Welcome to Shanshan Blog!
-
Spark Tutorial 1
It is note when reading Learn Spark
Spark Tutorial
```scala //start //绝对路径之前加上”file://” var files = sc.textFile(“file:///data/workspace/shanshan/test.md”) file.count() file.first()
//Chapter 3 RDD /* 弹性分布式数据集(RDD)。RDD 简单 来说就是元素的分布式集合。在 Spark 中,所有的工作都被表达为创建新 RDD, 对已存在的 RDD 做变换,或者对 RDD 调用某些操作来计算得到一个结果。在 底层,Spark 将包含在 RDD 中的数据自动分布到你的整个集群,并将你对其执 行的操作并行化。
用户可以用两种方式创建 RDD:通过加载一个外部数据集,或者在驱动程序中 分发一个对象集合(如 list 或 set)
RDD 一旦创建好了,可以提供两种不同类型的操作:变换(transformation)和动作 (action)。变换是从前一个 RDD 构造出一个新的 RDD。 */
// 创建RDD // 方式1: // 将你程序中已存在的集合传递给 SparkContext 的 parallelize()方法 val lines = sc.parallelize(List(“pandas”, “i like pandas”))
// 更常见的方式是从外部存储加载数据 var files = sc.textFile(“file:///data/workspace/shanshan/test.md”)
// RDD操作,看返回类型判断是动作还是变换(返回RDD) // 变换 var errors = files.filter(line=>line.contains(“errors”)) files.collect() // 动作 /* 它们是返回一个最终值给驱动程序或者写入外部存储系统的 操作。动作迫使对调用的 RDD 的变换请求进行求值,因为需要实际产生输出。 */
// 延迟求值 /* RDD 的变换是延迟求值,这意味着 Spark 直到看到一个动作才会进 行求值。*/
// 常用的RDD变换 /* map()变换传入 一个函数,并将该函数应用到 RDD 中的每一个元素。函数的返回结果就是变换 后的每个元素构成的新 RDD。filter()变换也是传入一个函数,返回的是该 RDD 中仅能通过该函数的元素构成的新 RDD。*/
// var, val, def /* def defines a method val defines a fixed value (which cannot be modified) var defines a variable (which can be modified) */ val input = sc.parallelize(List(1, 2, 3, 4)) val result = input.map(x => x * x) println(result.collect().mkString(“,”))
//flipMap 返回返回值的迭代器 lines = sc.parallelize([“hello world”, “hi”]) words = lines.flatMap(lambda line: line.split(“ “)) words.first() # returns “hello”
// 伪集合操作 // 笛卡尔积,返回所有可能组合
// reduce 函数 /* 它传入一个函数,该函数对 RDD 中两个元素进行处理,并返回一个同类型的元素。*/ val sum = rdd.reduce((x, y) => x + y)
/* fold()函数和 reduce()函数类似,也是带了一个和 reduce()相同的函数参数,但是 多了一个“零值”用于在每个分区调用时初始化。
aggregate()函数将我们从被约束只能返回处理的 RDD 的相同类型 RDD 中解脱 了。aggregate()和 fold()一样有一个初始的零值,但是可以是我们想要返回的类型。 */
val result = input.aggregate((0, 0))( (acc, value) => (acc._1 + value, acc._2 + 1), (acc1, acc2) => (acc1._1 + acc2._1, acc1._2 + acc2._2)) val avg = result._1 / result._2.toDouble
