,最好用示例测试来解释:def test_get(): # Python code class FahrenheitGetter(object): def __get__(self, inst, cls): return inst.celsius * 9. / 5. + 32 class A(object): fahrenheit = FahrenheitGetter() obj = A() obj.celsius = 30 assert obj.fahrenheit == 86 # Object model code class FahrenheitGetter(object): def __get__(self, inst, cls): return inst.read_attr("celsius") * 9. / 5. + 32 A = Class(name="A", base_class=OBJECT, fields={"fahrenheit": FahrenheitGetter()}, metaclass=TYPE) obj = Instance(A) obj.write_attr("celsius", 30) assert obj.read_attr("fahrenheit") == 86FahrenheitGetter实例中调用__get__方法,在obj类中查找之后。__get__的参数是查找完成的实例。实现它很容易。我们只需要更改
_is_bindable和_make_boundmethod:def _is_bindable(meth): return hasattr(meth, "__get__") def _make_boundmethod(meth, self): return meth.__get__(self, None)这使测试通过。以前关于绑定方法的测试还是通过的,因为Python的函数有一个返回绑定方法对象的
__get__方法。在实践中,描述符协议相当复杂。它还支持
__set__来覆盖属性之前的含义。此外,删减一部分代码。请注意,_make_boundmethod在实现级别调用__get__,而不是使用meth.read_attr("__get__")。这是必要的,因为我们的对象模型借用了Python的函数和方法,而不是使用对象模型的表示。更完整的对象模型将不得不解决这个问题。实例优化
虽然对象模型的前三个变体涉及行为变化,但在最后一节中,我们将会对优化进行研究,而不会产生任何行为影响。这种优化被称为映射,并在虚拟机中开创了自编程语言6。它仍然是最重要的对象模型优化之一:它用于PyPy和所有现代JavaScript VM,如V8(优化称为隐藏类)。
优化从以下观察开始:在到目前为止所实现的对象模型中,所有实例都使用完整的字典来存储其属性。使用散列图实现字典,这需要大量的内存。此外,同一类的实例的字典通常也具有相同的键。例如,给定一个类Point,所有其实例的字典的键可能是“x”和“y”。
地图优化利用了这一事实。它将每个实例的字典有效地分成两部分。存储可以在具有相同属性名称集的所有实例之间共享的键(映射)的部分。然后,该实例仅存储对共享映射的引用和列表中的属性值(这在内存中比字典更紧凑)。该映射将从属性名称到索引的映射存储到该列表中。
对这种行为的简单测试如下所示:
def test_maps(): # white box test inspecting the implementation Point = Class(name="Point", base_class=OBJECT, fields={}, metaclass=TYPE) p1 = Instance(Point) p1.write_attr("x", 1) p1.write_attr("y", 2) assert p1.storage == [1, 2] assert p1.map.attrs == {"x": 0, "y": 1} p2 = Instance(Point) p2.write_attr("x", 5) p2.write_attr("y", 6) assert p1.map is p2.map assert p2.storage == [5, 6] p1.write_attr("x", -1) p1.write_attr("y", -2) assert p1.map is p2.map assert p1.storage == [-1, -2] p3 = Instance(Point) p3.write_attr("x", 100) p3.write_attr("z", -343) assert p3.map is not p1.map assert p3.map.attrs == {"x": 0, "z": 1}请注意,这是一个不同于我们之前写的测试。所有以前的测试刚刚通过暴露的接口测试了类的行为。该测试通过读取内部属性并将其与预定义值进行比较来检查
Instance类的实现细节。因此,这个测试称为白盒测试。p1映射的attrs属性将实例的布局描述为存储在p1的位置0和1处的两个属性“x”和“y”。第二个实例p2,以相同的顺序添加相同的属性将使其结束同一个地图。如果添加了不同的属性,则不能共享地图。Map类看起来像这样:class Map(object): def __init__(self, attrs): self.attrs = attrs self.next_maps = {} def get_index(self, fieldname): return self.attrs.get(fieldname, -1) def next_map(self, fieldname): assert fieldname not in self.attrs if fieldname in self.next_maps: return self.next_maps[fieldname] attrs = self.attrs.copy() attrs[fieldname] = len(attrs) result = self.next_maps[fieldname] = Map(attrs) return result EMPTY_MAP = Map({})Map有两种方法,
get_index和next_map。 前者是用于查找对象存储中的属性名称的索引。后者添加到新属性对象。这种情况下,对象需要使用next_map计算的不同映射。该方法使用next_maps字典来缓存已创建的地图。这样,具有相同布局的对象也使用相同的Map对象。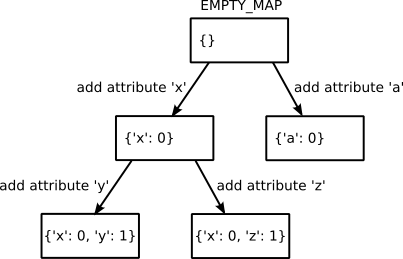
Instance代码如下:class Instance(Base): """Instance of a user-defined class. """ def __init__(self, cls): assert isinstance(cls, Class) Base.__init__(self, cls, None) self.map = EMPTY_MAP self.storage = [] def _read_dict(self, fieldname): index = self.map.get_index(fieldname) if index == -1: return MISSING return self.storage[index] def _write_dict(self, fieldname, value): index = self.map.get_index(fieldname) if index != -1: self.storage[index] = value else: new_map = self.map.next_map(fieldname) self.storage.append(value) self.map = new_map该类传递
None给Base,因为Instance将以另一种方式存储字典的内容。因此,它需要覆盖_read_dict和_write_dict方法。我们重构Base类,使其不再存储字段字典,但是现在的实例存储是不够的。新创建的实例使用没有属性的
EMPTY_MAP和空存储启动。要实现_read_dict,请求实例的映射关系到属性名称的索引。然后返回存储列表的相应条目。写入字典有两种情况。一方面可以改变现有属性的值。这是通过简单更改相应索引处的存储来完成的。另一方面,如果属性不存在,则需要使用
next_map方法进行映射转换(图14.2)。新属性的值附加到存储列表。这个优化实现了什么?在具有相同布局的实例常见情况下,它优化了内存使用。这不是一个通用的优化:使用不同的属性集创建实例的代码将会比仅使用字典占用更大的内存。
这是在优化动态语言中的常见问题。通常都不可能找到更快的内存或更少内存的优化。实践中,选择的优化适用于通用语言,同时可能使使用动态特征的程序更糟。
地图的另一个有趣的方面是,虽然在这里它们只是优化内存使用,但是在使用JIT编译器的实际虚拟机中,它们也提高了程序的性能。为了实现这一点,JIT使用地图编译属性查找,为在固定偏移量的对象存储中的查找,从而完全摆脱字典查找。
潜在扩展
