Welcome to Shanshan Blog!
-
Google Code Jam Round 1A 2016 B Rank and File
Problem
When Sergeant Argus’s army assembles for drilling, they stand in the shape of an N by N square grid, with exactly one soldier in each cell. Each soldier has a certain height.
Argus believes that it is important to keep an eye on all of his soldiers at all times. Since he likes to look at the grid from the upper left, he requires that:
Within every row of the grid, the soldiers’ heights must be in strictly increasing order, from left to right. Within every column of the grid, the soldiers’ heights must be in strictly increasing order, from top to bottom. Although no two soldiers in the same row or column may have the same height, it is possible for multiple soldiers in the grid to have the same height.
Since soldiers sometimes train separately with their row or their column, Argus has asked you to make a report consisting of 2*N lists of the soldiers’ heights: one representing each row (in left-to-right order) and column (in top-to-bottom order). As you surveyed the soldiers, you only had small pieces of paper to write on, so you wrote each list on a separate piece of paper. However, on your way back to your office, you were startled by a loud bugle blast and you dropped all of the pieces of paper, and the wind blew one away before you could recover it! The other pieces of paper are now in no particular order, and you can’t even remember which lists represent rows and which represent columns, since you didn’t write that down.
You know that Argus will make you do hundreds of push-ups if you give him an incomplete report. Can you figure out what the missing list is?
Input and Output
Input
The first line of the input gives the number of test cases, T. T test cases follow. Each consists of one line with an integer N, followed by 2*N-1 lines of N integers each, representing the lists you have, as described in the statement. It is guaranteed that these lists represent all but one of the rows and columns from a valid grid, as described in the statement.
Output
For each test case, output one line containing Case #x: y, where x is the test case number (starting from 1) and y is a list of N integers in strictly increasing order, representing the missing list.
Limits
1 ≤ T ≤ 50.
1 ≤ all heights ≤ 2500.
The integers on each line will be in strictly increasing order.
It is guaranteed that a unique valid answer exists. Small dataset
2 ≤ N ≤ 10.
Large dataset
2 ≤ N ≤ 50.
Sample
Input 1 3 1 2 3 2 3 5 3 5 6 2 3 4 1 2 3 Output Case #1: 3 4 6In the sample case, the arrangement must be either this:
1 2 3 2 3 4 3 5 6 or this: 1 2 3 2 3 5 3 4 6In either case, the missing list is 3 4 6.
Codes
#include <iostream> #include <unordered_map> #include <vector> #include <algorithm> using namespace std; typedef unordered_map<int,int> mymap; // 思路很简单,出现个数为奇数的则是遗漏的 int main() { freopen("C:\\Users\\Administrator\\Downloads\\B-small-practice.in","r",stdin); freopen("C:\\Users\\Administrator\\Downloads\\B-small-attempt0.out","w",stdout); int num, n, a; cin >> num; mymap m; vector<int> vec; for (int i=0; i<num; i++) { m.clear(); vec.clear(); cout << "Case #" << i+1 << ": "; cin >> n; int k = n * (2 * n - 1); while (k--) { cin >> a; m[a]++; } for (mymap::iterator iter = m.begin(); iter != m.end(); iter++) if (iter->second % 2 !=0) vec.push_back(iter->first); sort(vec.begin(), vec.end()); for (int i=0; i < vec.size(); i++) cout << vec[i] << " "; cout << endl; } return 0; }
-
Google Code Jam Round 1A 2016 A The Last Word
Problem
On the game show The Last Word, the host begins a round by showing the contestant a string S of uppercase English letters. The contestant has a whiteboard which is initially blank. The host will then present the contestant with the letters of S, one by one, in the order in which they appear in S. When the host presents the first letter, the contestant writes it on the whiteboard; this counts as the first word in the game (even though it is only one letter long). After that, each time the host presents a letter, the contestant must write it at the beginning or the end of the word on the whiteboard before the host moves on to the next letter (or to the end of the game, if there are no more letters).
For example, for S = CAB, after writing the word C on the whiteboard, the contestant could make one of the following four sets of choices:
-
put the A before C to form AC, then put the B before AC to form BAC
-
put the A before C to form AC, then put the B after AC to form ACB
-
put the A after C to form CA, then put the B before CA to form BCA
-
put the A after C to form CA, then put the B after CA to form CAB
The word is called the last word when the contestant finishes writing all of the letters from S, under the given rules. The contestant wins the game if their last word is the last of an alphabetically sorted list of all of the possible last words that could have been produced. For the example above, the winning last word is CAB (which happens to be the same as the original word). For a game with S = JAM, the winning last word is MJA.
You are the next contestant on this show, and the host has just showed you the string S. What’s the winning last word that you should produce?
Input and Output
Input
The first line of the input gives the number of test cases, T. T test cases follow. Each consists of one line with a string S.
Output
For each test case, output one line containing Case #x: y, where x is the test case number (starting from 1) and y is the winning last word, as described in the statement.
Limits
1 ≤ T ≤ 100.
Small dataset
1 ≤ length of S ≤ 15.
Large dataset
1 ≤ length of S ≤ 1000.
Sample
Input 7 CAB JAM CODE ABAAB CABCBBABC ABCABCABC ZXCASDQWE Output Case #1: CAB Case #2: MJA Case #3: OCDE Case #4: BBAAA Case #5: CCCABBBAB Case #6: CCCBAABAB Case #7: ZXCASDQWECodes
#include <iostream> using namespace std; int main() { freopen("C:\\Users\\Administrator\\Downloads\\A-large-practice.in","r",stdin); freopen("C:\\Users\\Administrator\\Downloads\\A-large-attempt0.out","w",stdout); int num; cin >> num; string s; for (int i=0; i<num; i++) { cout << "Case #" << i+1 << ": "; cin >> s; string res = ""; res += s[0]; for (int i=1; i<s.size(); i++) { if (s[i]>=res[0]) res = s[i] + res; else res = res + s[i]; } cout << res << endl; } return 0; }
-
-
500 Lines or Less Chapter 22: A Simple Web Server 翻译
介绍
网络在过去二十年里以无数的方式改变了社会,但核心变化很小。大多数系统仍然遵循Tim Berners-Lee在世纪前提出的规则。特别地,大多数Web服务器仍然以相同的方式处理他们所做的相同类型的消息。
本章将探讨如何做到这一点。同时,探索开发人员如何创建不需要重写的软件系统,以添加新功能。
背景
网络上的每个程序都有互联网协议(IP)的通信标准。这个家族的成员是传输控制协议(TCP/IP),它使计算机之间的通信看起来像是读写文件。
使用IP的程序通过套接字进行通信。每个插座是点对点通信通道的一端,就像手机是电话的一端。套接字包含一个标识特定机器的IP地址和该机器上的端口号。 IP地址由四个8位数字组成,如
174.136.14.108;域名系统(DNS)将这些数字与符号名称(如aosabook.org)相匹配,更容易记住。端口号是0-65535范围内唯一标识主机上套接字的数字。(如果IP地址像公司的电话号码,则端口号就像扩展名。)端口0-1023保留供操作系统使用;任何人都可以使用剩余的端口。
超文本传输协议(HTTP)描述了程序可以通过IP交换数据的一种方式。HTTP很简单:客户端发送一个请求,指定套接字连接所需的内容,服务器发送数据作为响应(图22.1。)数据可以从磁盘上的文件复制,由程序动态生成,或一些混合的两个。
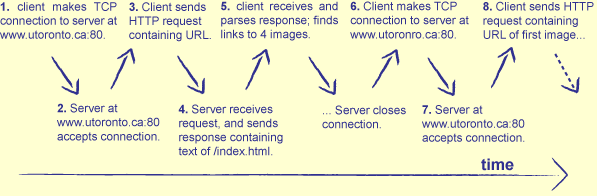
HTTP请求最重要的是它只是文本:可以创建或解析它的程序。 为了理解,该文本必须具有图22.2所示的部分。
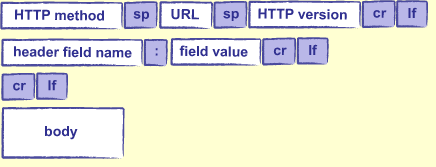
HTTP方法总是“GET”(提取信息)或“POST”(提交表单数据或上传文件)。URL指定客户端所需的内容;它通常是磁盘上文件的路径,例如
/research/experiments.html,但,完全由服务器决定如何处理。HTTP版本通常是“HTTP/1.0”或“HTTP/1.1”; 两者之间的差异对不重要。HTTP标头是键/值对,如下所示:
Accept: text/html Accept-Language: en, fr If-Modified-Since: 16-May-2005与哈希表中的键不同,密钥在HTTP头可能会出现任意次数。 这允许请求做某事,例如指定它愿意接受多种类型的内容。
最后,请求的正文是请求相关联额外的数据。当通过Web表单提交数据,上传文件等时使用 在最后一个标题和正文的开头之间必须有一条空白的行,以标示标题的结尾。
Content-Length头告诉服务器在请求正文中要读取多少字节。HTTP响应格式如HTTP请求(图22.3):
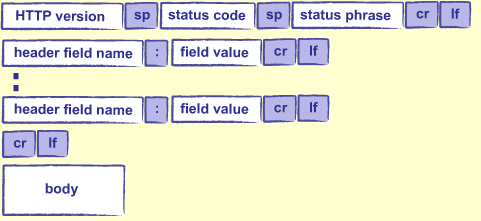
版本,标题和正文具有相同的形式和含义。状态码是指示处理请求时发生了什么的数字:200表示“一切正常”,404表示“未找到”,其他代码也有其他含义。状态短语以“OK”或“not found”等可读的短语。
为了本章,我们需要了解有关HTTP的其他两件事情。
第一个是无状态的:每个请求都是自己处理的,服务器在请求和下一个请求之间不记录任何东西。如果应用程序想要跟踪用户身份的内容,那么它本身就必须这样做。
通常的方法是使用一个cookie,它是服务器发送给客户端的一个短字符串,客户端稍后返回服务器。当用户执行一些需要在多个请求中保存状态的功能时,服务器创建一个新的cookie,将其存储在数据库中,并将其发送到浏览器。每当浏览器将cookie发送回来时,服务器使用它来查找用户正在做什么的信息。
我们需要知道的关于HTTP的第二件事是,URL可以用参数来补充,以提供更多的信息。例如,如果我们使用搜索引擎,必须指定我们的搜索字词。我们可以将这些添加到URL中的路径中,但是我们应该做的是向URL添加参数。我们在’key=value’对后通过添加“?”载用’&’分隔。例如,URL
http://www.google.ca?q=Python要求Google搜索与Python相关的页面:关键是字母“q”,值为“Python”。更长的查询http://www.google.ca/search?q=Python&client=Firefox告诉Google我们正在使用Firefox等等。我们可以传递我们想要的任何参数,但是再次,由网站上运行的应用程序决定哪些参数要注意,以及如何解释它们。当然,如果 ‘?’和’&’是特殊字符,必须有一种方法来逃避,就像必须有一种方法,将双引号字符放在由双引号分隔的字符串中。URL编码标准表示使用’%’后跟2位数代码的特殊字符,并用’+’字符替换空格。因此,要搜索Google的“grade = A +”(带空格),我们将使用URL