//数据到驱动程序 /* 最简单最常用的返回数据到驱动程序的操作是 collect(),返回整个 RDD 的数据。 take(n)返回 RDD 中的 n 个元素,试图最小化访问的分区的数目。所以它返回的 是有偏差的集合。重要的是知道这操作不会以你期待的顺序返回数据 */
/* 为避免多次计算同一个 RDD,我们可以要求 Spark 缓存该数据。当我们要求 Spark 缓存该 RDD 时,计算该 RDD 的节点都会保存它们的分区。*/ //使用persist
val result = input.map(x => x * x) result.persist(StorageLevel.DISK_ONLY) println(result.count()) println(result.collect().mkString(“,”))
-
计算广告学 笔记4.1 竞价广告系统
课程地址:计算广告学
课时19 位置拍卖理论
对于Supply来讲,竞价与合约一个明显的不同是竞价广告已经不再保证量的下限了,只能保证质。
竞价系统理论

定价机制
定价机制即决定一个广告位上的广告应该收取多少费用。从理论上讲,最优的应该是VCG(Vickrey-Clarke-Groves)机制,某对象的收费等于给别人带来的价值损害

举例来讲,如果你出价为5元,要在排在第2位。VCG是假设在你没有出价的情况下,那么以前排第3位的现在会排到第2位,以前第4位的会排到第3位,以此类推,那第3位以后的广告主的价值会受到影响,因为越向后,广告位的点击率越小,那么VCG定价机制就是收取所有广告主受到损害的价值之和,与你的出价无关。研究表明这种机制是最容易让系统达到稳定的机制,并且可以让整体市场是truth-telling的,truth-telling以CPC为例,如果一个广告主认为一次点击带给他的10元的价值,那么他为点击出价10元是一个占优策略(当然一次点击不可能扣10元),这样他就不用经常修改他的出价。
在实际系统中广泛使用的是第二高价(Second pricing)机制:
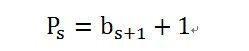
举例,一个广告主出价是5元,排在第2位,排在第3位的广告主出价是3元。如果是直接按出价扣费,那么广告主就有动力在广告在第2位不变的情况下将出价改低,一直改到3.01元,这样能保证付费最少,而在第二高价机制,那么排在第2位的广告主只会扣费3.01元,即使他改变出价到4元或是3.01元之类的出价,他的扣费都是3.01元,所以他就没有动力修改出价。与VCG机制相比,可以证明是会收取广告主更多的费用,这也是广告系统不愿采VCG机制的原因之一,整个市场不是truth-telling的,即广告主还是有调出价的动力,这就是SEM公司存在的原因。广告系统不愿使用VCG的另一原因是VCG机制比较复杂,而第二高价简单易行,为在线广告系统广泛采用。
课时20 广告网络概念
这里我们暂时只关注竞价机制下的广告网络。
Wiki中对广告网络的定义,Connects advertisers to web sites that want to host advertisement,这是一个非常泛的定义,广告网络的主要特征有:
-
竞价系统(Auction System),有一个以质优化的销售系统,根据价格销售广告位。
-
淡化广告位概念,广告网络是将多个网站的广告位收集后卖给广告主,广告网络在淡化广告位的概念,它向广告主卖的是人群。媒体中有优质广告位和劣质广告位,广告网络可以通过淡化广告位对人群打包进行售卖。
-
最合适的计价方式为CPC,这是因为广告位有优劣之分,如果按CPM,广告主会很难估计一次展示的价值。
-
它的不足是不易支持定制化用户划分,因为购买的关键词一般都是广告网络中有的一些关键词,广告主也需要对他想购买的关键词尝试分词后购买,但关键词有时无法准确地表达广告主想购买的人群,比如“想去日本旅游的人”,广告主无法在广告网络中做到购买自己的人群,这就是催生实时竞价的原因。
Ad Network系统架构
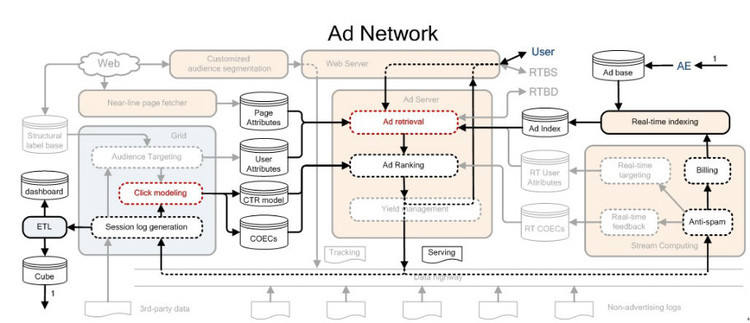