很容易扩展我们的对象模型和实验各种语言设计。还有其他可能:
-
最简单的方法是添加更多的特殊方法。添加一些容易有趣的是
__init__,__getattribute__,__set__。 -
该模型可以非常容易地扩展支持多重继承。为了做到这一点,每个类都会得到一个基类列表。需要更改
Class.method_resolution_order方法来支持查找方法。可以使用深度优先搜索来删除重复项。更复杂但更好的是C3算法,它增加了菱形多重继承层次的基础,并拒绝了不可靠的继承模式。 -
根本的变化是切换到原模型,其中涉及删除类和实例之间的区别。
结论
面向对象编程语言设计的核心是其对象模型的细节。编写小对象模型原型是更好地了解现有语言的内部工作,并深入了解面向对象语言的设计。使用对象模型是尝试不同语言设计思想的好方法,而不必担心实现无聊的部分,如解析和执行代码。
这样的对象模型在实践中也是有用的,而不仅仅是实验的载体。它们可以嵌入其他语言并为其他语言中使用。这种方法的例子是很常见的:用于GLib和Gnome库中的用C编写的GObject对象模型;或JavaScript中的各种类系统实现。
引用
-
P. Cointe, “Metaclasses are first class: The ObjVlisp Model,” SIGPLAN Not, vol. 22, no. 12, pp. 156–162, 1987.↩
-
It seems that the attribute-based model is conceptually more complex, because it needs both method lookup and call. In practice, calling something is defined by looking up and calling a special attribute call, so conceptual simplicity is regained. This won’t be implemented in this chapter, however.)↩
-
G. Kiczales, J. des Rivieres, and D. G. Bobrow, The Art of the Metaobject Protocol. Cambridge, Mass: The MIT Press, 1991.↩
-
A. Goldberg, Smalltalk-80: The Language and its Implementation. Addison-Wesley, 1983, page 61.↩
-
In Python the second argument is the class where the attribute was found, though we will ignore that here.↩
-
C. Chambers, D. Ungar, and E. Lee, “An efficient implementation of SELF, a dynamically-typed object-oriented language based on prototypes,” in OOPSLA, 1989, vol. 24.↩
-
How that works is beyond the scope of this chapter. I tried to give a reasonably readable account of it in a paper I wrote a few years ago. It uses an object model that is basically a variant of the one in this chapter: C. F. Bolz, A. Cuni, M. Fijałkowski, M. Leuschel, S. Pedroni, and A. Rigo, “Runtime feedback in a meta-tracing JIT for efficient dynamic languages,” in Proceedings of the 6th Workshop on Implementation, Compilation, Optimization of Object-Oriented Languages, Programs and Systems, New York, NY, USA, 2011, pp. 9:1–9:8.↩
-
-
Leetcode 187 Repeated DNA Sequences
Leetcode 187. Repeated DNA Sequences
Leetcode 187. Repeated DNA Sequences
All DNA is composed of a series of nucleotides abbreviated as A, C, G, and T, for example: “ACGAATTCCG”. When studying DNA, it is sometimes useful to identify repeated sequences within the DNA.
Write a function to find all the 10-letter-long sequences (substrings) that occur more than once in a DNA molecule.
For example,
` Given s = “AAAAACCCCCAAAAACCCCCCAAAAAGGGTTT”,
Return: [“AAAAACCCCC”, “CCCCCAAAAA”]. `
思路:将字符串中所有长度为10的子串以及出现的次数用map保存,但是需要消耗很大的空间。
考虑到只有4中可能的字符A,C,G,T;可以对字符进行编码,用2bit来表示一个字符,一个含有10个字符的子串只要20bit就能表示,用一个int类型就能表示。
总长度为n的字符串,可能的子串共有n-9种,因此最多用n-9个int就能表示所有的字符组合。最坏的情况下,20bit共有2^20中组合,即1024*1024,
一个int类型4byte,因此额外消耗4MB的二外空间。
A : 0100 0001 C : 0100 0011 G : 0100 0111 T : 0101 0100Only the last three bits are different.
class Solution { public: // A65 C67 G71 T84 vector<string> findRepeatedDnaSequences(string s) { vector<string> res; unordered_map<int,int> table; const int n = s.size(); int curr = 0; for(int i = 0; i < n; i++){ curr <<= 3; //shift left 3 curr |= (s[i]&7); //Only the last three bits are different. curr &= 0x3FFFFFFF; if(i >= 9 && ++table[curr] == 2) res.push_back(s.substr(i-9,10)); } return res; } };
-
500 Lines or Less Chapter 13: A 3D Modeller 翻译
Erick是一名软件开发人员,2D和3D计算机图形爱好者。他曾从事视频游戏,3D特效软件和计算机辅助设计工具。涉及模拟现实后,他有机会想了解更多。你可以在erickdransch.com上找到他。
介绍
人类具有与生俱来的创意。我们不断设计和制作小说,有用和有趣的东西。在现代,我们编写软件来协助设计和制作过程。计算机辅助设计(CAD)软件允许创作者在实物建设之前设计建筑物,桥梁,视频游戏艺术,电影怪物,3D打印对象等等。
在其核心里,CAD工具是将三维设计抽象成可在二维屏幕上查看和编辑。为了实现这一定义,CAD工具必须提供三个基本功能。首先,必须有一个数据结构来表示正在设计的对象:这是计算机对用户正在构建的三维世界的理解。其次,CAD工具要提供一些在用户屏幕上显示设计的方法。用户正在设计一个具有三维尺寸的物理对象,但电脑屏幕只有二维。 CAD工具必须使我们能够对感知对象进行建模,并以用户可以了解对象的3个维度的方式将其绘制到屏幕上。第三,CAD工具必须提供一种与被设计对象交互的方式。用户必须能够添加和修改设计才能产生所需要的结果。此外,所有工具都需要一种从磁盘中保存和加载设计的方法,以便用户能够协作,共享和保存他们的工作。
域特定的CAD工具为域的特定要求提供了许多附加功能。例如,架构CAD工具将提供物理模拟来测试建筑物的气候应力,3D打印工具将检查物体是否真实有效打印,电气CAD工具将模拟通过铜线运行的电力物理并且电影特效套件,包括准确模拟火山动力学的特征。
然而,所有CAD工具必须至少包括上述三个功能:表示设计的数据结构,将其显示到屏幕的能力以及与设计交互的方法。
