Carl Friedrich Bolz是伦敦国王学院的研究员,对各种动态语言的实现和优化有着广泛的兴趣。他是PyPy / RPython的核心作者之一,致力于Prolog,Racket,Smalltalk,PHP和Ruby的实现。他的Twitter名是@cfbolz。
介绍
面向对象编程是本章使用的主要编程范例之一,许多语言都提供某种形式的面向对象。而表面上,不同的面向对象编程语言为程序员提供的机制非常相似,细节可能会有很大变化。大多数语言的共同点是存在对象和继承机制。然而,类不是每种语言直接支持的功能。例如,在基于原型的语言(如Self或JavaScript)中,类的概念不存在,而对象则直接相互继承。
了解不同对象模型之间的差异是有趣的。他们透露出不同语言之间的相似之处。将新语言的模型放入其他语言模型的上下文中,可以快速了解新模型,并为编程语言设计获得更好的感觉。
本章探讨了一系列非常简单的对象模型的实现。它以简单的实例和类开始,并且可以调用实例上的方法。这是在早期的OO语言(如Simula 67和Smalltalk)中建立的“经典”面向对象方法。然后,这个模型逐步扩展,接下来的两个步骤探索不同的语言设计选择,最后一步提高了对象模型的效率。最终的模型不是真正的语言,而是Python的对象模型的理想化的简化版本。
本章介绍的对象模型将在Python中实现。该代码适用于Python 2.7和3.4。为了更好地了解行为和设计选择,本章还将介绍对象模型的测试。测试可以用py.test或者鼻子来运行。
选择Python作为实现语言是非常不切实际的。一个“真正的”虚拟机通常以低级语言(如C/C ++)实现,并且需要非常注意工程细节以使其高效。然而,更简单的实现语言更容易专注于实际行为差异,而不是被实现细节陷入困境。
基于方法的模型
我们将开始的对象模型是Smalltalk的一个非常简化的版本。Smalltalk是由Alan Kay在上世纪七十年代施乐公司设计的面向对象编程语言。它推广了面向对象编程,并且是当今编程语言中许多功能的来源。Smalltalk语言设计的核心原则之一是“一切都是对象”。Smalltalk今天使用的最直接的后继者是Ruby,它使用更多的C语法,但保留了Smalltalk的大多数对象模型。
本节中的对象模型将具有它们的类和实例,能够将属性读取和写入对象,调用对象方法的能力以及类作为另一个类的子类的能力。从一开始,类是普通的对象,本身可以具有属性和方法。
关于术语的说明:在本章中,我将使用“实例”一词来表示 - “不是类的对象”。
开始的办法是写一个测试来指定要实现的行为应该是什么。本章提出的所有测试将由两部分组成。首先,一些常规的Python代码定义和使用几个类,并利用Python对象模型的日益高级的功能。二,相应的测试使用对象模型,我们将在本章中实现,而不是普通的Python类。
使用普通Python类和使用对象模型之间的映射将在测试中手动完成。例如,在Python中,而不是写入obj.attribute,在对象模型中,我们将使用方法obj.read_attr(“attribute”)。这种映射将在实际语言中由语言的解释器或编译器完成。
本章进一步的简化是,我们在实现对象模型的代码和用于编写对象中使用的方法的代码之间没有明确的区别。在一个实际的系统中,两者通常以不同的编程语言来实现。
我们以一个简单的测试来开始读写对象字段。
def test_read_write_field():
# Python code
class A(object):
pass
obj = A()
obj.a = 1
assert obj.a == 1
obj.b = 5
assert obj.a == 1
assert obj.b == 5
obj.a = 2
assert obj.a == 2
assert obj.b == 5
# Object model code
A = Class(name="A", base_class=OBJECT, fields={}, metaclass=TYPE)
obj = Instance(A)
obj.write_attr("a", 1)
assert obj.read_attr("a") == 1
obj.write_attr("b", 5)
assert obj.read_attr("a") == 1
assert obj.read_attr("b") == 5
obj.write_attr("a", 2)
assert obj.read_attr("a") == 2
assert obj.read_attr("b") == 5
测试必须实现的三件事。Class和Instance类分别表示对象模型的类和实例。有两个类的特殊实例:OBJECT和TYPE。OBJECT对应于Python中的对象,是继承层次结构的最终基类。TYPE对应于Python中的类型,是所有类的类型。
要对Class和Instance操作,他们通过继承一个共享的基类Base来实现一个共享接口,它暴露了许多方法:
class Base(object):