首先User的访问会到Retrieval模块,它从索取中取得用户的标签,页面的标签,和符合需求的相应广告,这些广告交给Ranking模块,Ranking做CTR估计,计算eCPM后,选出最好的广告,它的日志会进入Hadoop后优化点击率模型。日志还会进入线上流式计算平台,流式计算平台上会进行反作弊分析,计费模块,如果在计费模块发现用户预算已经用完,会经过实时索引模块将用户广告下线。
-
-
Linux Command Backup
- User
- Structure
- linux command review
- 列出所有信号
- 找到名字后,kill
- 或者用ps找到
- kill同名进程
- 每隔一秒高亮显示网络链接数的变化情况
- 启动关闭制定网卡
- 关闭网卡并修改MAC地址
- 配置IP地址
- 显示当前路由器
- 添加网关
- 删除网关
- 下载到本地
- 显示TCP连接
- socket 摘要
- 列出所有打开的网络连接端口
- 显示所有UDP Sockets
User
- create an account
useradd shanshan- delete an account
userdel shanshan- Get the errors
creating mailbox fiel:file exists, you should :
userdel -r shanshan sudo useradd -d /shanshan/test -m shan- update password
sudo passwd shan- check users
w who- shift user
su shan- errors: shans is not in the sudoers file
check the sudoers location
whereis sudoers chmod u+w /etc/sudoers在root ALL=(ALL)ALL行下添加 shan ALL=(ALL)ALL
还原权限
chmod u-w /etc/sudoers- swift the user
exitStructure
/bin:
bin是Binary的缩写, 这个目录存放着最经常使用的命令。
/boot:
这里存放的是启动Linux时使用的一些核心文件,包括一些连接文件以及镜像文件。
/dev :
dev是Device(设备)的缩写, 该目录下存放的是Linux的外部设备,在Linux中访问设备的方式和访问文件的方式是相同的。
/etc:
这个目录用来存放所有的系统管理所需要的配置文件和子目录。
/home:
用户的主目录,在Linux中,每个用户都有一个自己的目录,一般该目录名是以用户的账号命名的。
/lib:
这个目录里存放着系统最基本的动态连接共享库,其作用类似于Windows里的DLL文件。几乎所有的应用程序都需要用到这些共享库。
/lost+found:
这个目录一般情况下是空的,当系统非法关机后,这里就存放了一些文件。
/media:
linux系统会自动识别一些设备,例如U盘、光驱等等,当识别后,linux会把识别的设备挂载到这个目录下。
/mnt:
系统提供该目录是为了让用户临时挂载别的文件系统的,我们可以将光驱挂载在/mnt/上,然后进入该目录就可以查看光驱里的内容了。
/opt:
这是给主机额外安装软件所摆放的目录。比如你安装一个ORACLE数据库则就可以放到这个目录下。默认是空的。
/proc:
这个目录是一个虚拟的目录,它是系统内存的映射,我们可以通过直接访问这个目录来获取系统信息。
这个目录的内容不在硬盘上而是在内存里,我们也可以直接修改里面的某些文件,比如可以通过下面的命令来屏蔽主机的ping命令,使别人无法ping你的机器:
echo 1 > /proc/sys/net/ipv4/icmp_echo_ignore_all
/root:
该目录为系统管理员,也称作超级权限者的用户主目录。
/sbin:
s就是Super User的意思,这里存放的是系统管理员使用的系统管理程序。
/selinux:
这个目录是Redhat/CentOS所特有的目录,Selinux是一个安全机制,类似于windows的防火墙,但是这套机制比较复杂,这个目录就是存放selinux相关的文件的。
/srv:
该目录存放一些服务启动之后需要提取的数据。
/sys:
这是linux2.6内核的一个很大的变化。该目录下安装了2.6内核中新出现的一个文件系统 sysfs 。
sysfs文件系统集成了下面3种文件系统的信息:针对进程信息的proc文件系统、针对设备的devfs文件系统以及针对伪终端的devpts文件系统。