基于这个,让我们来看看如何在500行Python中代表3D设计,将其显示在屏幕上并与之进行交互。
渲染指南
3D建模器设计决策背后的驱动力是渲染过程。我们希望能够在设计中存储和渲染复杂的对象,但仍然保持渲染代码的复杂性。我们来看一下渲染过程,并探索需要设计的数据结构,使我们能够使用简单的渲染逻辑来存储和绘制任意复杂的对象。
管理接口和主环
在我们开始渲染之前,我们需要设置几个东西。首先,我们需要创建一个窗口来显示我们的设计。其次,我们想与图形驱动程序通信以呈现到屏幕。我们不直接与图形驱动程序通信,所以我们使用一个称为OpenGL的跨平台抽象层,以及一个名为GLUT(OpenGL Utility Toolkit)的库来管理我们的窗口。
关于OpenGL的注意事项
OpenGL是用于跨平台开发的图形应用程序编程接口。它是跨平台开发图形应用程序的标准API。 OpenGL有两个主要的变体:Legacy OpenGL和Modern OpenGL。
OpenGL中的渲染是基于顶点和法线定义的多边形。例如,要渲染立方体的一面,我们指定4个顶点和边的法线。
Legacy OpenGL提供了一个“固定功能管道”。通过设置全局变量,程序员可以启用和禁用诸如照明,着色,脸部剔除等功能的自动化实现。然后,OpenGL会自动使用启用的功能渲染场景。此功能已弃用。
另一方面,现代OpenGL具有可编程渲染管道,程序员编写在专用图形硬件(GPU)上运行的“着色器”小程序。 Modern OpenGL的可编程管道已经取代了Legacy OpenGL。
在这个项目中,尽管它已被弃用,但我们使用的是Legacy OpenGL。 Legacy OpenGL提供的固定功能对于保持代码大小很有用。它减少了所需的线性代数知识的数量,并简化了我们将要编写的代码。
关于GLUT
GLUT与OpenGL捆绑在一起,允许我们创建操作系统窗口并注册用户界面回调。这个基本功能足以满足我们的需求。如果我们想要一个更全面的窗口管理和用户交互的库,我们将考虑使用像GTK或Qt这样的全面的窗口工具包。
Viewer
要管理GLUT和OpenGL的设置,并且驱动其他模型,我们创建一个名为
Viewer的类。我们使用Viewer实例,它管理窗口创建和渲染,并包含我们程序的主循环。在Viewer的初始化过程中,我们创建了GUI窗口并初始化了OpenGL。函数
init_interface创建窗口,该模型将被渲染,并指定要在设计需要呈现时调用的函数。init_opengl函数设置项目所需的OpenGL状态。它设置矩阵,剔除背面,注册光照亮场景,并告诉OpenGL我们希望对象被着色。init_scene函数创建Scene对象并放置一些初始节点以使用户启动。我们稍后会看到有关Scene数据结构的更多信息。最后,init_interaction注册用户交互的回调,我们将在后面讨论。class Viewer(object): def __init__(self): """ Initialize the viewer. """ self.init_interface() self.init_opengl() self.init_scene() self.init_interaction() init_primitives() def init_interface(self): """ initialize the window and register the render function """ glutInit() glutInitWindowSize(640, 480) glutCreateWindow("3D Modeller") glutInitDisplayMode(GLUT_SINGLE | GLUT_RGB) glutDisplayFunc(self.render) def init_opengl(self): """ initialize the opengl settings to render the scene """ self.inverseModelView = numpy.identity(4) self.modelView = numpy.identity(4) glEnable(GL_CULL_FACE) glCullFace(GL_BACK) glEnable(GL_DEPTH_TEST) glDepthFunc(GL_LESS) glEnable(GL_LIGHT0) glLightfv(GL_LIGHT0, GL_POSITION, GLfloat_4(0, 0, 1, 0)) glLightfv(GL_LIGHT0, GL_SPOT_DIRECTION, GLfloat_3(0, 0, -1)) glColorMaterial(GL_FRONT_AND_BACK, GL_AMBIENT_AND_DIFFUSE) glEnable(GL_COLOR_MATERIAL) glClearColor(0.4, 0.4, 0.4, 0.0) def init_scene(self): """ initialize the scene object and initial scene """ self.scene = Scene() self.create_sample_scene() def create_sample_scene(self): cube_node = Cube() cube_node.translate(2, 0, 2) cube_node.color_index = 2 self.scene.add_node(cube_node) sphere_node = Sphere() sphere_node.translate(-2, 0, 2) sphere_node.color_index = 3 self.scene.add_node(sphere_node) hierarchical_node = SnowFigure() hierarchical_node.translate(-2, 0, -2) self.scene.add_node(hierarchical_node) def init_interaction(self): """ init user interaction and callbacks """ self.interaction = Interaction() self.interaction.register_callback('pick', self.pick) self.interaction.register_callback('move', self.move) self.interaction.register_callback('place', self.place) self.interaction.register_callback('rotate_color', self.rotate_color) self.interaction.register_callback('scale', self.scale) def main_loop(self): glutMainLoop() if __name__ == "__main__": viewer = Viewer() viewer.main_loop()在我们进入渲染函数之前,我们应该讨论一点线性代数。
坐标空间
坐标空间是一个起点和一组3个基矢量,通常是
x,y和z轴。点
3维中的任何点可以表示为原点的
x,y和z方向的偏移量。点是相对于点所在的坐标空间。同一点在不同坐标空间中具有不同的表示。任何三维坐标点都可以在任何三维坐标空间中表示。向量
向量是
x,y和z值,表示x,y和z轴之间的两个点之间的差异, 分别。转换矩阵
在计算机图形学中,为不同类型的点使用多个不同的坐标空间是方便的。变换矩阵将点从一个坐标空间转换到另一个坐标空间。将矢量
v从一个坐标空间转换为另一个,我们乘以一个变换矩阵M:=v'= M v。一些常见的转换矩阵比如平移,缩放和旋转。模型,世界,视图和投影坐标空间
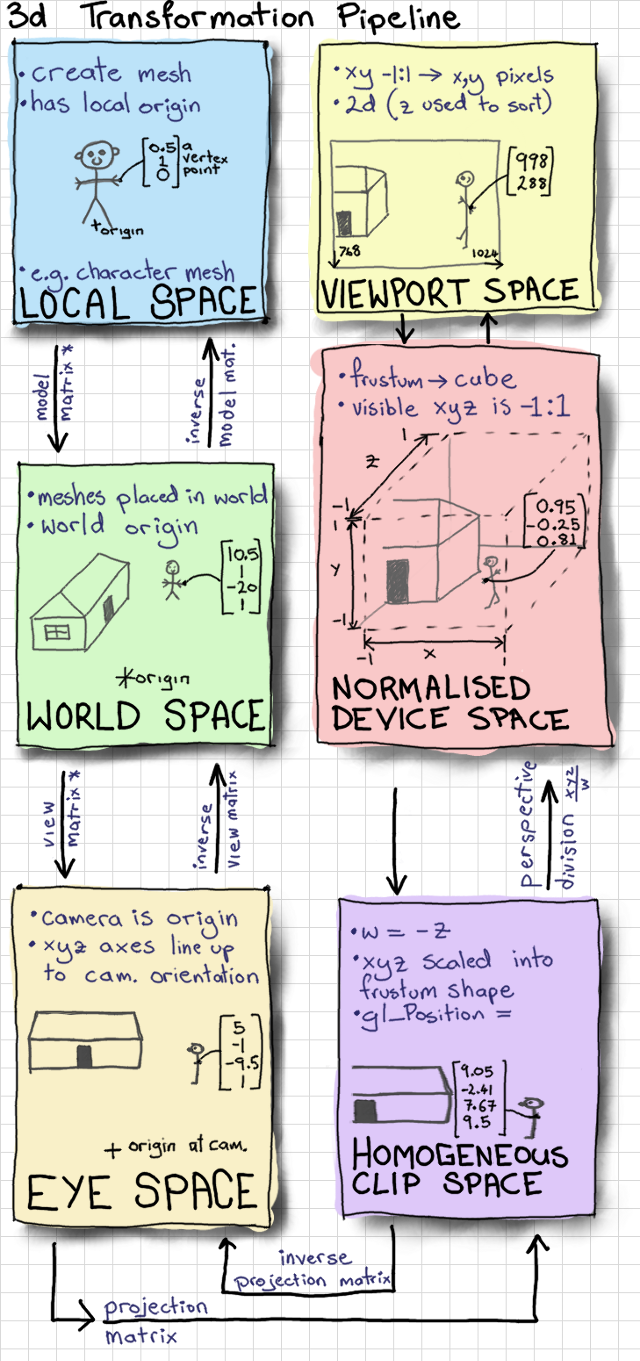
要画到屏幕上,我们需要在几个不同的坐标空间之间进行转换。
图13.1的右侧,包括从Eye Space到Viewport Space的所有转换都将由OpenGL处理。
通过
gluPerspective处理从eye space到均匀剪辑空间的转换,转换为归一化的设备空间和视口空间由glViewport处理。将这两个矩阵相乘并存储为GL_PROJECTION矩阵。我们不需要知道这些矩阵如何为此项目工作的术语或细节。但是,我们需要管理图表的左侧。我们定义一个将模型中的点(也称为网格)从模型空间转换为世界空间的矩阵,称为模型矩阵。我们定义了将视图矩阵从世界空间转换为眼睛空间。在这个项目中,我们组合了这两个矩阵来获得
ModelView矩阵。要了解更多有关完整图形渲染流水线和所涉及的坐标空间的信息,请参阅实时渲染的第2章或其他计算机图形图书。
用Viewer渲染
render函数从设置渲染时需要完成的任何OpenGL状态开始。它通过init_view初始化投影矩阵,并使用交互成员的数据通过从场景空间转换为世界空间的变换矩阵来初始化ModelView矩阵。我们将在下面看到有关“交互”类的更多信息。它使用glClear清除屏幕,并告诉现场渲染自身,然后渲染单元格。在渲染网格之前禁用OpenGL的照明。禁用照明后,OpenGL会渲染纯色的物品,而不是模拟光源。这样,网格与场景有视觉差异。最后,