""" The base class that all of the object model classes inherit from. """
def __init__(self, cls, fields):
""" Every object has a class. """
self.cls = cls
self._fields = fields
def read_attr(self, fieldname):
""" read field 'fieldname' out of the object """
return self._read_dict(fieldname)
def write_attr(self, fieldname, value):
""" write field 'fieldname' into the object """
self._write_dict(fieldname, value)
def isinstance(self, cls):
""" return True if the object is an instance of class cls """
return self.cls.issubclass(cls)
def callmethod(self, methname, *args):
""" call method 'methname' with arguments 'args' on object """
meth = self.cls._read_from_class(methname)
return meth(self, *args)
def _read_dict(self, fieldname):
""" read an field 'fieldname' out of the object's dict """
return self._fields.get(fieldname, MISSING)
def _write_dict(self, fieldname, value):
""" write a field 'fieldname' into the object's dict """
self._fields[fieldname] = value
MISSING = object()
Base类实现存储对象的类,以及包含对象的字段值的字典。现在我们需要实现Class和Instance。Instance的构造函数使类被实例化,并初始化field dict为空字典。否则实例只是一个单薄的子类,它不会添加任何额外的功能。
Class的构造函数使用类的名称,基类,类和元类的字典。对于类,字段由对象模型的用户传递到构造函数中。类构造函数也是一个基类,现在还不需要这个测试,下一节我们将使用它。
class Instance(Base):
"""Instance of a user-defined class. """
def __init__(self, cls):
assert isinstance(cls, Class)
Base.__init__(self, cls, {})
class Class(Base):
""" A User-defined class. """
def __init__(self, name, base_class, fields, metaclass):
Base.__init__(self, metaclass, fields)
self.name = name
self.base_class = base_class
由于类也是一种对象,它们(间接地)从Base继承。因此,类需要的是另一个类的一个实例:它的元类。
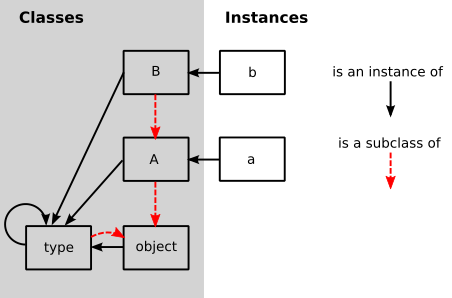
现在我们通过了第一个测试。唯一缺少的一点是基类TYPE和OBJECT的定义,它们都是Class的实例。对于这些,我们将会从Smalltalk模型中脱颖而出,该模型具有相当复杂的元类系统。相反,我们将从Python的ObjVlisp中引入的模型。
在ObjVlisp模型中,OBJECT和TYPE是交织在一起的。OBJECT是所有类的基类,意思是它没有基类。TYPE是OBJECT的子类。默认情况下,每个类都是TYPE的一个实例。TYPE和OBJECT都是TYPE的实例。 但是,程序员也可以将TYPE子类化成一个新的元类:
# set up the base hierarchy as in Python (the ObjVLisp model)
# the ultimate base class is OBJECT
OBJECT = Class(name="object", base_class=None, fields={}, metaclass=None)
# TYPE is a subclass of OBJECT
TYPE = Class(name="type", base_class=OBJECT, fields={}, metaclass=None)