该文件系统是内核设备树的一个直观反映。
当一个内核对象被创建的时候,对应的文件和目录也在内核对象子系统中被创建。
/tmp:
这个目录是用来存放一些临时文件的。
/usr:
这是一个非常重要的目录,用户的很多应用程序和文件都放在这个目录下,类似与windows下的program files目录。
/usr/bin:
系统用户使用的应用程序。
/usr/sbin:
超级用户使用的比较高级的管理程序和系统守护程序。
/usr/src:
内核源代码默认的放置目录。
/var:
这个目录中存放着在不断扩充着的东西,我们习惯将那些经常被修改的目录放在这个目录下。包括各种日志文件。
linux command review
lsls -a ls -all # all files and directory ls -l -R # 当前目录下t开头的内容 ls -l t** # 当前目录的所有文件的绝对路径,目录不递归 find $PWD -maxdepth 1 | xargs ls -ld #当前目录的所有文件的绝对路径,目录递归 find $PWD | xargs ls -ldcdcd data/workspace cd -mkdir# 递归生成多个文件夹 mkdir -p test/test # 赋予777权限生成文件夹 mkdir -m 777 test2 #777:rwxrwxrwxrmrm -r -f test.crmdir删除非空目录rmdir test rmdir -p test # 如果删除后它变成了非空目录,那么也递归一并删除mv改名和移动文件mv test.c test2.c mv test2.c test2 # 所有文件移动到上级目录 mv * ..cp复制文件或目录# 文件 cp test2.c test2 # 整个文件夹下的东西 cp test2 testtouch# 新建一个文件 touch test3.c # 修改时间戳相等 touch test2.c test3.c llcatcat test2.c # 文件添加到后面 cat -n test2.c test3.cnl显示行号nl test2.cmore命令,功能类似cat,cat命令是整个文件的内容从上到下显示在屏幕上。 more会以一页一页的显示方便使用者逐页阅读,而最基本的指令就是按空白键(space)就往下一页显示,按b键就会往回(back)一页显示,而且还有搜寻字串的功能 。more test2.c # 每屏显示2行代码 more -2 test2.cless和more功能一样,但更强大
head和tail# 显示前两行和后两行 head -n 2 test2.c tail -n 2 test2.c # 前两个字节 head -c 2 test2.cwhich找到可执行文件的位置which ls which cd #找不到cd命令,因为cd是bash内置的命令whereis命令只能用于程序名的搜索,而且只搜索二进制文件(参数-b)、man说明文件(参数-m)和源代码文件(参数-s)。如果省略参数,则返回所有信息。 和find相比,whereis查找的速度非常快,这是因为linux系统会将 系统内的所有文件都记录在一个数据库文件中,当使用whereis和下面即将介绍的locate时,会从数据库中查找数据,而不是像find命令那样,通过遍历硬盘来查找,效率自然会很高。 但是该数据库文件并不是实时更新,默认情况下时一星期更新一次,因此,我们在用whereis和locate查找文件时,有时会找到已经被删除的数据,或者刚刚建立文件,却无法查找到,原因就是因为数据库文件没有被更新。find目录下查找find -atime -1 # 1天内修改过的文件 find . -name "*.c"chmod命令权限范围:
-
u :目录或者文件的当前的用户
-
g :目录或者文件的当前的群组
-
o :除了目录或者文件的当前用户或群组之外的用户或者群组
-
a :所有的用户及群组
权限代号:
-
r :读权限,用数字4表示
-
w :写权限,用数字2表示
-
x :执行权限,用数字1表示
-
- :删除权限,用数字0表示
- s :特殊权限
# 新增可执行权限 chmod u+x test2.c # 同时修改权限 chmod ug+w,o-x log2012.log chmod 751 test2.c # 给file的属主分配读、写、执行(7)的权限,给file的所在组分配读、执行(5)的权限,给其他用户分配执行(1)的权限tar打包仅打包,不压缩!