glFlush信号到图形驱动程序,我们准备好缓冲区被刷新并显示到屏幕上。# class Viewer def render(self): """ The render pass for the scene """ self.init_view() glEnable(GL_LIGHTING) glClear(GL_COLOR_BUFFER_BIT | GL_DEPTH_BUFFER_BIT) # Load the modelview matrix from the current state of the trackball glMatrixMode(GL_MODELVIEW) glPushMatrix() glLoadIdentity() loc = self.interaction.translation glTranslated(loc[0], loc[1], loc[2]) glMultMatrixf(self.interaction.trackball.matrix) # store the inverse of the current modelview. currentModelView = numpy.array(glGetFloatv(GL_MODELVIEW_MATRIX)) self.modelView = numpy.transpose(currentModelView) self.inverseModelView = inv(numpy.transpose(currentModelView)) # render the scene. This will call the render function for each object # in the scene self.scene.render() # draw the grid glDisable(GL_LIGHTING) glCallList(G_OBJ_PLANE) glPopMatrix() # flush the buffers so that the scene can be drawn glFlush() def init_view(self): """ initialize the projection matrix """ xSize, ySize = glutGet(GLUT_WINDOW_WIDTH), glutGet(GLUT_WINDOW_HEIGHT) aspect_ratio = float(xSize) / float(ySize) # load the projection matrix. Always the same glMatrixMode(GL_PROJECTION) glLoadIdentity() glViewport(0, 0, xSize, ySize) gluPerspective(70, aspect_ratio, 0.1, 1000.0) glTranslated(0, 0, -15)渲染:场景
现在我们已经初始化了渲染管线来处理世界坐标空间中的绘图,我们要渲染什么?回想一下,我们的目标是设计一个3D模型组成的设计。我们需要一个数据结构来包含设计,使用这个数据结构渲染设计。注意上面我们从Viewer的渲染循环中调用
self.scene.render()。 什么是场景?Scene类是我们用于表示设计的数据结构的接口。它记录数据结构的细节,并提供与设计交互所需的必要接口功能,包括渲染,添加项目和操作项目的功能。Scene对象,由Viewer拥有。场景实例保留场景中所有项目的列表node_list。它还跟踪所选的项目。场景上的渲染功能在node_list的每个成员上调用渲染。class Scene(object): # the default depth from the camera to place an object at PLACE_DEPTH = 15.0 def __init__(self): # The scene keeps a list of nodes that are displayed self.node_list = list() # Keep track of the currently selected node. # Actions may depend on whether or not something is selected self.selected_node = None def add_node(self, node): """ Add a new node to the scene """ self.node_list.append(node) def render(self): """ Render the scene. """ for node in self.node_list: node.render()节点
在场景
render功能中,我们在Scene的node_list中的每个项目上调用渲染。但这个列表的元素有什么?我们称之为节点。概念上,节点是可以放置在场景中的任何东西。在面向对象的软件中,我们将Node作为抽象基类编写。任何表示要放置在场景中的对象的类都将从Node继承。它让我们可以抽象地讲解场景。代码库的其余部分不需要知道它显示的对象的细节;它只需要知道它们是类Node。每种类型的
Node定义自己的渲染本身和任何其他交互的行为。节点跟踪自身的重要数据:平移矩阵,比例矩阵,颜色等。通过其缩放矩阵乘以节点的平移矩阵,给出从节点的模型坐标空间到世界坐标空间的变换矩阵。该节点还存储一个轴对齐的边界框(AABB)。当我们在下面讨论选择时,我们将看到有关AABB的更多信息。Node的简单实现是一个原语。原始图案可以添加场景的单一实体形状。在这个项目中,原语是Cube和Sphere。class Node(object): """ Base class for scene elements """ def __init__(self): self.color_index = random.randint(color.MIN_COLOR, color.MAX_COLOR) self.aabb = AABB([0.0, 0.0, 0.0], [0.5, 0.5, 0.5]) self.translation_matrix = numpy.identity(4) self.scaling_matrix = numpy.identity(4) self.selected = False def render(self): """ renders the item to the screen """ glPushMatrix() glMultMatrixf(numpy.transpose(self.translation_matrix)) glMultMatrixf(self.scaling_matrix) cur_color = color.COLORS[self.color_index] glColor3f(cur_color[0], cur_color[1], cur_color[2]) if self.selected: # emit light if the node is selected glMaterialfv(GL_FRONT, GL_EMISSION, [0.3, 0.3, 0.3]) self.render_self() if self.selected: glMaterialfv(GL_FRONT, GL_EMISSION, [0.0, 0.0, 0.0]) glPopMatrix() def render_self(self): raise NotImplementedError( "The Abstract Node Class doesn't define 'render_self'") class Primitive(Node): def __init__(self): super(Primitive, self).__init__() self.call_list = None def render_self(self): glCallList(self.call_list) class Sphere(Primitive): """ Sphere primitive """ def __init__(self): super(Sphere, self).__init__() self.call_list = G_OBJ_SPHERE class Cube(Primitive): """ Cube primitive """ def __init__(self): super(Cube, self).__init__() self.call_list = G_OBJ_CUBE渲染节点是基于每个节点存储的转换矩阵。节点的变换矩阵是其缩放矩阵及其平移矩阵的组合。无论节点类型,渲染的第一步是将OpenGL ModelView矩阵设置为转换矩阵,从模型坐标空间转换为视图坐标空间。一旦OpenGL矩阵是最新的,我们调用render_self来告诉节点进行必要的OpenGL调用来绘制自己。最后,我们撤消对该特定节点对OpenGL状态所做的任何更改。我们在OpenGL中使用