# TYPE is an instance of itself
TYPE.cls = TYPE
# OBJECT is an instance of TYPE
OBJECT.cls = TYPE
要定义新的元类,就可以对TYPE进行子类化。然而,在本章的其余部分,我们不会这样做; 我们只需要使用TYPE作为每个类的元类。
现在第一次测试通过了。第二个测试检查读和写属性是否也适用于类。这很容易写,并立即通过。
def test_read_write_field_class():
# classes are objects too
# Python code
class A(object):
pass
A.a = 1
assert A.a == 1
A.a = 6
assert A.a == 6
# Object model code
A = Class(name="A", base_class=OBJECT, fields={"a": 1}, metaclass=TYPE)
assert A.read_attr("a") == 1
A.write_attr("a", 5)
assert A.read_attr("a") == 5
isinstance 检查
到目前为止,我们没有利用对象有类的事实。下一个测试实现了isinstance机制:
def test_isinstance():
# Python code
class A(object):
pass
class B(A):
pass
b = B()
assert isinstance(b, B)
assert isinstance(b, A)
assert isinstance(b, object)
assert not isinstance(b, type)
# Object model code
A = Class(name="A", base_class=OBJECT, fields={}, metaclass=TYPE)
B = Class(name="B", base_class=A, fields={}, metaclass=TYPE)
b = Instance(B)
assert b.isinstance(B)
assert b.isinstance(A)
assert b.isinstance(OBJECT)
assert not b.isinstance(TYPE)
要检查对象obj是否是某个类cls的实例,只要检查cls是obj类的父类还是类本身就足够了。要检查一个类是否是另一个类的父类,移动该类的父类。当且仅当在该链中找到其他类时,才是父类。类的父类链,包括类本身,被称为该类的“方法解析顺序”。 可以方便地递归计算:
class Class(Base):
...
def method_resolution_order(self):
""" compute the method resolution order of the class """
if self.base_class is None:
return [self]
else:
return [self] + self.base_class.method_resolution_order()
def issubclass(self, cls):
""" is self a subclass of cls? """
return cls in self.method_resolution_order()
使用该代码,测试通过。
调用方法
该对象模型还缺少调用对象方法的功能。在本章中,我们将实现一个简单的单继承模型。
def test_callmethod_simple():
# Python code
class A(object):
def f(self):
return self.x + 1
obj = A()
obj.x = 1
assert obj.f() == 2
class B(A):
pass
obj = B()
obj.x = 1
assert obj.f() == 2 # works on subclass too
# Object model code
def f_A(self):
return self.read_attr("x") + 1
A = Class(name="A", base_class=OBJECT, fields={"f": f_A}, metaclass=TYPE)
obj = Instance(A)
obj.write_attr("x", 1)
assert obj.callmethod("f") == 2
B = Class(name="B", base_class=A, fields={}, metaclass=TYPE)
obj = Instance(B)
obj.write_attr("x", 2)
assert obj.callmethod("f") == 3
要正确实现发送到对象的方法,我们将遍历对象的类的方法解析顺序。在方法解析顺序中的一个类的字典中找到的第一个方法被调用:
class Class(Base):
...