http://www.google.ca/search?q=grade+%3D+A%2B。打开套接字,构建HTTP请求和解析响应是乏味的,所以大多数人使用库来完成大部分工作。Python附带了
urllib2的库(它是urllib的替代品),但它暴露了大量人们不关心的管道。Request库是urllib2更容易使用的替代方法。这是一个使用它从AOSA图书网站下载页面的示例:import requests response = requests.get('http://aosabook.org/en/500L/web-server/testpage.html') print 'status code:', response.status_code print 'content length:', response.headers['content-length'] print response.textstatus code: 200 content length: 61 <html> <body> <p>Test page.</p> </body> </html>request.get向服务器发送HTTP GET请求,并返回包含响应的对象。该对象的status_code成员是响应的状态代码;content_length成员是响应数据中的字节数,text是实际数据(在这种情况下为HTML页面)。Hello Web
我们现在准备编写第一个简单的Web服务器。基本思路很简单:
-
等待某人连接到我们的服务器并发送HTTP请求;
-
解析该请求;
-
弄清楚它在要求什么
-
获取数据(或动态生成);
-
将数据格式化为HTML; 和
-
发回来
步骤1,2和6从一个应用程序到另一个应用程序是相同的,所以Python标准库
BaseHTTPServer的模块,为我们做这些。我们只需要座第3-5步,如下:import BaseHTTPServer class RequestHandler(BaseHTTPServer.BaseHTTPRequestHandler): '''Handle HTTP requests by returning a fixed 'page'.''' # Page to send back. Page = '''\ <html> <body> <p>Hello, web!</p> </body> </html> ''' # Handle a GET request. def do_GET(self): self.send_response(200) self.send_header("Content-Type", "text/html") self.send_header("Content-Length", str(len(self.Page))) self.end_headers() self.wfile.write(self.Page) #---------------------------------------------------------------------- if __name__ == '__main__': serverAddress = ('', 8080) server = BaseHTTPServer.HTTPServer(serverAddress, RequestHandler) server.serve_forever()库的
BaseHTTPRequestHandler类负责解析传入的HTTP请求,并确定它包含哪些方法。如果方法是GET,则该类调用do_GET方法。我们的类RequestHandler重写此方法,动态生成一个简单的页面:文本存储在类级变量Page中,我们在发送200个响应代码之后发送回客户端,一个Content-Type头告诉用户解释我们数据作为HTML,以及页面的长度。 (end_headers方法插入将页眉与页面本身分开的空白行)。但是
RequestHandler并不是全部:我们仍然需要最后三行来实际启动服务器运行。第一行将服务器的地址定义为元组:空字符串表示“在当前机器上运行”,8080是端口。然后,我们使用该地址和请求处理程序类作为输入创建一个BaseHTTPServer.HTTPServer的实例,然后请求它永远运行(意味着,直到我们用Control-C杀死它)。如果我们从命令行运行这个程序,它不会显示任何内容:
$ python server.py如果我们然后使用我们的浏览器去
http://localhost:8080,在浏览器中得到这个:Hello, web!在shell中:
127.0.0.1 - - [24/Feb/2014 10:26:28] "GET / HTTP/1.1" 200 - 127.0.0.1 - - [24/Feb/2014 10:26:28] "GET /favicon.ico HTTP/1.1" 200 -第一行很简单:我们没有要求一个特定的文件,我们的浏览器要求’/’(服务器正在服务的根目录)。第二行是因为我们的浏览器自动发送第二个请求,一个名为
/favicon.ico的图像文件,它将在地址栏中显示为图标(如果存在)。Displaying Values
让我们修改Web服务器来显示HTTP请求中包含的值。(调试时我们会经常这么做,所以我们也可以做一些练习。)为了保持代码清洁,我们将分离创建页面发送:
class RequestHandler(BaseHTTPServer.BaseHTTPRequestHandler): # ...page template... def do_GET(self): page = self.create_page() self.send_page(page) def create_page(self): # ...fill in... def send_page(self, page): # ...fill in...send_page是我们之前所说的:def send_page(self, page): self.send_response(200) self.send_header("Content-type", "text/html") self.send_header("Content-Length", str(len(page))) self.end_headers() self.wfile.write(page)我们要显示的页面模板只是一个包含HTML表格和一些格式占位符的字符串:
Page = '''\ <html> <body> <table> <tr> <td>Header</td> <td>Value</td> </tr> <tr> <td>Date and time</td> <td>{date_time}</td> </tr> <tr> <td>Client host</td> <td>{client_host}</td> </tr> <tr> <td>Client port</td> <td>{client_port}s</td> </tr> <tr> <td>Command</td> <td>{command}</td> </tr> <tr> <td>Path</td> <td>{path}</td> </tr> </table> </body> </html> '''填写的方法是:
def create_page(self): values = { 'date_time' : self.date_time_string(), 'client_host' : self.client_address[0], 'client_port' : self.client_address[1], 'command' : self.command, 'path' : self.path } page = self.Page.format(**values) return page程序的主体不变:与之前一样,它创建
HTTPServer类的实例,其地址和该请求处理程序作为参数,永远提供请求。 如果我们运行它并从http://localhost:8080/something.html的浏览器发送请求,我们得到:Date and time Mon, 24 Feb 2014 17:17:12 GMT Client host 127.0.0.1 Client port 54548 Command GET Path /something.html请注意,即使页面
something.html不存在于磁盘上的文件,我们也不会收到404错误。这是因为一个Web服务器只是一个程序,并且可以在获取请求时做任何事情:发回上一个请求中命名的文件,提供随机选择的维基百科页面,或者我们编写的任何其他文件。Serving Static Pages
明显下一步是从磁盘开始提供页面,而不是快速生成。我们从重写
do_GET开始:def do_GET(self): try: # Figure out what exactly is being requested. full_path = os.getcwd() + self.path # It doesn't exist... if not os.path.exists(full_path): raise ServerException("'{0}' not found".format(self.path)) # ...it's a file... elif os.path.isfile(full_path): self.handle_file(full_path) # ...it's something we don't handle. else: raise ServerException("Unknown object '{0}'".format(self.path)) # Handle errors. except Exception as msg: self.handle_error(msg)该方法假定允许在Web服务器正在运行的目录(或其使用
os.getcwd)中的任何文件中提供文件。它将与URL中提供的路径(库自动放入self.path中,始终以’/’开头)组合,以获取用户想要的文件的路径。如果不存在,或者它不是文件,该方法通过提高和捕获异常来报告错误。另一方面,如果路径匹配文件,则调用
handle_file的帮助程序来读取并返回内容。此方法只读文件,并使用我们现有的send_content将其发送回客户端:def handle_file(self, full_path): try: with open(full_path, 'rb') as reader: content = reader.read() self.send_content(content) except IOError as msg: msg = "'{0}' cannot be read: {1}".format(self.path, msg) self.handle_error(msg)请注意,我们以二进制模式打开文件 - ‘rb’中的’b’,以便Python不会尝试通过修改看起来像Windows行结束的字节序列“帮助”我们。 还要注意,在服务时将整个文件读入内存是一个坏主意,在现实生活中,文件可能是几千兆字节的视频数据。 处理这种情况不在本章的范围之内。
要完成这个课程,我们需要编写错误处理方法和错误报告页面的模板:
Error_Page = """\ <html> <body> <h1>Error accessing {path}</h1> <p>{msg}</p> </body> </html> """ def handle_error(self, msg): content = self.Error_Page.format(path=self.path, msg=msg) self.send_content(content)这个程序是有效的,但是只有当我们不要求得那么仔细的时候。问题在于,即使请求的页面不存在,它总是返回200的状态码。是的,这种情况下发回的页面包含错误消息,但由于我们的浏览器不能读英文,它不知道请求实际上失败。为了使之清楚,我们需要修改
handle_error和send_content,如下所示:# Handle unknown objects. def handle_error(self, msg): content = self.Error_Page.format(path=self.path, msg=msg) self.send_content(content, 404) # Send actual content. def send_content(self, content, status=200): self.send_response(status) self.send_header("Content-type", "text/html") self.send_header("Content-Length", str(len(content))) self.end_headers() self.wfile.write(content)请注意,当找不到文件时,不会引发
ServerException,而是生成错误页面。ServerException意味着发出服务器代码中的内部错误,即错误的地方。另一方面,当用户出错时,会出现handle_error创建的错误页面,即向我们发送不存在的文件的URL。罗列Directories
下一步,当URL中的路径是目录而不是文件时,教会Web服务器显示目录内容的列表。我们甚至可以进一步,让它在该目录中查找要显示的
index.html文件,如果该文件不存在,则仅显示目录内容的列表。但是,将这些规则构建到
do_GET中将是一个错误,因为生成的方法是一堆的if语句控制特殊行为。正确的解决方案是退一步并解决一般问题,弄清楚如何处理URL。重写do_GET方法def do_GET(self): try: # Figure out what exactly is being requested. self.full_path = os.getcwd() + self.path # Figure out how to handle it. for case in self.Cases: handler = case() if handler.test(self): handler.act(self) break # Handle errors. except Exception as msg: self.handle_error(msg)第一步是一样的:找出要求的东西的完整路径。之后,代码有很大的不同。不是一系列内联测试,这个版本循环了一组存储在列表中的案例。每种情况都是一个有两种方法的对象:测试,它告诉我们是否能够处理请求并采取行动,这实际上需要采取一些行动 一旦找到正确的案例,我们就让它处理这个请求并突破循环。
这三种情况类再现了我们以前服务器的行为:
class case_no_file(object): '''File or directory does not exist.''' def test(self, handler): return not os.path.exists(handler.full_path) def act(self, handler): raise ServerException("'{0}' not found".format(handler.path)) class case_existing_file(object): '''File exists.''' def test(self, handler): return os.path.isfile(handler.full_path) def act(self, handler): handler.handle_file(handler.full_path) class case_always_fail(object): '''Base case if nothing else worked.''' def test(self, handler): return True def act(self, handler): raise ServerException("Unknown object '{0}'".format(handler.path))下面是我们构造
RequestHandler类顶部的case处理程序列表:class RequestHandler(BaseHTTPServer.BaseHTTPRequestHandler): ''' If the requested path maps to a file, that file is served. If anything goes wrong, an error page is constructed. ''' Cases = [case_no_file(), case_existing_file(), case_always_fail()] ...everything else as before...现在,我们的服务器更加复杂:文件已经从74增长到99行,并且有一个额外的间接级别,没有任何新功能。当我们回到本章开始的任务,尝试指导我们的服务器为目录提供
index.html页面,如果有的话,还有一个目录列表,如果没有的话就更好。 前者的处理程序是:class case_directory_index_file(object): '''Serve index.html page for a directory.''' def index_path(self, handler): return os.path.join(handler.full_path, 'index.html') def test(self, handler): return os.path.isdir(handler.full_path) and \ os.path.isfile(self.index_path(handler)) def act(self, handler): handler.handle_file(self.index_path(handler))这里,辅助方法
index_path构造了index.html文件的路径; 将其放在案例处理程序中防止RequestHandler的杂乱。测试检查路径是否是包含index.html页面的目录,并且请求主要请求处理程序来提供该页面。RequestHandler所需唯一的更改是将case_directory_index_file对象添加到我们的Case列表中:Cases = [case_no_file(), case_existing_file(), case_directory_index_file(), case_always_fail()]那些不包含