glPushMatrix和glPopMatrix函数来保存并恢复渲染节点之前和之后的ModelView矩阵的状态。请注意,节点存储其颜色,位置和比例,并在渲染之前将其应用于OpenGL状态。如果当前节点被选中,我们使它发光。这样,用户就可以看到他们选择了哪一个节点。
要渲染图元,我们使用OpenGL中的调用列表功能。 OpenGL调用列表有一系列OpenGL调用,它们被定义一次,并以单个名称捆绑在一起。可以使用
glCallList(LIST_NAME)发送呼叫。每个基元(Sphere和Cube)定义了渲染所需的调用列表。例如,多维数据集的调用列表绘制多维数据集的6个面,其中心在原点和边缘恰好为1个单位长。
# Pseudocode Cube definition # Left face ((-0.5, -0.5, -0.5), (-0.5, -0.5, 0.5), (-0.5, 0.5, 0.5), (-0.5, 0.5, -0.5)), # Back face ((-0.5, -0.5, -0.5), (-0.5, 0.5, -0.5), (0.5, 0.5, -0.5), (0.5, -0.5, -0.5)), # Right face ((0.5, -0.5, -0.5), (0.5, 0.5, -0.5), (0.5, 0.5, 0.5), (0.5, -0.5, 0.5)), # Front face ((-0.5, -0.5, 0.5), (0.5, -0.5, 0.5), (0.5, 0.5, 0.5), (-0.5, 0.5, 0.5)), # Bottom face ((-0.5, -0.5, 0.5), (-0.5, -0.5, -0.5), (0.5, -0.5, -0.5), (0.5, -0.5, 0.5)), # Top face ((-0.5, 0.5, -0.5), (-0.5, 0.5, 0.5), (0.5, 0.5, 0.5), (0.5, 0.5, -0.5))仅使用原语将对建模应用程序是非常有限的。 3D模型通常由多个原语(或三角形网格组成,不在本项目范围之内)。幸运的是,我们对
Node类的设计有助于由多个基元组成的Scene节点。事实上,我们可以支持任意分组的节点,而不增加复杂度。作为动机,让我们考虑一个非常基本的人物:一个典型的雪人,或者是由三个球体组成的积雪人物。即使该图由三个独立的图元组成,我们希望将其视为单个对象。
我们创建
HierarchicalNode类,一个包含其他节点的Node。它管理一个“孩子”的列表。分层节点的render_self函数简单地在每个子节点上调用render_self。使用HierarchicalNode类,很容易将数字添加到场景中。现在,定义雪景就像指定构成它的形状一样简单,它们的相对位置和大小。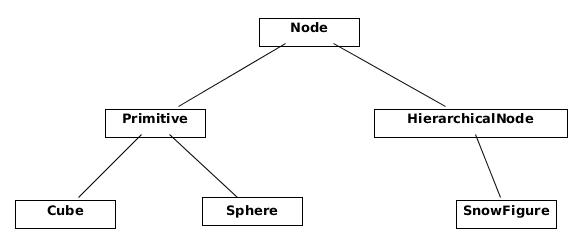
class HierarchicalNode(Node): def __init__(self): super(HierarchicalNode, self).__init__() self.child_nodes = [] def render_self(self): for child in self.child_nodes: child.render()class SnowFigure(HierarchicalNode): def __init__(self): super(SnowFigure, self).__init__() self.child_nodes = [Sphere(), Sphere(), Sphere()] self.child_nodes[0].translate(0, -0.6, 0) # scale 1.0 self.child_nodes[1].translate(0, 0.1, 0) self.child_nodes[1].scaling_matrix = numpy.dot( self.scaling_matrix, scaling([0.8, 0.8, 0.8])) self.child_nodes[2].translate(0, 0.75, 0) self.child_nodes[2].scaling_matrix = numpy.dot( self.scaling_matrix, scaling([0.7, 0.7, 0.7])) for child_node in self.child_nodes: child_node.color_index = color.MIN_COLOR self.aabb = AABB([0.0, 0.0, 0.0], [0.5, 1.1, 0.5])您可能会观察到
Node对象形成树状数据结构。渲染函数通过分层节点通过树进行深度优先遍历。当它遍历时,它保存一堆ModelView矩阵,用于转换到世界空间。在每个步骤中,它将当前的ModelView矩阵推送到堆栈上,当它完成所有子节点的渲染时,它将矩阵从堆栈中弹出,将父节点的ModelView矩阵留在堆栈的顶部。通过以这种方式使
Node类可扩展,我们可以在场景中添加新的形状类型,而无需更改场景操纵和渲染的其他代码。使用节点概念来抽象出一个Scene对象可能有许多孩子,称为复合设计模式。用户互动
现在我们的建模者能够存储和显示场景,我们需要一种与之交互的方式。有两种类型的互动,首先,我们需要改变现场观看视角的能力。我们希望能够围绕现场移动眼睛或相机。其次,我们需要能够添加新节点并修改场景中的节点。
为了使用户交互,我们需要知道用户何时按键或移动鼠标。幸运的是,操作系统已经知道这些事件何时发生。 GLUT允许我们在某个事件发生时注册一个被调用的函数。我们编写功能来解释按键和鼠标移动,并在按下相应的键时告诉GLUT调用这些功能。一旦我们知道用户按下哪个键,我们需要解释输入并将预期的操作应用于现场。
用于监听操作系统事件和解释其含义的逻辑在
Interaction类中找到。我们之前写的Viewer类拥有Interaction的单个实例。当按下鼠标按钮(glutMouseFunc),鼠标移动时(glutMotionFunc),当按下键盘按钮(glutKeyboardFunc)时以及按下箭头键时,我们将使用GLUT回调机制来注册要调用的函数(glutSpecialFunc`)。稍后我们将看到处理输入事件的功能。class Interaction(object): def __init__(self): """ Handles user interaction """ # currently pressed mouse button self.pressed = None # the current location of the camera self.translation = [0, 0, 0, 0] # the trackball to calculate rotation self.trackball = trackball.Trackball(theta = -25, distance=15) # the current mouse location self.mouse_loc = None # Unsophisticated callback mechanism self.callbacks = defaultdict(list) self.register() def register(self): """ register callbacks with glut """ glutMouseFunc(self.handle_mouse_button) glutMotionFunc(self.handle_mouse_move) glutKeyboardFunc(self.handle_keystroke) glutSpecialFunc(self.handle_keystroke)操作系统回调
为了有意义地解释用户输入,我们需要结合鼠标位置,鼠标按钮和键盘的知识。因为将用户输入有意义的动作需要许多代码行,所以我们将其封装在一个单独的类中,远离主代码路径。