tar -cvf test2.tar test2.c # 打包后,以 gzip 压缩 tar -zcvf test2.gz test2.c # 打包后,以 bzip2 压缩 tar -zcvf test2.bz2 test2.cchgrp改变群组chown确定群组gzip压缩和解压# 文件夹下所有文件都压缩 gzip * # 解压所有 gzip -dv * # 递归得压缩目录 gzip -rv test6df查看磁盘使用情况dfdu查看所占用的空间du du test2.c du test2ln建立超链接ln是linux中又一个非常重要命令,它的功能是为某一个文件在另外一个位置建立一个同步的链接.# 软连接 ln -s test2.c linktest # 硬链接 ln test2.c linktestdiff比较文件diff test2.c test3.c # 上下文的格式输出 diff test2.c test3.c -c # 比较文件夹 diff test2 testdate命令date date '+%c' date '+%D' date '+%x' date '+%T' date '+%X'cal日历cal cal -y 2013grep正则表达式grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹 配的行打印出来。# 文件中查找关键词 grep 'linux' test.txt # 多个文件中查看关键词 grep 'linux' test.txt test2.txt # u开头的内容 cat test.txt |grep ^u # hat结尾的内容 cat test.txt |grep hat$wcWord Count 命令的功能为统计指定文件中的字节数、字数、行数,并将统计结果显示输出。-c 统计字节数。
-l 统计行数。
-m 统计字符数。这个标志不能与 -c 标志一起使用。
-w 统计字数。一个字被定义为由空白、跳格或换行字符分隔的字符串。
-L 打印最长行的长度。
-help 显示帮助信息
–version 显示版本信息
wc test.txtpsProcess Status的缩写。ps命令用来列出系统中当前运行的那些进程。ps -A # 指定用户进程 ps -u root # ps 与grep 常用组合用法,查找特定进程 ps -ef|grep ssh `kill`列出所有信号
kill -l
找到名字后,kill
kill -l name
或者用ps找到
kill 3268 #彻底杀死 kill -9 3268
`killall`kill同名进程
killall vi
`top`命令是Linux下常用的性能分析工具,能够实时显示系统中各个进程的资源占用状况,类似于Windows的任务管理器。top
`free`命令可以显示Linux系统中空闲的、已用的物理内存及swap内存,及被内核使用的buffer。free
`watch`可以帮你监测一个命令的运行结果,省得你一遍遍的手动运行每隔一秒高亮显示网络链接数的变化情况
watch -n 1 -d netstat -ant
`lsof`(list open files)是一个列出当前系统打开文件的工具。在linux环境下,任何事物都以文件的形式存在,通过文件不仅仅可以访问常规数据,还可以访问网络连接和硬件。 `ifconfig` 许多windows非常熟悉ipconfig命令行工具,它被用来获取网络接口配置信息并对此进行修改。Linux系统拥有一个类似的工具,也就是ifconfig(interfaces config)。ifconfig