index.html页面的目录呢?与上面有个not插入的测试是一样的,但act函数呢?怎么做?class case_directory_no_index_file(object): '''Serve listing for a directory without an index.html page.''' def index_path(self, handler): return os.path.join(handler.full_path, 'index.html') def test(self, handler): return os.path.isdir(handler.full_path) and \ not os.path.isfile(self.index_path(handler)) def act(self, handler): ???我们已经到了这一步。逻辑上,
act方法创建并返回目录列表,但是现有的代码不允许:RequestHandler.do_GET调用act,但不期望或处理返回值。我们为RequestHandler添加一个方法来生成目录列表,并从case handler的act中调用它:class case_directory_no_index_file(object): '''Serve listing for a directory without an index.html page.''' # ...index_path and test as above... def act(self, handler): handler.list_dir(handler.full_path) class RequestHandler(BaseHTTPServer.BaseHTTPRequestHandler): # ...all the other code... # How to display a directory listing. Listing_Page = '''\ <html> <body> <ul> {0} </ul> </body> </html> ''' def list_dir(self, full_path): try: entries = os.listdir(full_path) bullets = ['<li>{0}</li>'.format(e) for e in entries if not e.startswith('.')] page = self.Listing_Page.format('\n'.join(bullets)) self.send_content(page) except OSError as msg: msg = "'{0}' cannot be listed: {1}".format(self.path, msg) self.handle_error(msg)The CGI Protocol
当然,大多数人不想编辑他们的网络服务器的源,以便添加新功能。为了不这么做,服务器一直支持通用网关接口(CGI)的机制,它为Web服务器运行外部程序以满足请求提供了一种标准方式。
例如,假设我们希望服务器能够在HTML页面中显示本地时间。 我们可以在一个独立的程序中执行,只需几行代码:
from datetime import datetime print '''\ <html> <body> <p>Generated {0}</p> </body> </html>'''.format(datetime.now())为了让web服务器为我们运行这个程序,我们添加case处理程序:
class case_cgi_file(object): '''Something runnable.''' def test(self, handler): return os.path.isfile(handler.full_path) and \ handler.full_path.endswith('.py') def act(self, handler): handler.run_cgi(handler.full_path)测试很简单:文件路径是否以
.py结尾?如果是,RequestHandler会运行此程序。def run_cgi(self, full_path): cmd = "python " + full_path child_stdin, child_stdout = os.popen2(cmd) child_stdin.close() data = child_stdout.read() child_stdout.close() self.send_content(data)这是非常不安全的:如果有人知道在我们服务器上的Python文件的路径,我们只是让它们运行,而不用担心它可以访问什么数据,无论它是否包含无限循环,或其他。
完成这一点,核心思想很简单:
-
在子进程中运行程序。
-
捕获任何子处理发送到标准输出。
-
发送给发出请求的客户端。
完整的CGI协议比这更多 —— 特别是它允许URL中的参数,服务器进入正在运行的程序,但这些详细信息不会影响系统的整体架构…
…再次变得相当纠结。
RequestHandler最初有一个方法handle_file,用于处理内容。现在我们以list_dir和run_cgi的形式添加了两个特殊情况。这三种方法并不属于他们所在,因为它们主要被其他人使用。修复很简单:为我们的所有处理程序创建一个父类,并将其他方法移到该类,如果它们由两个或更多的处理程序共享。完成后,
RequestHandler类是这样:class RequestHandler(BaseHTTPServer.BaseHTTPRequestHandler): Cases = [case_no_file(), case_cgi_file(), case_existing_file(), case_directory_index_file(), case_directory_no_index_file(), case_always_fail()] # How to display an error. Error_Page = """\ <html> <body> <h1>Error accessing {path}</h1> <p>{msg}</p> </body> </html> """ # Classify and handle request. def do_GET(self): try: # Figure out what exactly is being requested. self.full_path = os.getcwd() + self.path # Figure out how to handle it. for case in self.Cases: if case.test(self): case.act(self) break # Handle errors. except Exception as msg: self.handle_error(msg) # Handle unknown objects. def handle_error(self, msg): content = self.Error_Page.format(path=self.path, msg=msg) self.send_content(content, 404) # Send actual content. def send_content(self, content, status=200): self.send_response(status) self.send_header("Content-type", "text/html") self.send_header("Content-Length", str(len(content))) self.end_headers() self.wfile.write(content) while the parent class for our case handlers is: class base_case(object): '''Parent for case handlers.''' def handle_file(self, handler, full_path): try: with open(full_path, 'rb') as reader: content = reader.read() handler.send_content(content) except IOError as msg: msg = "'{0}' cannot be read: {1}".format(full_path, msg) handler.handle_error(msg) def index_path(self, handler): return os.path.join(handler.full_path, 'index.html') def test(self, handler): assert False, 'Not implemented.' def act(self, handler): assert False, 'Not implemented.'现有文件的处理程序(只是随机选择一个例子)是:
class case_existing_file(base_case): '''File exists.''' def test(self, handler): return os.path.isfile(handler.full_path) def act(self, handler): self.handle_file(handler, handler.full_path)讨论
我们的原始代码和重构版本之间的差异反映了两个重要的想法。第一个是把一个类作为相关服务的集合。
RequestHandler和base_case不做决定或采取任何行动; 他们提供其他类可以用来做这些事情的工具。第二个是可扩展性:人们可以通过编写外部CGI程序或添加案例处理程序类来为我们的Web服务器添加新功能。后者需要对
RequestHandler进行单行更改(将案例处理程序插入到案例列表中),但是我们可以通过使Web服务器读取配置文件并从中加载处理程序类来消除这一点。在这两种情况下,它们都可以忽略大多数较低级别的详细信息,就像BaseHTTPRequestHandler类忽略处理套接字连接和解析HTTP请求的细节一样。这些想法通常是有用的;看你能否在自己的项目中找到使用它们的方法。
-
-
Google Code Jam Qualification Round 2016 D Fractiles
Problem
Long ago, the Fractal civilization created artwork consisting of linear rows of tiles. They had two types of tile that they could use: gold (G) and lead (L).
Each piece of Fractal artwork is based on two parameters: an original sequence of K tiles, and a complexity C. For a given original sequence, the artwork with complexity 1 is just that original sequence, and the artwork with complexity X+1 consists of the artwork with complexity X, transformed as follows:
-
replace each L tile in the complexity X artwork with another copy of the original sequence
-
replace each G tile in the complexity X artwork with K G tiles
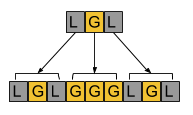
For example, for an original sequence of LGL, the pieces of artwork with complexity 1 through 3 are:
-
C = 1: LGL (which is just the original sequence)
-
C = 2: LGLGGGLGL
-
C = 3: LGLGGGLGLGGGGGGGGGLGLGGGLGL
Here’s an illustration of how the artwork with complexity 2 is generated from the artwork with complexity 1:
You have just discovered a piece of Fractal artwork, but the tiles are too dirty for you to tell what they are made of. Because you are an expert archaeologist familiar with the local Fractal culture, you know the values of K and C for the artwork, but you do not know the original sequence. Since gold is exciting, you would like to know whether there is at least one G tile in the artwork. Your budget allows you to hire S graduate students, each of whom can clean one tile of your choice (out of the KC tiles in the artwork) to see whether the tile is G or L.
Is it possible for you to choose a set of no more than S specific tiles to clean, such that no matter what the original pattern was, you will be able to know for sure whether at least one G tile is present in the artwork? If so, which tiles should you clean?
Input and Output
Input
The first line of the input gives the number of test cases, T. T test cases follow. Each consists of one line with three integers: K, C, and S.
Output
For each test case, output one line containing Case #x: y, where x is the test case number (starting from 1) and y is either IMPOSSIBLE if no set of tiles will answer your question, or a list of between 1 and S positive integers, which are the positions of the tiles that will answer your question. The tile positions are numbered from 1 for the leftmost tile to KC for the rightmost tile. Your chosen positions may be in any order, but they must all be different.
If there are multiple valid sets of tiles, you may output any of them. Remember that once you submit a Small and it is accepted, you will not be able to download and submit another Small input. See the FAQ for a more thorough explanation. This reminder won’t appear in problems in later rounds.
Limits
1 ≤ T ≤ 100.
1 ≤ K ≤ 100.
1 ≤ C ≤ 100.
KC ≤ 1018.
Small dataset
S = K.
Large dataset
1 ≤ S ≤ K.
Sample
Input 5 2 3 2 1 1 1 2 1 1 2 1 2 3 2 3 Output Case #1: 2 Case #2: 1 Case #3: IMPOSSIBLE Case #4: 1 2 Case #5: 2 6Note: for some of these sample cases, other valid solutions exist.
In sample case #1, there are four possible original sequences: GG, GL, LG, and LL. They would produce the following artwork, respectively:
-
Original sequence GG: GGGGGGGG
-
Original sequence GL: GGGGGGGL
-
Original sequence LG: LGGGGGGG
-
Original sequence LL: LLLLLLLL
One valid solution is to just look at tile #2. If tile #2 turns out to be G, then you will know for sure the artwork contains at least one G. (You will not know whether the original sequence is GG, GL, or LG, but that doesn’t matter.) If tile #2 turns out to be L, then you will know that the original sequence must be LL, so there are no Gs in the artwork. So 2 is a valid solution.