Interaction类隐藏了与代码库其余部分无关的复杂性,并将操作系统事件转换为应用程序级事件。# class Interaction def translate(self, x, y, z): """ translate the camera """ self.translation[0] += x self.translation[1] += y self.translation[2] += z def handle_mouse_button(self, button, mode, x, y): """ Called when the mouse button is pressed or released """ xSize, ySize = glutGet(GLUT_WINDOW_WIDTH), glutGet(GLUT_WINDOW_HEIGHT) y = ySize - y # invert the y coordinate because OpenGL is inverted self.mouse_loc = (x, y) if mode == GLUT_DOWN: self.pressed = button if button == GLUT_RIGHT_BUTTON: pass elif button == GLUT_LEFT_BUTTON: # pick self.trigger('pick', x, y) elif button == 3: # scroll up self.translate(0, 0, 1.0) elif button == 4: # scroll up self.translate(0, 0, -1.0) else: # mouse button release self.pressed = None glutPostRedisplay() def handle_mouse_move(self, x, screen_y): """ Called when the mouse is moved """ xSize, ySize = glutGet(GLUT_WINDOW_WIDTH), glutGet(GLUT_WINDOW_HEIGHT) y = ySize - screen_y # invert the y coordinate because OpenGL is inverted if self.pressed is not None: dx = x - self.mouse_loc[0] dy = y - self.mouse_loc[1] if self.pressed == GLUT_RIGHT_BUTTON and self.trackball is not None: # ignore the updated camera loc because we want to always # rotate around the origin self.trackball.drag_to(self.mouse_loc[0], self.mouse_loc[1], dx, dy) elif self.pressed == GLUT_LEFT_BUTTON: self.trigger('move', x, y) elif self.pressed == GLUT_MIDDLE_BUTTON: self.translate(dx/60.0, dy/60.0, 0) else: pass glutPostRedisplay() self.mouse_loc = (x, y) def handle_keystroke(self, key, x, screen_y): """ Called on keyboard input from the user """ xSize, ySize = glutGet(GLUT_WINDOW_WIDTH), glutGet(GLUT_WINDOW_HEIGHT) y = ySize - screen_y if key == 's': self.trigger('place', 'sphere', x, y) elif key == 'c': self.trigger('place', 'cube', x, y) elif key == GLUT_KEY_UP: self.trigger('scale', up=True) elif key == GLUT_KEY_DOWN: self.trigger('scale', up=False) elif key == GLUT_KEY_LEFT: self.trigger('rotate_color', forward=True) elif key == GLUT_KEY_RIGHT: self.trigger('rotate_color', forward=False) glutPostRedisplay()内部回调
在上面的代码片段中,您将注意到,当
Interaction实例解释用户操作时,它会使用描述操作类型的字符串调用self.trigger。Interaction类的触发器函数是一个简单的回调系统的一部分,我们将用于处理应用程序级事件。 回想一下,Viewer类的init_interaction函数通过调用register_callback在Interaction`实例上注册回调。# class Interaction def register_callback(self, name, func): self.callbacks[name].append(func)当用户界面代码需要触发场景上的事件时,
Interaction类将调用该特定事件所有已保存的回调:# class Interaction def trigger(self, name, *args, **kwargs): for func in self.callbacks[name]: func(*args, **kwargs)该应用程序级回调系统抽象出需要系统的其余部分了解操作系统输入。每个应用程序级回调表示应用程序中有意义的请求。
Interaction类作为操作系统事件和应用程序级事件之间的翻译器。 这意味着如果我们决定将模板端口移植到GLUT之外的另一个工具包中,我们只需要将Interaction类替换为将新工具包的输入转换为同一组有意义的应用程序级回调的类。 我们在表13.1中使用回调和参数。Table 13.1 - Interaction callbacks and arguments
Callback Arguments Purpose pick x:number, y:number 选择鼠标指针位置处的节点 move x:number, y:number 将当前选定的节点移动到鼠标指针位置 place shape:string, x:number, y:number 在鼠标指针位置放置指定类型的形状 rotate_color forward:boolean 通过颜色列表向前或向后旋转当前所选节点的颜色 scale up:boolean 根据参数,将当前选定的节点向上或向下缩放这个简单的回调系统提供了我们所需的所有功能。然而,在生产3D建模器中,用户界面对象通常会被动态地创建和销毁。在这种情况下,我们需要一个更复杂的事件监听系统,其中对象可以注册和取消注册事件的回调。
场景交互
使用我们的回调机制,我们可以从
Interaction类接收有关用户输入事件的有意义的信息。我们准备好将这些动作以应用于场景。移动场景
在这个项目中,我们通过改变场景来完成相机运动。换句话说,相机位于固定位置,用户输入移动场景,而不是移动相机。相机放置在
[0,0,-15]并面向世界空间的起点。(或者,我们可以改变透视矩阵来移动相机而不是场景,这个设计对项目的其余部分影响很小)。在Viewer中的render函数,我们看到Interaction状态被用于在渲染Scene之前转换OpenGL矩阵状态。与场景的交互有两种类型:旋转和翻译。用轨迹球旋转场景
我们通过使用轨迹球算法来完成场景的旋转。轨迹球是三维操纵场景的直观界面。在概念上,轨迹球界面的功能就好像场景在透明球体内一样。将手放在地球表面并推动地球旋转。同样,单击鼠标右键并将其移动到屏幕上会旋转场景。您可以在OpenGL Wiki上找到关于轨迹球理论的更多信息。在这个项目中,我们使用Glumpy实现的轨迹球。
我们使用
drag_to函数与轨迹球交互,鼠标的当前位置作为起始位置,鼠标位置的变化作为参数。self.trackball.drag_to(self.mouse_loc[0], self.mouse_loc[1], dx, dy)当渲染场景时,得到的旋转矩阵是观察者中的
trackball.matrix。四元数
旋转传统上以两种方式之一表示。第一个是围绕每个轴的旋转值;您可以将其存储为3元组的浮点数。旋转的其他常见表示是四元数,由具有
x,y和z坐标的矢量和w旋转组成的元素。使用四元数比每轴旋转有许多好处;特别是它们在数值上更稳定。使用四元数避免诸如万向节锁等问题。不足之处在于它们不太直观,而且更难理解。如果你想了解更多关于四元数的话,可以参考这个解释。轨迹球实现通过在内部使用四元数来避免万向节锁定来存储场景的旋转。幸运的是,我们不需要直接使用四元数,因为轨迹球上的矩阵成员将旋转转换为矩阵。
变换场景
变换场景(即滑动)比旋转场景简单得多。场景翻译随鼠标滚轮和鼠标左键提供。鼠标左键翻译
x和y坐标中的场景。滚动鼠标滚轮将z坐标(朝向或远离相机)的场景转换。Interaction类存储当前的场景变换,并用translate函数进行修改。观看者在渲染期间检索交互摄像机位置,以在glTranslated呼叫中使用。选择场景对象
现在用户可以移动和旋转整个场景以获得他们想要的视角,下一步是允许用户修改和操作构成场景的对象。
为了让用户操作场景中的对象,他们需要能够选择项目。
要选择一个项目,我们使用当前投影矩阵来生成代表鼠标点击的光线,就像鼠标指针将光线射入场景一样。所选节点是与光线相交的相机的最靠近的节点。因此,选择的问题减少到在场景中的射线和节点之间发现交点的问题。所以问题是:我们如何判断光线是否击中一个节点?