启动关闭制定网卡
ifconfig eth0 up ifconfig eth0 down
关闭网卡并修改MAC地址
ifconfig eth0 hw ether 00:50:56:BF:26:20
配置IP地址
ifconfig eth0 192.168.120.56
`route` 显示和操作IP路由表显示当前路由器
route
添加网关
route add -net 224.0.0.0 netmask 240.0.0.0 dev eth0
删除网关
route del -net 224.0.0.0 netmask 240.0.0.0
`ping` 测试与目标主机的连通性ping 192.168.120.205
`traceroute` 知道信息从你的计算机到互联网另一端的主机是走的什么路径traceroute hostname traceroute www.baidu.com
`xshell` 文件传输rz # 上传 sz test.c
下载到本地
`ss` `ss`是Socket Statistics的缩写。顾名思义,`ss`命令可以用来获取socket统计信息,它可以显示和netstat类似的内容。但`ss`的优势在于它能够显示更多更详细的有关TCP和连接状态的信息,而且比netstat更快速更高效。显示TCP连接
ss -t -a
socket 摘要
ss -s
列出所有打开的网络连接端口
ss -l
显示所有UDP Sockets
ss -u -a
`telnet` 远程登录telnet 192.168.120.209 talnet www.baidu.com ```
rcpremote file copyscpsecure copy用于在Linux下进行远程拷贝文件的命令,和它类似的命令有cp,不过cp只是在本机进行拷贝不能跨服务器,而且scp传输是加密的。
wget下载
-
计算广告学 笔记3.5 数据加工和交易
课程地址:计算广告学
课时18 数据加工和交易
有价值的数据
- 用户标识
用户标识是最有价值的数据,在广告系统中如果定位一个用户一般是用cookie,但也有更强的方式,有登录的网站,它的效果就cookie就强。腾讯有QQ号做支撑,效果就会非常好。用户标识的效果可以通过多家第三方ID绑定不断优化。
- 用户行为
业界公认有效行为数据(按有效性排序):“交易,预交易,搜索广告点击,广告点击,搜索,搜索点击,网页浏览,分享,广告浏览”,需要注意的是网页浏览是一个被动行为,热点话题应该去掉。越靠近demand的行为对转化越有贡献,越主动的行为越有效。
- 广告商(Demand)数据
如果对广告效果来讲,它是数据的核心。简单的cookie植入可以用于retargeting。对接广告商种子人群可以做look-alike,提高覆盖率。
- 用户属性和精确地理位置
非媒体广告网络很难获取,需通过第三方数据对接。移动互联和HTML5为获得地理位置提供了便利性。
- 社交网络
实名社交网络的人口属性信息相对准确,当一个用户的属性未知时,可以通过好友关系链推测出他的用户属性。
数据管理平台(Data Management Platform)
DMP有几项主要的业务功能:
-
为网站提供数据加工和对外交易能力,即将网站的数据管理起来,加工成标签,标签给网站使用,也可以出售。
-
只加工单个网站的数据,标签更准确,这种标签在交易市场中是有公司有兴趣购买的。
DMP的关键特征有:
-