On the other hand, it would not be valid to just look at tile #1. If it turns out to be L, you will only know that the original sequence could have been either LG or LL. If the original sequence is LG, there is at least one G in the artwork, but if the original sequence is LL, there are no Gs. So 1 would not be a valid solution.
Note that 1 2 is also a valid solution, because tile #2 already provides all the information you need. 1 2 3 is not a valid solution, because it uses too many tiles.
In sample case #2, the artwork must consist of only one tile: either G or L. Looking at that tile will trivially tell you whether or not the artwork has a G in it.
In sample case #3, which would not appear in the Small dataset, the artwork must be either GG, GL, LG, or LL. You can only look at one tile, and neither of them on its own is enough to answer the question. If you see L for tile #1, you will not know whether the artwork is LG or LL, so you will not know whether any Gs are present. If you see L for tile #2, you will not know whether the artwork is GL or LL, so you will not know whether any Gs are present.
Sample case #4 is like sample case #3, but with access to one more tile. Now you can just look at the entire artwork.
In sample case #5, there are eight possible original sequences, and they would produce the following artwork:
-
Original sequence GGG: GGGGGGGGG
-
Original sequence GGL: GGGGGGGGL
-
Original sequence GLG: GGGGLGGGG
-
Original sequence GLL: GGGGLLGLL
-
Original sequence LGG: LGGGGGGGG
-
Original sequence LGL: LGLGGGLGL
-
Original sequence LLG: LLGLLGGGG
-
Original sequence LLL: LLLLLLLLL
One valid solution is to look at tiles #2 and #6. If they both turn out to be Ls, the artwork must be all Ls. Otherwise, there must at least one G. Note that 1 2 would not be a valid solution, because even if those tiles both turn out to be Ls, that does not rule out an original sequence of LLG. 6 2 would be a valid solution, since the order of the positions in your solution does not matter.
Codes
#include <iostream> using namespace std; int main() { freopen("C:\\Users\\Administrator\\Downloads\\D-small-practice.in","r",stdin); freopen("C:\\Users\\Administrator\\Downloads\\D-small-attempt0.out","w",stdout); int num, n, j; cin >> num; for (int i=0; i<num; i++) { cout << "Case #" << i+1 << ":"; long long k, c, s; cin >> k >> c >> s; if (c * s < k) cout << " IMPOSSIBLE\n"; else { long long x = 0; for(int i=0; i< k; i++) { x = x * k + i; if (i + 1 == k || i % c == c - 1) { cout << ' ' << x + 1; x = 0; } } cout << '\n'; } } return 0; }
-
-
Google Code Jam Qualification Round 2016 C. Coin Jam
Problem
A jamcoin is a string of N ≥ 2 digits with the following properties:
Every digit is either 0 or 1. The first digit is 1 and the last digit is 1. If you interpret the string in any base between 2 and 10, inclusive, the resulting number is not prime. Not every string of 0s and 1s is a jamcoin. For example, 101 is not a jamcoin; its interpretation in base 2 is 5, which is prime. But the string 1001 is a jamcoin: in bases 2 through 10, its interpretation is 9, 28, 65, 126, 217, 344, 513, 730, and 1001, respectively, and none of those is prime.
We hear that there may be communities that use jamcoins as a form of currency. When sending someone a jamcoin, it is polite to prove that the jamcoin is legitimate by including a nontrivial divisor of that jamcoin’s interpretation in each base from 2 to 10. (A nontrivial divisor for a positive integer K is some positive integer other than 1 or K that evenly divides K.) For convenience, these divisors must be expressed in base 10.
For example, for the jamcoin 1001 mentioned above, a possible set of nontrivial divisors for the base 2 through 10 interpretations of the jamcoin would be: 3, 7, 5, 6, 31, 8, 27, 5, and 77, respectively.
Can you produce J different jamcoins of length N, along with proof that they are legitimate?
Input and Output
Input
The first line of the input gives the number of test cases, T. T test cases follow; each consists of one line with two integers N and J.
Output
For each test case, output J+1 lines. The first line must consist of only Case #x:, where x is the test case number (starting from 1). Each of the last J lines must consist of a jamcoin of length N followed by nine integers. The i-th of those nine integers (counting starting from 1) must be a nontrivial divisor of the jamcoin when the jamcoin is interpreted in base i+1.
All of these jamcoins must be different. You cannot submit the same jamcoin in two different lines, even if you use a different set of divisors each time.
Limits
T = 1. (There will be only one test case.)
It is guaranteed that at least J distinct jamcoins of length N exist.
Small dataset
N = 16.
J = 50.
Large dataset
N = 32.
J = 500.
Note that, unusually for a Code Jam problem, you already know the exact contents of each input file. For example, the Small dataset’s input file will always be exactly these two lines:
1
16 50
So, you can consider doing some computation before actually downloading an input file and starting the clock.
Sample
Input 1 6 3 Output Case #1: 100011 5 13 147 31 43 1121 73 77 629 111111 21 26 105 1302 217 1032 513 13286 10101 111001 3 88 5 1938 7 208 3 20 11In this sample case, we have used very small values of N and J for ease of explanation. Note that this sample case would not appear in either the Small or Large datasets.
This is only one of multiple valid solutions. Other sets of jamcoins could have been used, and there are many other possible sets of nontrivial base 10 divisors. Some notes:
110111 could not have been included in the output because, for example, it is 337 if interpreted in base 3 (1243 + 181 + 027 + 19 + 13 + 11), and 337 is prime. 010101 could not have been included in the output even though 10101 is a jamcoin, because jamcoins begin with 1. 101010 could not have been included in the output, because jamcoins end with 1.
110011 is another jamcoin that could have also been used in the output, but could not have been added to the end of this output, since the output must contain exactly J examples.
For the first jamcoin in the sample output, the first number after 100011 could not have been either 1 or 35, because those are trivial divisors of 35 (100011 in base 2).
Codes