准确计算射线是否与节点相交是代码和性能的复杂性方面的一个具有挑战性的问题。我们需要为每种类型写一个射线对象交集检查。对于具有许多面的具有复杂网格几何的场景节点,计算精确的光线对象交点将需要对每个面进行测试,并且在计算上是昂贵的。
为了保持代码紧凑和性能合理,我们使用一个简单,快速的近似来进行射线对象交叉测试。在我们的实现中,每个节点存储一个轴对齐的边界框(AABB),它是它所占据的空间的近似值。为了测试射线是否与节点相交,我们测试射线是否与节点的AABB相交。该实现意味着所有节点共享相同的代码用于交叉测试,这意味着对于所有节点类型,性能成本是恒定的和小的。
# class Viewer def get_ray(self, x, y): """ Generate a ray beginning at the near plane, in the direction that the x, y coordinates are facing Consumes: x, y coordinates of mouse on screen Return: start, direction of the ray """ self.init_view() glMatrixMode(GL_MODELVIEW) glLoadIdentity() # get two points on the line. start = numpy.array(gluUnProject(x, y, 0.001)) end = numpy.array(gluUnProject(x, y, 0.999)) # convert those points into a ray direction = end - start direction = direction / norm(direction) return (start, direction) def pick(self, x, y): """ Execute pick of an object. Selects an object in the scene. """ start, direction = self.get_ray(x, y) self.scene.pick(start, direction, self.modelView)要确定点击哪个节点,我们遍历场景来测试光线是否击中节点。我们取消选择当前选择的节点,然后选择具有最接近射线原点的交点的节点。
# class Scene def pick(self, start, direction, mat): """ Execute selection. start, direction describe a Ray. mat is the inverse of the current modelview matrix for the scene. """ if self.selected_node is not None: self.selected_node.select(False) self.selected_node = None # Keep track of the closest hit. mindist = sys.maxint closest_node = None for node in self.node_list: hit, distance = node.pick(start, direction, mat) if hit and distance < mindist: mindist, closest_node = distance, node # If we hit something, keep track of it. if closest_node is not None: closest_node.select() closest_node.depth = mindist closest_node.selected_loc = start + direction * mindist self.selected_node = closest_node在
Node类中,pick函数测试光线是否与Node轴对齐边界框相交。如果选择了节点,则select函数切换节点的选定状态。请注意,AABB的ray_hit函数以框的坐标空间和光线坐标空间之间的变换矩阵作为第三个参数。在调用ray_hit函数之前,每个节点将其变换应用于矩阵。# class Node def pick(self, start, direction, mat): """ Return whether or not the ray hits the object Consume: start, direction form the ray to check mat is the modelview matrix to transform the ray by """ # transform the modelview matrix by the current translation newmat = numpy.dot( numpy.dot(mat, self.translation_matrix), numpy.linalg.inv(self.scaling_matrix) ) results = self.aabb.ray_hit(start, direction, newmat) return results def select(self, select=None): """ Toggles or sets selected state """ if select is not None: self.selected = select else: self.selected = not self.selectedray-AABB选择方法非常易于理解和实现。但是,在某些情况下,结果是错误的。

例如,在
Sphere原语的情况下,球体本身仅触及每个AABB脸部中心的AABB。但是,点击球体的AABB的角落,如果用户想要点击“球体”后面的东西(图13.3),碰撞会被Sphere`检测到。在计算机图形学和软件工程的许多领域中,复杂度,性能和精度之间的这种折衷是常见的。
修改场景对象
接下来,我们希望允许用户操作所选节点。他们可能想要移动,调整大小或更改所选节点的颜色。 当用户输入操作节点的命令时,
Interaction类将输入转换为用户想要的动作,并调用相应的回调。当
Viewer收到这些事件的回调时,它会调用Scene的相应功能,该功能又将转换应用于当前选定的Node。# class Viewer def move(self, x, y): """ Execute a move command on the scene. """ start, direction = self.get_ray(x, y) self.scene.move_selected(start, direction, self.inverseModelView) def rotate_color(self, forward): """ Rotate the color of the selected Node. Boolean 'forward' indicates direction of rotation. """ self.scene.rotate_selected_color(forward) def scale(self, up): """ Scale the selected Node. Boolean up indicates scaling larger.""" self.scene.scale_selected(up)改变颜色
操作颜色通过颜色列表来完成。用户可以用箭头键循环浏览列表。场景将颜色更改命令分派到当前选定的节点。
# class Scene def rotate_selected_color(self, forwards): """ Rotate the color of the currently selected node """ if self.selected_node is None: return self.selected_node.rotate_color(forwards)每个节点存储其当前颜色。
rotate_color函数只是修改节点的当前颜色。渲染节点时,颜色将通过glColor传递给OpenGL。# class Node def rotate_color(self, forwards): self.color_index += 1 if forwards else -1 if self.color_index > color.MAX_COLOR: self.color_index = color.MIN_COLOR if self.color_index < color.MIN_COLOR: self.color_index = color.MAX_COLOR缩放节点
与颜色一样,场景将对所选节点分派缩放修改(如果有)。
# class Scene def scale_selected(self, up): """ Scale the current selection """ if self.selected_node is None: return self.selected_node.scale(up)每个节点存储存储其比例的当前矩阵。通过参数
x,y和z在这些方向上缩放的矩阵是:x 0 0 0 0 y 0 0 0 0 z 0 0 0 0 1当用户修改节点的比例时,所得到的缩放矩阵被乘以节点的当前缩放矩阵。