定制化用户划分,DMP自己加工用户标签是因为它可以针对不同的网站加工不同的标签。
-
统一的对外数据接口
DMP在架构中的位置在图中已经标出,它主要是运行一个Data Highway,把各种各样的数据收集起来,比如它对接了十家媒体,那么十家媒体的数据都通过它的Data Highway到计算平台上,它做两件事,1.做Audience Targeting,即给用户打标签,2. 将标签放在在一些可以对外售卖的体系中,比如AdExchange中。它也可以对上下文提供标签,它属于离线挖掘的部分,作用是综合各网站的数据为主。
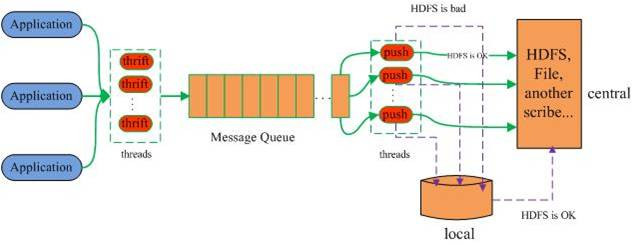
Data Highway工具
个人工作中常用的是Facebook的Scribe这个Data Highway,它提供大规模分布式日志收集功能,比如服务器会产生多种日志,广告投放系统日志,点击日志,我们希望可以在几分钟内收集到这些日志流到Hadoop或是Storm上,进行数据挖掘,我们可以用Scribe。它可以准实时收集大量日志到HDFS,得用Thrift实现底层服务。
-
计算广告学 笔记3.3 上下文定向
课程地址:计算广告学
课时16 上下文定向
它与行为定向相似,也是对用户打标签,但它所打的是一个即时标签,但实现它的系统,是不可能做到实时的,我称它为一个Near-line的系统,意思是接近实时的系统。
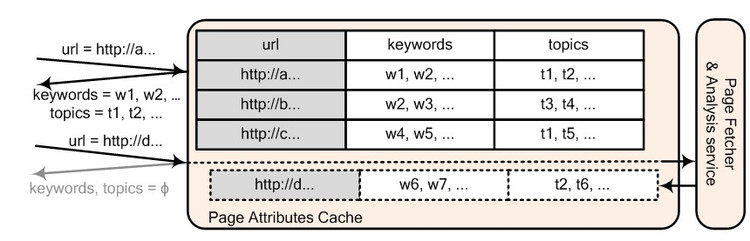
要对上下文打标签,需要一个Key是URL,Value是特征的Cache。广告投放系统就通过URL从这个Cache中取得相应的特征。实现这个Cache与搜索中的爬虫有些区别,因为无法预先知道哪些页面会出广告,如果用爬虫就会做很多无用功。所以在初始化的时候,Cache是空的。
Near-Line系统
-
计算广告学 笔记3.2 行为定向
课程地址:计算广告学
课时15 行为定向
它是对user打标签。用户的哪些行为可以对行为定向有贡献,业界也有一些讨论,我这里列出是的九种类型(按信息强度排序):
-
Transaction,交易行为,对效果广告来说它是最强的信号,这也就是淘宝直通车为什么能营利如此之多,因为Transaction数据的价值远高于其它类型。
-
Pre-transaction,个人使用的一个术语,这种行为还是在Demand Side,是指用户在购买前的一些行为,比如进行商品比价,搜索等,这种行为信息也很强。这两种行为的信息强度和有效性。
-
Paid search click,在搜索时的广告点击行为,
-
Ad click,普通广告的点击行为,广告的点击行为被认为是比较强的信号是因为广告本身不是一个很吸引人的事物,在广告中产生的一个点击,表示用户有明确的目的去了解这个信息。个人认为Ad Click比Paid Search Click要差一些,主要是因为采集Ad Click时的数据噪声,因为Banner广告,特别是在中国环境中,很多时候是依靠骗点击生存的,比如一个广告突然弹出,你猝不及防就点击了,或是本来看起来是链接,但用户点击,其实是一个广告。
-
Search click,在search上产生的点击。
-
Search,搜索本身,它本身也算强信号。上面这四种是信息强度第二强的四种类型,下面三种是数据量很大,但本身作用不大。
-
Share,社交网络中的分享,它表示很强的兴趣,但不Search那样主动,
-