#include <iostream> using namespace std; // 思想是100001100001肯定能被100001整除 void help(string s, int base) { long long res = 0; long long k = 1; for (int i=s.size()-1; i>=0; i--) { res += (s[i]-'0')*k; k *= base; } cout << res << " "; } int main() { freopen("C:\\Users\\Administrator\\Downloads\\C-large-practice.in","r",stdin); freopen("C:\\Users\\Administrator\\Downloads\\C-large-attempt0.out","w",stdout); int num, n, j; cin >> num; for (int i=0; i<num; i++) { cin >> n >> j; cout << "Case #" << i + 1 << ":" << endl; for (int b = 0; ; b++) { string s = "1"; for (int i=0; i<(n/2)-2; i++) { if (b&(1<<i)) s += "1"; else s += "0"; } s += "1"; cout << s << s << " "; for (int i=2; i<=10; i++) help(s, i); cout << endl; j--; if (j==0) break; } } return 0; }
-
500 Lines or Less Chapter 11: Making Your Own Image Filters 翻译
Cate离开了科技行业,花了一年时间寻找她的方式,同时建立她的激情项目Show & Hide。她是Ride移动开发的总监,在移动开发和工程文化国际化,协调技术演讲,是Glowforge的顾问。 Cate不住在哥伦比亚,但她去过英国,澳大利亚,加拿大,中国美国,做过Google工程师,在IBM的极限蓝实习生和工作,滑雪教练。Cate博客是Accidentally in Code和Twitter是@catehstn。
一个伟大的想法
当我在中国旅行时,我经常看到四个画在不同季节显示相同的地方。颜色 - 冬天的冷白,春天的苍白,夏天的茂盛绿色,以及秋天的红色和黄色-在视觉上区分季节。2011年,我有了一个很好的想法:我想能够将一系列的照片系列视觉化。
但我不知道如何从图像计算主色。我想将图像缩小到1x1平方,看看剩下的东西,但这似乎是作弊。我知道我想要显示的图像,但是:在向日葵布局中。这是展示圈子的最有效的方式。
我离开这个项目多年,工作,生活,旅行,会谈。最后我回到它,想出了如何计算主色,并完成我的可视化。这是当我发现这个想法并不辉煌。进度不如我所希望的那么清楚,提取的主色通常不是最吸引人的阴影,创作花费了很长时间,并且用了数百个图像,使更好看(Figure 11.1)。

你可能会觉得沮丧,但是现在,我学到了许多事情 - 关于颜色空间和像素操作 - 我开始制作酷炫的局部彩色图像,那种你在伦敦的明信片上看到的一个红色的公共汽车或电话亭的灰度图。
我使用的是Processing的框架,因为我从开发编程课程里了解它,并且因为它让创建可视化应用程序变得容易。它最初是为艺术家设计的工具,所以它抽象了大部分的样板。
大学,以后的工作,填补了我的时间与其他人的想法和优先事项。完成这个项目的一部分是学习如何挖掘时间,来使得我的想法取得进展;我每周需要大约四个小时的精神时间。因此,允许我更快移动的工具是非常有用的,甚至是必要的 - 虽然它也带来了一系列问题,特别是在写测试的时候。
我认为彻底的测试对验证项目如何工作。测试组成了这个项目的文档。我可以留下失败的测试,以记下发生了什么,我还没想到的,并做出改变,如果我改变了一些我忘记的关键,测试会提醒我。
本章将介绍Processing的一些细节,并通过颜色空间,将图像分解为像素并对其进行处理,以及单元测试不是考虑到测试而设计的。但我希望它能促使你对你最近没有做的任何想法开始一些进展;即使你的想法变得可怕,但你也可以做一些很酷的东西,在这个过程中学习更有趣的。
应用程序
本章将向您介绍如何创建一个图像过滤器应用程序,您可以使用它来处理您的数字图像使用您创建的过滤器。我们将使用Processing,Java和开发环境。我们将介绍在Processing中设置应用程序,Processing的一些功能,颜色表示的方面,以及如何创建颜色过滤器(模仿老式摄影中使用的过滤器)。我们还将创建一种特殊类型的过滤器,只能通过数字方式:确定图像的主色调并显示或隐藏,以创建奇妙的局部彩色图像。
最后,我们将添加一个完整的测试套件,并介绍如何处理Processing的局限之处,当谈到可测试性。
背景
今天我们可以拍照,处理图片,并几秒钟内与所有朋友分享。然而很久以前(在数字方面),这是一个需要几周的过程。
在过去,我们拍摄照片,然后使用了一整卷的电影。我们会在几天后拿起开发的图片,发现他们中很多都有问题。手不够稳定?我们当时没有注意到的事情?曝光过度?曝光不足?当然,现在为时已晚,无法补救这个问题。
大多数人不明白的把电影变成图片的过程。光是一个问题,所以你必须注意。有一个过程,涉及黑暗的房间和化学品,他们有时出现在电影或电视上。
但是,可能更少的人了解如何从点击我们的智能手机相机到Instagram上的图像。实际上有很多相似之处。
照片,老方式
照片是由光在光敏表面上产生的效果。照相胶片覆盖着卤化银晶体。(额外的图层用于创建彩色照片 - 为简单起见,我们只是坚持黑白摄影。)
当谈论老式照片 - 与电影 - 打在电影上的光,根据你指向的点和光的量,晶体在不同程度上改变。然后,显影过程将银盐转化为金属银,产生负面影响。负片会反转的图像的明暗区域。一旦开发负极,还有其他一系列步骤来反转图像并打印。
照片,数字方式
当使用智能手机或数码相机拍照时,没有电影。有一种称为有源像素传感器的功能有类似的功能。现在我们有像素 - 小方块。数字图像由像素组成,分辨率更高。

它为什么如此模糊? 我们称之为像素化,这意味着图像对于其包含的像素数量太大,方块变得可见。我们可以用它更好地了解由正方形颜色组成的图像。
这些像素是什么样的? 如果我们使用Java中的
Integer.toHexString打印中间的一些像素(10,10到10,14)的颜色,我们得到十六进制颜色:FFE8B1 FFFAC4 FFFCC3 FFFCC2 FFF5B7十六进制颜色占六个字符。前两个是红色值,第二个是绿色值,第三个是蓝色值。有时还有一个额外的两个字符是alpha值。 在这种情况下,
FFFAC4意味着:-
red = FF (hex) = 255 (base 10)
-
green = FA (hex) = 250 (base 10)
-
blue = C4 (hex) = 196 (base 10)
运行应用程序
图11.4是应用程序运行的图片。这是开发人员设计的,但是我们只有500行Java可以处理,所以不得不忍受!您可以看到右侧的命令列表。 我们可以做以下的事情
-
调整RGB滤镜。
-
调整“色差公差”。
-
设置主色调滤镜,以显示或隐藏主色调。
-
应用我们当前的设置(每按一下按键都不可行)。
-
重置图像。
-
保存我们制作的图像。
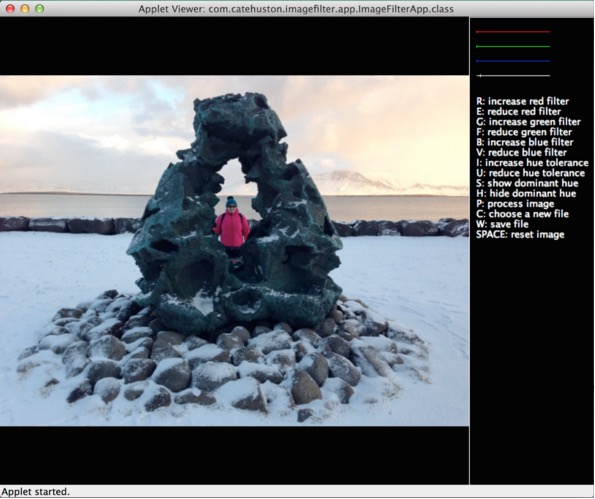
处理使创建一个小应用程序和操作图像操作变得简单;它有个焦点。我们使用Java,虽然Processing已经用在其他语言。
在本教程中,我通过在构建路径中添加
core.jar使用Eclipse中的Processing。如果需要,可以使用Processing IDE,这样就省去了大量Java代码。如果你以后想将其移植到Processing.js并在线上传,则需要将文件选择器替换为其他选项。在项目的repository中有详细的说明和截图。如果您熟悉Eclipse和Java,您可能不需要它们。
加工
尺寸和颜色
我们不希望我们的应用程序是一个微小的灰色窗口,所以我们将首先重写的两个基本方法
setup()和dra()。setup()方法仅在应用程序启动时才被调用,我们需要做的事,比如设置应用程序窗口的大小。为每个动画调用draw()方法,或者通过调用redraw()触发一些动作。(如处理文档中所述,不应显式调用draw())Processing高效的创建动画草图,但在这种情况下,我们不想要动画响应按键。为了防止动画(这将拖累性能),我们将从安装程序调用
noLoop()。这意味着draw()只会在setup()之后立即被调用,当我们调用redraw()时。private static final int WIDTH = 360; private static final int HEIGHT = 240; public void setup() { noLoop(); // Set up the view. size(WIDTH, HEIGHT); background(0); } public void draw() { background(0); }程序只有一点点,但是再尝试运行下应用程序,调整常量
WIDTH和HEIGHT,以查看有什么不同。background(0)是黑色背景。尝试改变传递给background()的数字,看看会发生什么 - 它是alpha值,所以如果你只传递一个数字,它总是灰度级的。或者,您可以调用`background(int r,int g,int b)。PImage
PImage对象是Processing对象。我们将使用它很多次,所以需要阅读文档。它包含三个字段以及我们将使用的一些方法。
-
pixels[]包含图像中每个像素颜色的数组 -
width宽度图像宽度(以像素为单位) -
height高度图像高度(以像素为单位) -
loadPixels将图像的像素数据加载到pixels[]数组中 -
updatePixels使用pixels[]数组中的数据更新图像 -
resize将图像的大小更改为新的宽度和高度 -
get读取任何像素的颜色或抓截取像素矩形 -
set将颜色写入像素,或将图像写入像素 -
save将图像保存到TIFF,TARGA,PNG或JPEG文件
文件选择器
处理大部分文件选择过程;我们只需要调用
selectInput(),并实现一个回调(必须是public)。熟悉Java的人可能觉得使用监听器或lambda表达式会更有意义。然而,由于Processing是作为艺术家的工具而开发的,大部分东西已经被语言抽象出来,以保持它的无意义。这是设计师所做的选择:优先考虑功能和灵活性,简单性和可接近性。如果您使用精简的“处理”编辑器,而不是在Eclipse中处理作为库,则甚至不需要定义类的名称。
不同目标的其他语言设计师会做出不同的选择。例如,在Haskell中,纯功能语言,功能语言范例的纯度优先于其他。这使得它成为数学问题的更好的工具,而不需要IO。
// Called on key press. private void chooseFile() { // Choose the file. selectInput("Select a file to process:", "fileSelected"); } public void fileSelected(File file) { if (file == null) { println("User hit cancel."); } else { // save the image redraw(); // update the display } }响应按键
通常在Java中,响应按键只需要添加监听器并实现匿名函数。然而,与文件选择器一样,Processing处理很多。 我们只需要实现
keyPressed()。public void keyPressed() { print(“key pressed: ” + key); }如果您再次运行该应用程序,每次按下一个键时,它将输出到控制台。之后,您将需要根据按下的键做不同的事情,并且您只需要打开键值即可。 (这存在于PApplet超类中,并包含最后一个按键。)
测试
这个应用程序还没有做很多工作,但是我们已经可以看到有可能出现错误的地方;例如,用按键触发错误的动作。当我们增加复杂性时,我们会增加更多的潜在问题,例如没有正确的更新图像状态,或者在应用过滤器后错误计算像素颜色。我也只是喜欢写单元测试。虽然有些人认为测试只是检查代码,但我认为测试深入了解我的代码中发生了什么。
我喜欢Processing,但它的目的是创建视觉应用程序,在这个领域可能单元测试不是个大问题。很明显,它不是为了可测试性而编写的,因为它是不可测量的。其中的一部分原因是它隐藏了复杂性,而这些隐藏的复杂性在编写单元测试中是非常有用的。使用静态和最终的方法使得使用mocks(记录交互的对象,允许伪造一部分系统,以验证另一部分的正确确)更难使用,这依赖于子类。
我们可能会进行测试驱动开发(TDD)并实现完美的测试,但实际上,我们通常会看到各种各样的人们编写的大量代码,并试图弄清楚它要做什么,以及为什么会出错。也许我们没有写完整的测试,但是测试可以帮助我们解决问题,记录发生的情况并继续往前。
我们创造了“接缝”,使我们能够打破其无定形的纠结块,并将其部分验证。为此,我们有时会创建可以包装类。这些类别只是持有类似方法的集合,或者将调用转发到另一个对象,因此它们非常无聊,但是创建接缝和制作的关键代码需要。
我使用JUnit进行测试,因为我在Java中使用Processing作为库。我使用了Mockito。您可以下载Mockito,并以与添加
core.jar相同的方式将JAR添加到您的构建路径。我创建了两个帮助类,可以模拟和测试应用程序(否则我们无法测试PImage或PApplet方法)。IFAImage是PImage的简单包装。PixelColorHelper是applet像素颜色方法的包装。这些包装器是final和static方法,但调用方法本身既不是final也不是静态的,这允许它们被模拟。这些是故意轻量化的,我们还可以进一步发展,但是在使用Processing - static和final方法时,这足以解决可测试性的主要问题。毕竟,目标是制作一个应用程序,而不是处理单元测试框架!ImageState类形成了该应用程序的“模型”,从PApplet的类中删除了尽可能多的逻辑,以获得更好的可测试性。它还可以让您更清晰的设计和分离问题:应用程序控制交互和UI,而不是图像操作。自己做过滤器
RGB滤镜
在我们开始编写更复杂的像素处理之前,我们可以从简单的练习开始,让我们能够更好地进行像素处理。创建标准(红色,绿色,蓝色)滤色镜,使我们能够创建与将相机的镜头上放置和彩色平板相同的效果,只能通过红色(或绿色或蓝色)的光线。
通过对这个图像应用不同的过滤器图11.5。(记得我们以前想过的四季画吗?)当应用红色滤镜时,请查看树变成怎样的绿色。

我们该怎么做呢?