# class Node def scale(self, up): s = 1.1 if up else 0.9 self.scaling_matrix = numpy.dot(self.scaling_matrix, scaling([s, s, s])) self.aabb.scale(s)scaling函数返回矩阵,基于x,y和`z缩放倍数。def scaling(scale): s = numpy.identity(4) s[0, 0] = scale[0] s[1, 1] = scale[1] s[2, 2] = scale[2] s[3, 3] = 1 return s移动节点
为了变换节点,我们使用与picking相同的射线计算。我们将表示当前鼠标位置的光线传递到场景的移动功能。节点的新位置应该在光线上。为了确定射线放置节点的位置,我们需要知道节点与摄像机的距离。由于我们在选择节点的位置和距离相机时(在选择功能中)存储节点的位置和距离,所以可以在这里使用这些数据。我们发现与目标射线相机距离相同的点,计算新旧位置之间的向量差。然后,我们将结果向量转换为节点。
# class Scene def move_selected(self, start, direction, inv_modelview): """ Move the selected node, if there is one. Consume: start, direction describes the Ray to move to mat is the modelview matrix for the scene """ if self.selected_node is None: return # Find the current depth and location of the selected node node = self.selected_node depth = node.depth oldloc = node.selected_loc # The new location of the node is the same depth along the new ray newloc = (start + direction * depth) # transform the translation with the modelview matrix translation = newloc - oldloc pre_tran = numpy.array([translation[0], translation[1], translation[2], 0]) translation = inv_modelview.dot(pre_tran) # translate the node and track its location node.translate(translation[0], translation[1], translation[2]) node.selected_loc = newloc请注意,新位置和旧位置在相机坐标空间中的定义。我们需要在世界坐标空间变换中定义。因此,我们通过乘以
modelview矩阵的倒数将相机空间转换转换为世界空间转换。与缩放一样,每个节点存储表示其转换的矩阵。 翻译矩阵如下所示:
1 0 0 x 0 1 0 y 0 0 1 z 0 0 0 1当节点被变换时,我们为当前变换构造一个新的平移矩阵,并乘以节点的平移矩阵,以便在渲染中使用。
# class Node def translate(self, x, y, z): self.translation_matrix = numpy.dot( self.translation_matrix, translation([x, y, z]))translation函数返回一个给定表示x,y和z平移距离的列表的转换矩阵。def translation(displacement): t = numpy.identity(4) t[0, 3] = displacement[0] t[1, 3] = displacement[1] t[2, 3] = displacement[2] return t放置节点
节点放置使用来自picking和变换的技术。我们对当前的鼠标位置使用相同的射线计算来确定放置节点的位置。
# class Viewer def place(self, shape, x, y): """ Execute a placement of a new primitive into the scene. """ start, direction = self.get_ray(x, y) self.scene.place(shape, start, direction, self.inverseModelView)要放置一个新节点,我们首先创建相应节点类型的新实例并将其添加到场景中。将节点放在用户的光标下面,所以我们在距离相机一定距离的地方找到一个点。然后在相机空间中表示光线,因此我们将所得到的平移矢量通过乘以逆模型视图矩阵将其转换成世界坐标空间。最后,我们通过计算的向量来转换新节点。
# class Scene def place(self, shape, start, direction, inv_modelview): """ Place a new node. Consume: shape the shape to add start, direction describes the Ray to move to inv_modelview is the inverse modelview matrix for the scene """ new_node = None if shape == 'sphere': new_node = Sphere() elif shape == 'cube': new_node = Cube() elif shape == 'figure': new_node = SnowFigure() self.add_node(new_node) # place the node at the cursor in camera-space translation = (start + direction * self.PLACE_DEPTH) # convert the translation to world-space pre_tran = numpy.array([translation[0], translation[1], translation[2], 1]) translation = inv_modelview.dot(pre_tran) new_node.translate(translation[0], translation[1], translation[2])总结
恭喜! 我们已经成功实施了一个小型的3D建模器!

我们知道了如何开发可扩展的数据结构来表示场景中的对象。我们注意到,使用Composite设计模式和基于树的数据结构,可以轻松地遍历场景进行渲染,并允许我们添加新类型的节点,而不会增加复杂性。我们利用这种数据结构将设计渲染到屏幕上,并在遍历场景图中操作了OpenGL矩阵。我们为应用程序级事件构建了非常简单的回调系统,并将其用于封装操作系统事件的处理。我们讨论了射线对象碰撞检测的可能实现,以及正确性,复杂性和性能之间的权衡。最后,我们实现了操纵场景内容的方法。
您可以期待在生产3D软件中找到相同的基本构建块。场景图结构和相对坐标空间在许多类型的3D图形应用程序中被发现,从CAD工具到游戏引擎。该项目的一个主要简化是在用户界面中。开发我们看到了如何开发可扩展的数据结构来表示场景中的对象。我们注意到,使用Composite设计模式和基于树的数据结构,可以轻松地遍历场景进行渲染,并允许我们添加新类型的节点,而不会增加复杂性。我们利用这种数据结构将设计渲染到屏幕上,并在遍历场景图中操纵了OpenGL矩阵。我们为应用程序级事件构建了一个非常简单的回调系统,并将其用于封装操作系统事件的处理。我们讨论了射线对象碰撞检测的可能实现,以及正确性,复杂性和性能之间的权衡。最后,我们实现了操纵场景内容的方法。
您可以期待在生产3D软件中找到相同的基本构建块。场景图结构和相对坐标空间在许多类型的3D图形应用程序中被发现,从CAD工具到游戏引擎。该项目的一个主要简化是在用户界面中。预计生产的3D建模器将具有完整的用户界面,这将需要更复杂的事件系统,而不是简单的回调系统。
我们可以进一步的实验,为这个项目添加新功能。尝试以下方法之一:
-
添加
Node类型以支持任意形状的三角形网格。 -
添加一个撤消堆,以允许撤消/重做建模器动作。
-
使用DXF等3D文件格式保存/加载设计。
-
集成渲染引擎:导出设计以用于真实感渲染器。
-
用准确的射线对象交叉点改善碰撞检测。
进一步探索
为了进一步了解真实世界的3D建模软件,有些有趣的开源项目。
Blender是一款开源全功能3D动画套件。它提供了一个完整的3D管道,用于在视频中创建特效或创建游戏。建模器是该项目的一小部分,它是将模拟器集成到大型软件套件中的一个很好的例子。
OpenSCAD是一个开源的3D建模工具。它不是互动的而是读取一个指定如何生成场景的脚本文件。
-