Page View,它是网络中的主要行为,但它在大多数情况下是被动行为。比如用户在新闻网站上浏览,他挑选一些感兴趣的新闻浏览,但门户中的新闻却是由网站决定的固定数量的新闻。并且这种行为离Demand太远,比如查看钓鱼岛的新闻这个行为,很难与广告主的需求直接发生拉关系,再比如一个用户经常浏览凤凰军事,你可以通过他的行为对他打上军事的标签,但很难找到广告主愿意选择这样的标签。
-
Ad View,它在Targeting运算中是起负影响的,因为一个用户看到相同广告次数越多,他疲劳感越强。如果采用线性模型,这个行为是一个负系数。
再强调一点,越是信号强的行为,它的数据量往往就会有限制,比如Transaction比起PV就小几个数据级,再比如Ad Click虽然它的强度还可以,但它的量非常少,所以这种行为用途不大。
行为定向的其他问题
Sesson Log
在工程上,我们需要各种的行为日志,这些日志最有效的组织方式是以用户ID为key的形式,比如在PV这种行为上,记录用户看过的网页URL是哪些,分别有几次。以用户ID为Key听上去非常na?ve,但如果注意这点,会给后面工程上带来很多的便利。这样对targeting时就可以每个记录独立计算,不需要一些全局的计算。
多日累积方式
我们在进行用户行为定向时,会使用多天的数据,我们往往用整周数,比如28天,35天。但这样有一个问题,用户每天计算出的标签并不一致,就产生了如何对多天的标签进行累加的问题。有两种方式来处解决这个问题
- 滑动窗口方式,f为long-term标签,下标为日期。将每天的标签加起来就可以了。但这种方式的问题是要保存前T天的数据。
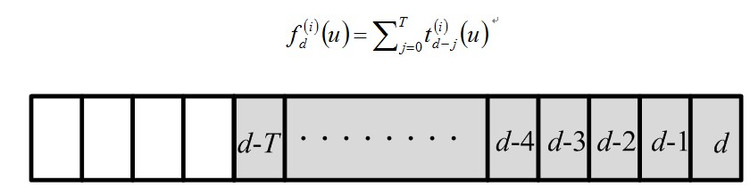
- 时间衰减方式,它是昨天的累加值乘上一个衰减因子(可能是0.95),再加上今天的标签值。这种方式空间复杂度低,仅需昨天的f和今天的t。
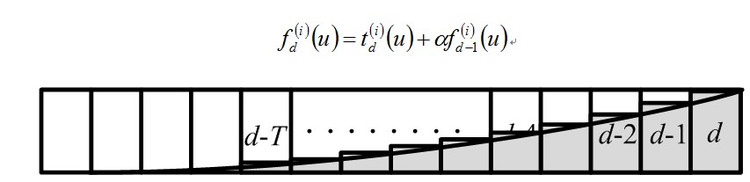
个人推荐时间衰减方式,因为它不需要保存前T天的所有数据。另一个问题是T值如何得到,T的取值是与标签的性质有关,比如汽车标签,它的T值应该取的比较大,因为购车是一个长期的过程,但如果是运动鞋,因为比买鞋到决策是一个很短的时间。所以对不同的标签应该有不同的T,在不同的标签上自动学习出T,这方面的讨论还不多,一般是按经验来做。但这里是一个有很大优化空间的地方。
受众定向评测
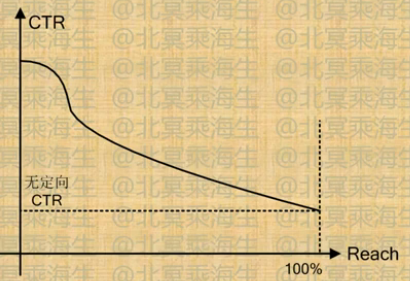
在打标签的过程中,需要设置阈值,比如用户在T天只访问过汽车网站一次,就对他打上汽车标签是不合理的,阈值的设置有两方面的原因,1. 因为标签要存于线上的KV数据库,如果不设阈值,数据量会非常大,并且没什么必要。2. 因为长尾的行为是有噪声的,加载这些数据可能没有好处。所以对一个用户是不是打汽车标签,是由设置的阈值决定的,随着阈值调的越来越小,被打上汽车标签的人群就越多,而在汽车品类上的效果越来越低,图中是以CTR为效果。
-
在reach到100%的人群时,即阈值为0的时候,实际就是没有进行Targeting的情况,所以reach=100%的时候它的CTR取值是一个固定值,与所用的模型无关。Targeting的目标就是让曲线尽量向上,在工程中,因为数据或是算法的原因,这个曲线不一定是单调减的曲线,可能前面反面低,前面低是一个很危险的状态。
-
在数据和算法比较合理时,曲线可能有一个拐点,拐点的物理含义是在拐点之前的是真正属于这个品类的用户,他们的点击率较高,而拐点之后点击率会迅速下降。知道这个拐点,就可以知道大概该品类真正有价值的用户大概有多少,这对GD广告中销售流量是有指导意义的。
-