-
设置过滤器。
-
对于图像中的每个像素,请检查其RGB值。
-
如果红色小于红色滤光片,请将红色设置为零。
-
如果绿色小于绿色滤光片,请将绿色设置为零。
-
如果蓝色小于蓝色滤光片,请将蓝色设为零。
-
所有这些颜色都不足的像素则设置为黑色的。
虽然我们的图像是二维的,但像素是从左上方开始并从左到右从上到下的一维阵列中。4x4图像的数组索引如下所示:
0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15public void applyColorFilter(PApplet applet, IFAImage img, int minRed, int minGreen, int minBlue, int colorRange) { img.loadPixels(); int numberOfPixels = img.getPixels().length; for (int i = 0; i < numberOfPixels; i++) { int pixel = img.getPixel(i); float alpha = pixelColorHelper.alpha(applet, pixel); float red = pixelColorHelper.red(applet, pixel); float green = pixelColorHelper.green(applet, pixel); float blue = pixelColorHelper.blue(applet, pixel); red = (red >= minRed) ? red : 0; green = (green >= minGreen) ? green : 0; blue = (blue >= minBlue) ? blue : 0; image.setPixel(i, pixelColorHelper.color(applet, red, green, blue, alpha)); } }颜色
作为图像过滤器的第一个例子,程序中的颜色的概念和表示对于了解我们的过滤器是如何工作非常重要的。让我们再来探索颜色的概念。
我们在上一节中使用了“颜色空间”的概念,它是以数字方式表示颜色的方式。可以看出,颜色可以由其他颜色合成;数字化的工作略有不同但类似。Processing使得您可以轻松地理所需的任何颜色空间,但您需要知道要选择的颜色空间,因此了解其工作原理非常重要。
RGB颜色
大多数程序员熟悉的颜色空间是RGBA:我们之前使用的红,绿,蓝和alpha。在十六进制(基数16)中,前两位数字是红色,后两个数字是蓝色,再后两个数字是绿色,最后两个数字(如果有的话)是alpha值。值范围从基数16的00(基10中的0)到FF(基10中的255)。alpha表示不透明度,其中0表示透明度,100%表示不透明度。
HSB或HSV颜色
这个颜色空间并不像RGB那样熟悉。第一个数字表示色调,第二个数字表示饱和度,第三个数字表示亮度。 HSB颜色空间可以用锥形表示:色调是圆锥体周围的位置,饱和距离中心的距离,亮度是高度## 。
从图像中提取主色调
为了满意操作像素,我们进行数字化操作。在数字上,我们可以以不统一的方式操作图像。
当我看着主题的图片流。日落时我在香港港口的一条船上,北韩的灰色,巴厘岛的郁郁葱葱的绿色,冰岛的冰冷的白色和冰冷的蓝色带来的夜间系列。我们可以拍一张照片主导色彩的主色调吗?
使用HSB颜色空间是有意义的 - 我们比较感兴趣主色调的hue值。可以使用RGB值来做到这一点,但更困难(我们必须比较所有三个值),它对黑暗更敏感。我们可以使用colorMode更改为HSB颜色空间。
处理颜色空间,比使用RGB更简单。我们需要找到每个像素的色调,并找出哪个是“最受欢迎”的。我们可能不需要确切 - 我们希望将相似的色调组合在一起,我们可以使用两种策略来处理。
首先,我们将小数四舍五入返回整数,因为这样可以很容易地确定我们把每个像素放在哪个“桶”中。其次,我们可以改变色调的范围。如果我们想象上面提及的圆锥,认为色调有360度(像一个圆圈)。处理默认使用255,这与RGB的典型值相同(255是十六进制的FF)。我们使用的范围越高,图片的色调就越明显。使用较小的范围将允许我们将类似的色调组合在一起。使用360度范围,224的色相和225的色调的差异非常小。如果我们的范围是其中的三分之一,120,这两种色调在四舍五入后变为75。
我们可以使用
colorMode来改变色调的范围。如果我们调用colorMode(HSB,120),我们刚刚使我们的色调检测精度略低于255范围的一半。我们也知道我们的色调将落在120“桶”,所以我们可以简单地看一下我们的图像,获取一个像素的色调,并在一个数组中添加相应的数值。这将是(O(n)),其中(n)是像素的数量,因为它需要对每个像素执行操作。for(int px in pixels) { int hue = Math.round(hue(px)); hues[hue]++; }最后,我们打印hue到屏幕上,并呈现在下一张图(图11.6)

一旦我们提取了“主导”色调,就可以选择在图像中显示或隐藏它。我们可以显示具有不同公差的主要色调。根据设置亮度值,不会落入此范围的像素更改为灰度。 图11.7显示了使用240范围和变化公差确定的主色调。容忍度是被分组在一起的最受欢迎的色调的任一侧的数量。

或者,我们可以隐藏主色调。 在图11.8中,图像并排排列:原图在中间,左侧显示主色调(路棕褐色),右图显示主色调(范围320,容差20 )。

每个图像需要双程,所以在具有大量像素的图像上,明显花费时间。
public HSBColor getDominantHue(PApplet applet, IFAImage image, int hueRange) { image.loadPixels(); int numberOfPixels = image.getPixels().length; int[] hues = new int[hueRange]; float[] saturations = new float[hueRange]; float[] brightnesses = new float[hueRange]; for (int i = 0; i < numberOfPixels; i++) { int pixel = image.getPixel(i); int hue = Math.round(pixelColorHelper.hue(applet, pixel)); float saturation = pixelColorHelper.saturation(applet, pixel); float brightness = pixelColorHelper.brightness(applet, pixel); hues[hue]++; saturations[hue] += saturation; brightnesses[hue] += brightness; } // Find the most common hue. int hueCount = hues[0]; int hue = 0; for (int i = 1; i < hues.length; i++) { if (hues[i] > hueCount) { hueCount = hues[i]; hue = i; } } // Return the color to display. float s = saturations[hue] / hueCount; float b = brightnesses[hue] / hueCount; return new HSBColor(hue, s, b); } public void processImageForHue(PApplet applet, IFAImage image, int hueRange, int hueTolerance, boolean showHue) { applet.colorMode(PApplet.HSB, (hueRange - 1)); image.loadPixels(); int numberOfPixels = image.getPixels().length; HSBColor dominantHue = getDominantHue(applet, image, hueRange); // Manipulate photo, grayscale any pixel that isn't close to that hue. float lower = dominantHue.h - hueTolerance; float upper = dominantHue.h + hueTolerance; for (int i = 0; i < numberOfPixels; i++) { int pixel = image.getPixel(i); float hue = pixelColorHelper.hue(applet, pixel); if (hueInRange(hue, hueRange, lower, upper) == showHue) { float brightness = pixelColorHelper.brightness(applet, pixel); image.setPixel(i, pixelColorHelper.color(applet, brightness)); } } image.updatePixels(); }组合过滤器
使用UI,用户可以将红色,绿色和蓝色滤镜组合在一起。如果它们将主色调滤光片与红色,绿色和蓝色滤光片相结合,则由于更改颜色空间,结果有时会意想不到。
Processing有一些支持图像操作的内置方法;例如,
invert和blur。为了达到像锐化,模糊或棕褐色等效果,我们使用矩阵。对于图像的每个像素,将每个产品的当前像素或其邻居的颜色值的乘积与滤波器矩阵的对应值相乘。有一些特殊的特殊矩阵可以锐化图像。
结构
应用程序有三个主要组件(图11.9)。
应用程序
该应用程序包含一个文件:
ImageFilterApp.java。这扩展了PApplet,并处理布局,用户交互等。这个类是最难测试的,所以我们希望尽可能小。模型
模型由三个文件组成:
HSBColor.java是HSB颜色的简单容器(由色调,饱和度和亮度组成)。IFAImage包装了PImage。(PImage包含一些不能被嘲模拟的方法)最后,ImageState.java描述图像状态的对象 - 应该应用什么级别的过滤器,以有及哪些过滤器和怎样处理加载图像。(注意:每当滤镜被调整时,每当重新计算主色调时,都需要重新加载图像。为了清楚起见,我们每次处理图像时都会重新加载。)颜色
颜色由两个文件组成:
ColorHelper.java是发生所有图像处理和过滤的位置,PixelColorHelper.java为像素颜色提供最终的PApplet方法以进行测试。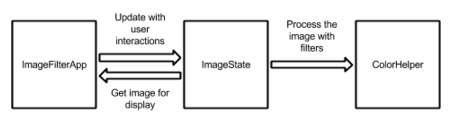
包装类和测试
上面简要提到,有两个包装类(
IFAImage和PixelColorHelper)可以包装库方法以进行测试。 因为在Java中,关键字“final”表示不能被子类覆盖或隐藏的方法,这意味着它们不能被模拟。PixelColorHelper包装小程序上的方法。 这意味着我们需要将applet传递给每个方法调用。 (或者,我们可以使它成为一个字段,并在初始化时进行设置。)
package com.catehuston.imagefilter.color; import processing.core.PApplet; public class PixelColorHelper { public float alpha(PApplet applet, int pixel) { return applet.alpha(pixel); } public float blue(PApplet applet, int pixel) { return applet.blue(pixel); } public float brightness(PApplet applet, int pixel) { return applet.brightness(pixel); } public int color(PApplet applet, float greyscale) { return applet.color(greyscale); } public int color(PApplet applet, float red, float green, float blue, float alpha) { return applet.color(red, green, blue, alpha); } public float green(PApplet applet, int pixel) { return applet.green(pixel); } public float hue(PApplet applet, int pixel) { return applet.hue(pixel); } public float red(PApplet applet, int pixel) { return applet.red(pixel); } public float saturation(PApplet applet, int pixel) { return applet.saturation(pixel); } }IFAImage包装了PImage,所以在我们的应用程序中,我们不会初始化一个PImage,而是IFAImage- 尽管我们必须暴露PImage,以便可以渲染package com.catehuston.imagefilter.model; import processing.core.PApplet; import processing.core.PImage; public class IFAImage { private PImage image; public IFAImage() { image = null; } public PImage image() { return image; } public void update(PApplet applet, String filepath) { image = null; image = applet.loadImage(filepath); } // Wrapped methods from PImage. public int getHeight() { return image.height; } public int getPixel(int px) { return image.pixels[px]; } public int[] getPixels() { return image.pixels; } public int getWidth() { return image.width; } public void loadPixels() { image.loadPixels(); } public void resize(int width, int height) { image.resize(width, height); } public void save(String filepath) { image.save(filepath); } public void setPixel(int px, int color) { image.pixels[px] = color; } public void updatePixels() { image.updatePixels(); } }最后,我们设置了简单的容器类
HSBColor。 请注意,它是不可变的(一旦创建,它不能被更改)。 不可变的对象线程更安全,但也更容易理解和解释。一般来说,我倾向于让简单的模型类不可变,除非有好的理由不你这样做。你可能知道Processing里已经存在的类和Java本身表示颜色的类。没有太多细节,他们更专注于RGB颜色,并且Java类特别增加了比我们需要的更多的复杂性。如果我们确实想要使用Java的
awt.Color,可能没问题 然而,awt GUI组件不能在Processing中使用,所以要创建简单的容器类来保存这些数据。package com.catehuston.imagefilter.model; public class HSBColor { public final float h; public final float s; public final float b; public HSBColor(float h, float s, float b) { this.h = h; this.s = s; this.b = b; } }ColorHelper和相关的测试
ColorHelper有所有的图像操作。 如果不需要PixelColorHelper,这个类中的方法可能是静态的。 (虽然我们不在这里讨论静态方法的优点。)package com.catehuston.imagefilter.color; import processing.core.PApplet; import com.catehuston.imagefilter.model.HSBColor; import com.catehuston.imagefilter.model.IFAImage; public class ColorHelper { private final PixelColorHelper pixelColorHelper; public ColorHelper(PixelColorHelper pixelColorHelper) { this.pixelColorHelper = pixelColorHelper; } public boolean hueInRange(float hue, int hueRange, float lower, float upper) { // Need to compensate for it being circular - can go around. if (lower < 0) { lower += hueRange; } if (upper > hueRange) { upper -= hueRange; } if (lower < upper) { return hue < upper && hue > lower; } else { return hue < upper || hue > lower; } } public HSBColor getDominantHue(PApplet applet, IFAImage image, int hueRange) { image.loadPixels(); int numberOfPixels = image.getPixels().length; int[] hues = new int[hueRange]; float[] saturations = new float[hueRange]; float[] brightnesses = new float[hueRange]; for (int i = 0; i < numberOfPixels; i++) { int pixel = image.getPixel(i); int hue = Math.round(pixelColorHelper.hue(applet, pixel)); float saturation = pixelColorHelper.saturation(applet, pixel); float brightness = pixelColorHelper.brightness(applet, pixel); hues[hue]++; saturations[hue] += saturation; brightnesses[hue] += brightness; } // Find the most common hue. int hueCount = hues[0]; int hue = 0; for (int i = 1; i < hues.length; i++) { if (hues[i] > hueCount) { hueCount = hues[i]; hue = i; } } // Return the color to display. float s = saturations[hue] / hueCount; float b = brightnesses[hue] / hueCount; return new HSBColor(hue, s, b); } public void processImageForHue(PApplet applet, IFAImage image, int hueRange, int hueTolerance, boolean showHue) { applet.colorMode(PApplet.HSB, (hueRange - 1)); image.loadPixels(); int numberOfPixels = image.getPixels().length; HSBColor dominantHue = getDominantHue(applet, image, hueRange); // Manipulate photo, grayscale any pixel that isn't close to that hue. float lower = dominantHue.h - hueTolerance; float upper = dominantHue.h + hueTolerance; for (int i = 0; i < numberOfPixels; i++) { int pixel = image.getPixel(i); float hue = pixelColorHelper.hue(applet, pixel); if (hueInRange(hue, hueRange, lower, upper) == showHue) { float brightness = pixelColorHelper.brightness(applet, pixel); image.setPixel(i, pixelColorHelper.color(applet, brightness)); } } image.updatePixels(); } public void applyColorFilter(PApplet applet, IFAImage image, int minRed, int minGreen, int minBlue, int colorRange) { applet.colorMode(PApplet.RGB, colorRange); image.loadPixels(); int numberOfPixels = image.getPixels().length; for (int i = 0; i < numberOfPixels; i++) { int pixel = image.getPixel(i); float alpha = pixelColorHelper.alpha(applet, pixel); float red = pixelColorHelper.red(applet, pixel); float green = pixelColorHelper.green(applet, pixel); float blue = pixelColorHelper.blue(applet, pixel); red = (red >= minRed) ? red : 0; green = (green >= minGreen) ? green : 0; blue = (blue >= minBlue) ? blue : 0; image.setPixel(i, pixelColorHelper.color(applet, red, green, blue, alpha)); } } }我们不想测试整个图像,因为我们需要已知属性和原因的图像。我们通过模拟图像来逼近它,并使其返回一个像素数组。这使我们能够验证行为是否符合预期。早些时候我们讨论了模拟对象的概念,在这里我们看到了它们的用途。 我们使用Mockito作为我们的模拟对象框架。
为了创建一个模拟,我们在实例变量上使用
@Mock注释,并且它MockitoJUnitRunner运行时模拟。对于stub方法,我们使用:
when(mock.methodCall()).thenReturn(value)为了验证调用的方法,我们使用
verify(mock.methodCall())。我们在这里展示了一些测试实例。
package com.catehuston.imagefilter.color; /* ... Imports omitted ... */ @RunWith(MockitoJUnitRunner.class) public class ColorHelperTest { @Mock PApplet applet; @Mock IFAImage image; @Mock PixelColorHelper pixelColorHelper; ColorHelper colorHelper; private static final int px1 = 1000; private static final int px2 = 1010; private static final int px3 = 1030; private static final int px4 = 1040; private static final int px5 = 1050; private static final int[] pixels = { px1, px2, px3, px4, px5 }; @Before public void setUp() throws Exception { colorHelper = new ColorHelper(pixelColorHelper); when(image.getPixels()).thenReturn(pixels); setHsbValuesForPixel(0, px1, 30F, 5F, 10F); setHsbValuesForPixel(1, px2, 20F, 6F, 11F); setHsbValuesForPixel(2, px3, 30F, 7F, 12F); setHsbValuesForPixel(3, px4, 50F, 8F, 13F); setHsbValuesForPixel(4, px5, 30F, 9F, 14F); } private void setHsbValuesForPixel(int px, int color, float h, float s, float b) { when(image.getPixel(px)).thenReturn(color); when(pixelColorHelper.hue(applet, color)).thenReturn(h); when(pixelColorHelper.saturation(applet, color)).thenReturn(s); when(pixelColorHelper.brightness(applet, color)).thenReturn(b); } private void setRgbValuesForPixel(int px, int color, float r, float g, float b, float alpha) { when(image.getPixel(px)).thenReturn(color); when(pixelColorHelper.red(applet, color)).thenReturn(r); when(pixelColorHelper.green(applet, color)).thenReturn(g); when(pixelColorHelper.blue(applet, color)).thenReturn(b); when(pixelColorHelper.alpha(applet, color)).thenReturn(alpha); } @Test public void testHsbColorFromImage() { HSBColor color = colorHelper.getDominantHue(applet, image, 100); verify(image).loadPixels(); assertEquals(30F, color.h, 0); assertEquals(7F, color.s, 0); assertEquals(12F, color.b, 0); } @Test public void testProcessImageNoHue() { when(pixelColorHelper.color(applet, 11F)).thenReturn(11); when(pixelColorHelper.color(applet, 13F)).thenReturn(13); colorHelper.processImageForHue(applet, image, 60, 2, false); verify(applet).colorMode(PApplet.HSB, 59); verify(image, times(2)).loadPixels(); verify(image).setPixel(1, 11); verify(image).setPixel(3, 13); } @Test public void testApplyColorFilter() { setRgbValuesForPixel(0, px1, 10F, 12F, 14F, 60F); setRgbValuesForPixel(1, px2, 20F, 22F, 24F, 70F); setRgbValuesForPixel(2, px3, 30F, 32F, 34F, 80F); setRgbValuesForPixel(3, px4, 40F, 42F, 44F, 90F); setRgbValuesForPixel(4, px5, 50F, 52F, 54F, 100F); when(pixelColorHelper.color(applet, 0F, 0F, 0F, 60F)).thenReturn(5); when(pixelColorHelper.color(applet, 20F, 0F, 0F, 70F)).thenReturn(15); when(pixelColorHelper.color(applet, 30F, 32F, 0F, 80F)).thenReturn(25); when(pixelColorHelper.color(applet, 40F, 42F, 44F, 90F)).thenReturn(35); when(pixelColorHelper.color(applet, 50F, 52F, 54F, 100F)).thenReturn(45); colorHelper.applyColorFilter(applet, image, 15, 25, 35, 100); verify(applet).colorMode(PApplet.RGB, 100); verify(image).loadPixels(); verify(image).setPixel(0, 5); verify(image).setPixel(1, 15); verify(image).setPixel(2, 25); verify(image).setPixel(3, 35); verify(image).setPixel(4, 45); } }注意:
-
我们使用
MockitoJUnit运行。 -
我们模拟
PApplet,IFAImage和ImageColorHelper。 -
测试方法用
@ Test2注释。 如果您想忽略测试,您可以添加注释@Ignore。 -
在
setup()中,我们创建像素数组并使模拟图像返回。 -
Helper方法可以更容易地为循环任务设置期望(例如,设置
set*ForPixel())。
图像状态和相关测试
ImageState保存图像的当前“状态” - 图像本身以及将要应用的设置和过滤器。我们在此忽略ImageState的完整实现,但我们展示如何进行测试。你可以访问此项目的源存储库,以查看完整的详细信息。package com.catehuston.imagefilter.model; import processing.core.PApplet; import com.catehuston.imagefilter.color.ColorHelper; public class ImageState { enum ColorMode { COLOR_FILTER, SHOW_DOMINANT_HUE, HIDE_DOMINANT_HUE } private final ColorHelper colorHelper; private IFAImage image; private String filepath; public static final int INITIAL_HUE_TOLERANCE = 5; ColorMode colorModeState = ColorMode.COLOR_FILTER; int blueFilter = 0; int greenFilter = 0; int hueTolerance = 0; int redFilter = 0; public ImageState(ColorHelper colorHelper) { this.colorHelper = colorHelper; image = new IFAImage(); hueTolerance = INITIAL_HUE_TOLERANCE; } /* ... getters & setters */ public void updateImage(PApplet applet, int hueRange, int rgbColorRange, int imageMax) { ... } public void processKeyPress(char key, int inc, int rgbColorRange, int hueIncrement, int hueRange) { ... } public void setUpImage(PApplet applet, int imageMax) { ... } public void resetImage(PApplet applet, int imageMax) { ... } // For testing purposes only. protected void set(IFAImage image, ColorMode colorModeState, int redFilter, int greenFilter, int blueFilter, int hueTolerance) { ... } }在这里我们测试给定状态发生的适当行为; 那些字段被递增和递减。
package com.catehuston.imagefilter.model; /* ... Imports omitted ... */ @RunWith(MockitoJUnitRunner.class) public class ImageStateTest { @Mock PApplet applet; @Mock ColorHelper colorHelper; @Mock IFAImage image; private ImageState imageState; @Before public void setUp() throws Exception { imageState = new ImageState(colorHelper); } private void assertState(ColorMode colorMode, int redFilter, int greenFilter, int blueFilter, int hueTolerance) { assertEquals(colorMode, imageState.getColorMode()); assertEquals(redFilter, imageState.redFilter()); assertEquals(greenFilter, imageState.greenFilter()); assertEquals(blueFilter, imageState.blueFilter()); assertEquals(hueTolerance, imageState.hueTolerance()); } @Test public void testUpdateImageDominantHueHidden() { imageState.setFilepath("filepath"); imageState.set(image, ColorMode.HIDE_DOMINANT_HUE, 5, 10, 15, 10); imageState.updateImage(applet, 100, 100, 500); verify(image).update(applet, "filepath"); verify(colorHelper).processImageForHue(applet, image, 100, 10, false); verify(colorHelper).applyColorFilter(applet, image, 5, 10, 15, 100); verify(image).updatePixels(); } @Test public void testUpdateDominantHueShowing() { imageState.setFilepath("filepath"); imageState.set(image, ColorMode.SHOW_DOMINANT_HUE, 5, 10, 15, 10); imageState.updateImage(applet, 100, 100, 500); verify(image).update(applet, "filepath"); verify(colorHelper).processImageForHue(applet, image, 100, 10, true); verify(colorHelper).applyColorFilter(applet, image, 5, 10, 15, 100); verify(image).updatePixels(); } @Test public void testUpdateRGBOnly() { imageState.setFilepath("filepath"); imageState.set(image, ColorMode.COLOR_FILTER, 5, 10, 15, 10); imageState.updateImage(applet, 100, 100, 500); verify(image).update(applet, "filepath"); verify(colorHelper, never()).processImageForHue(any(PApplet.class), any(IFAImage.class), anyInt(), anyInt(), anyBoolean()); verify(colorHelper).applyColorFilter(applet, image, 5, 10, 15, 100); verify(image).updatePixels(); } @Test public void testKeyPress() { imageState.processKeyPress('r', 5, 100, 2, 200); assertState(ColorMode.COLOR_FILTER, 5, 0, 0, 5); imageState.processKeyPress('e', 5, 100, 2, 200); assertState(ColorMode.COLOR_FILTER, 0, 0, 0, 5); imageState.processKeyPress('g', 5, 100, 2, 200); assertState(ColorMode.COLOR_FILTER, 0, 5, 0, 5); imageState.processKeyPress('f', 5, 100, 2, 200); assertState(ColorMode.COLOR_FILTER, 0, 0, 0, 5); imageState.processKeyPress('b', 5, 100, 2, 200); assertState(ColorMode.COLOR_FILTER, 0, 0, 5, 5); imageState.processKeyPress('v', 5, 100, 2, 200); assertState(ColorMode.COLOR_FILTER, 0, 0, 0, 5); imageState.processKeyPress('h', 5, 100, 2, 200); assertState(ColorMode.HIDE_DOMINANT_HUE, 0, 0, 0, 5); imageState.processKeyPress('i', 5, 100, 2, 200); assertState(ColorMode.HIDE_DOMINANT_HUE, 0, 0, 0, 7); imageState.processKeyPress('u', 5, 100, 2, 200); assertState(ColorMode.HIDE_DOMINANT_HUE, 0, 0, 0, 5); imageState.processKeyPress('h', 5, 100, 2, 200); assertState(ColorMode.COLOR_FILTER, 0, 0, 0, 5); imageState.processKeyPress('s', 5, 100, 2, 200); assertState(ColorMode.SHOW_DOMINANT_HUE, 0, 0, 0, 5); imageState.processKeyPress('s', 5, 100, 2, 200); assertState(ColorMode.COLOR_FILTER, 0, 0, 0, 5); // Random key should do nothing. imageState.processKeyPress('z', 5, 100, 2, 200); assertState(ColorMode.COLOR_FILTER, 0, 0, 0, 5); } @Test public void testSave() { imageState.set(image, ColorMode.SHOW_DOMINANT_HUE, 5, 10, 15, 10); imageState.setFilepath("filepath"); imageState.processKeyPress('w', 5, 100, 2, 200); verify(image).save("filepath-new.png"); } @Test public void testSetupImageLandscape() { imageState.set(image, ColorMode.SHOW_DOMINANT_HUE, 5, 10, 15, 10); when(image.getWidth()).thenReturn(20); when(image.getHeight()).thenReturn(8); imageState.setUpImage(applet, 10); verify(image).update(applet, null); verify(image).resize(10, 4); } @Test public void testSetupImagePortrait() { imageState.set(image, ColorMode.SHOW_DOMINANT_HUE, 5, 10, 15, 10); when(image.getWidth()).thenReturn(8); when(image.getHeight()).thenReturn(20); imageState.setUpImage(applet, 10); verify(image).update(applet, null); verify(image).resize(4, 10); } @Test public void testResetImage() { imageState.set(image, ColorMode.SHOW_DOMINANT_HUE, 5, 10, 15, 10); imageState.resetImage(applet, 10); assertState(ColorMode.COLOR_FILTER, 0, 0, 0, 5); } }请注意:
-
我们暴露了一个受保护的初始化方法
set用于测试,帮助我们快速将被测系统置于特定状态。 -
我们模拟
PApplet,ColorHelper和IFAImage`。 -
这一次我们使用帮助函数(
assertState())来简化图像的状态。
测量覆盖范围
我使用EclEmma来测量Eclipse中的测试覆盖率。对于该程序,我们有81%的测试覆盖率,
ImageFilterApp为0,ImageState为94.8%,ColorHelper为100%。ImageFilterApp
这里合并整个程序。应用程序很难进行单元测试,但是由于我们将这么多应用程序的功能推送到我们自己测试的类中,我们可以确保重要的部件按照预期的方式工作。
我们设置应用程序的大小,并进行布局。
package com.catehuston.imagefilter.app; import java.io.File; import processing.core.PApplet; import com.catehuston.imagefilter.color.ColorHelper; import com.catehuston.imagefilter.color.PixelColorHelper; import com.catehuston.imagefilter.model.ImageState; @SuppressWarnings("serial") public class ImageFilterApp extends PApplet { static final String INSTRUCTIONS = "..."; static final int FILTER_HEIGHT = 2; static final int FILTER_INCREMENT = 5; static final int HUE_INCREMENT = 2; static final int HUE_RANGE = 100; static final int IMAGE_MAX = 640; static final int RGB_COLOR_RANGE = 100; static final int SIDE_BAR_PADDING = 10; static final int SIDE_BAR_WIDTH = RGB_COLOR_RANGE + 2 * SIDE_BAR_PADDING + 50; private ImageState imageState; boolean redrawImage = true; @Override public void setup() { noLoop(); imageState = new ImageState(new ColorHelper(new PixelColorHelper())); // Set up the view. size(IMAGE_MAX + SIDE_BAR_WIDTH, IMAGE_MAX); background(0); chooseFile(); } @Override public void draw() { // Draw image. if (imageState.image().image() != null && redrawImage) { background(0); drawImage(); } colorMode(RGB, RGB_COLOR_RANGE); fill(0); rect(IMAGE_MAX, 0, SIDE_BAR_WIDTH, IMAGE_MAX); stroke(RGB_COLOR_RANGE); line(IMAGE_MAX, 0, IMAGE_MAX, IMAGE_MAX); // Draw red line int x = IMAGE_MAX + SIDE_BAR_PADDING; int y = 2 * SIDE_BAR_PADDING; stroke(RGB_COLOR_RANGE, 0, 0); line(x, y, x + RGB_COLOR_RANGE, y); line(x + imageState.redFilter(), y - FILTER_HEIGHT, x + imageState.redFilter(), y + FILTER_HEIGHT); // Draw green line y += 2 * SIDE_BAR_PADDING; stroke(0, RGB_COLOR_RANGE, 0); line(x, y, x + RGB_COLOR_RANGE, y); line(x + imageState.greenFilter(), y - FILTER_HEIGHT, x + imageState.greenFilter(), y + FILTER_HEIGHT); // Draw blue line y += 2 * SIDE_BAR_PADDING; stroke(0, 0, RGB_COLOR_RANGE); line(x, y, x + RGB_COLOR_RANGE, y); line(x + imageState.blueFilter(), y - FILTER_HEIGHT, x + imageState.blueFilter(), y + FILTER_HEIGHT); // Draw white line. y += 2 * SIDE_BAR_PADDING; stroke(HUE_RANGE); line(x, y, x + 100, y); line(x + imageState.hueTolerance(), y - FILTER_HEIGHT, x + imageState.hueTolerance(), y + FILTER_HEIGHT); y += 4 * SIDE_BAR_PADDING; fill(RGB_COLOR_RANGE); text(INSTRUCTIONS, x, y); updatePixels(); } // Callback for selectInput(), has to be public to be found. public void fileSelected(File file) { if (file == null) { println("User hit cancel."); } else { imageState.setFilepath(file.getAbsolutePath()); imageState.setUpImage(this, IMAGE_MAX); redrawImage = true; redraw(); } } private void drawImage() { imageMode(CENTER); imageState.updateImage(this, HUE_RANGE, RGB_COLOR_RANGE, IMAGE_MAX); image(imageState.image().image(), IMAGE_MAX/2, IMAGE_MAX/2, imageState.image().getWidth(), imageState.image().getHeight()); redrawImage = false; } @Override public void keyPressed() { switch(key) { case 'c': chooseFile(); break; case 'p': redrawImage = true; break; case ' ': imageState.resetImage(this, IMAGE_MAX); redrawImage = true; break; } imageState.processKeyPress(key, FILTER_INCREMENT, RGB_COLOR_RANGE, HUE_INCREMENT, HUE_RANGE); redraw(); } private void chooseFile() { // Choose the file. selectInput("Select a file to process:", "fileSelected"); } }注意:
-
代码扩展到
PApplet。 -
大多数工作都是在
ImageState中完成的。 -
fileSelected()是selectInput()的回调。 -
static final常数定义在顶部。
原型的价值
在现实的编程中,我们花了大量的时间在生产工作上。维持99.9%正常运行时间。我们花更多的时间在边境案例,而不是精简算法。
这些限制和要求对我们的用户很重要。然而,还有空间让自己玩耍和探索。
最终,我决定把这个移植到一个原生的手机应用程序。处理有一个Android库,但是与许多移动开发人员一样,我选择iOS。我有多年的iOS经验,虽然我对CoreGraphics做了很少的工作,但是我最初没有想到这个想法,所以我简历iOS应用。该平台迫使我在RGB颜色空间操作中,并且很难从图像中提取像素(hello,C)。
有令人兴奋的时刻,当它第一次工作。当它第一次运行在我的设备…没有崩溃。当我将内存使用率优化了66%,并将运行时间缩短了几秒钟。而且在一个黑暗的房间里还有很长一段时间被锁定,间歇地咒骂着。
因为我有原型,我可以向我的业务伙伴和我们的设计师解释我在想什么和程序是做什么的。这意味着我深刻理解它如何工作。我知道我的目标是什么,所以在漫长的一天结束之后,与它的战斗结束了,感觉像我没有什么可以展现的,我继续前进,第二天早上有了令人振奋的时刻和里程碑。
那么,你如何在图像中找到主要颜色?有一个应用程序:显示和隐藏。
其他
-
如果我们想创建一个动画草图,我们不会调用
noLoop()(或者,如果我们想在以后动画,我们将调用loop())。动画的频率由frameRate()确定 -
测试中的方法名称不需要从JUnit 4开始,习惯很难打破
-