def _read_from_class(self, methname):
for cls in self.method_resolution_order():
if methname in cls._fields:
return cls._fields[methname]
return MISSING
与Base中的callmethod代码一起,这通过了测试。
为了确保参数方法工作,并且正确实现覆盖方法,我们可以使用以下稍复杂的测试,其已经通过:
def test_callmethod_subclassing_and_arguments():
# Python code
class A(object):
def g(self, arg):
return self.x + arg
obj = A()
obj.x = 1
assert obj.g(4) == 5
class B(A):
def g(self, arg):
return self.x + arg * 2
obj = B()
obj.x = 4
assert obj.g(4) == 12
# Object model code
def g_A(self, arg):
return self.read_attr("x") + arg
A = Class(name="A", base_class=OBJECT, fields={"g": g_A}, metaclass=TYPE)
obj = Instance(A)
obj.write_attr("x", 1)
assert obj.callmethod("g", 4) == 5
def g_B(self, arg):
return self.read_attr("x") + arg * 2
B = Class(name="B", base_class=A, fields={"g": g_B}, metaclass=TYPE)
obj = Instance(B)
obj.write_attr("x", 4)
assert obj.callmethod("g", 4) == 12
基于属性的模型
现在我们的对象模型的最简单版本正在运行,我们思考改进的方法。本节将介绍基于方法的模型和基于属性的模型之间的区别。另一方面,这是Smalltalk,Ruby和JavaScript以及Python和Lua之间的核心区别之一。
基于方法的模型具有作为程序执行原语的方法调用:
result = obj.f(arg1, arg2)
基于属性的模型将方法调用分为两个步骤:查找属性并调用结果:
method = obj.f
result = method(arg1, arg2)
该差异可以在以下测试中显示:
def test_bound_method():
# Python code
class A(object):
def f(self, a):
return self.x + a + 1
obj = A()
obj.x = 2
m = obj.f
assert m(4) == 7
class B(A):
pass
obj = B()
obj.x = 1
m = obj.f
assert m(10) == 12 # works on subclass too
# Object model code
def f_A(self, a):
return self.read_attr("x") + a + 1
A = Class(name="A", base_class=OBJECT, fields={"f": f_A}, metaclass=TYPE)
obj = Instance(A)
obj.write_attr("x", 2)
m = obj.read_attr("f")
assert m(4) == 7
B = Class(name="B", base_class=A, fields={}, metaclass=TYPE)
obj = Instance(B)
obj.write_attr("x", 1)
m = obj.read_attr("f")
assert m(10) == 12
虽然设置与方法调用的相应测试相同,但是调用方法的方式是不同的。首先,在对象上查找具有该方法名称的属性。该查找操作的结果是绑定方法,封装对象以及类中发现的函数的对象。 接下来,使用回调调用该绑定方法。
要实现此行为,我们需要更改Base.read_attr实现。如果在字典中找不到属性,则在类中查找该属性。如果在类中找到,并且该属性是可调用的,则需要将其转换为绑定方法。 为了模拟一个绑定的方法,我们只需使用一个闭包。除了更改Base.read_attr之外,我们还可以更改Base.callmethod以使用新的方法调用方法来确保所有测试仍然通过。
class Base(object):
...
def read_attr(self, fieldname):
""" read field 'fieldname' out of the object """
result = self._read_dict(fieldname)
if result is not MISSING:
return result
result = self.cls._read_from_class(fieldname)
if _is_bindable(result):
return _make_boundmethod(result, self)
if result is not MISSING:
return result
raise AttributeError(fieldname)
def callmethod(self, methname, *args):
""" call method 'methname' with arguments 'args' on object """
meth = self.read_attr(methname)
return meth(*args)
def _is_bindable(meth):
return callable(meth)
def _make_boundmethod(meth, self):
def bound(*args):
return meth(self, *args)
return bound
代码的其余部分不需要更改。
元对象协议
除了由程序直接调用的“普通”方法外,许多动态语言支持特殊方法。这些方法不是直接调用,而是被对象系统调用。在Python中,这些特殊方法通常具有以两个下划线开头和结尾的名称;例如__init__。可以使用特殊方法来覆盖原始操作,并为其提供自定义行为。因此,它们将对象模型机器确切地告诉对象。Python的对象模型有几十种特殊的方法。
Meta-object协议由Smalltalk引入,但更常用于Common Lisp的对象系统,如CLOS。这也是名称元对象协议,用特殊方法的集合创造。
在本章中,我们将添加三个meta-hooks到我们的对象模型,用于微调当读取和写入属性时会发生什么。我们首先添加的特殊方法是__getattr__和__setattr__,它们紧跟Python命名后。
自定义读和写和属性
当通过正常方式找不到正在查找的属性时,对象模型调用__getattr__;即既不在实例上也不在课堂上。它获取被查找的属性的名称作为参数。相当于__getattr__方法是早期Smalltalk系统的一部分doesNotUnderstand。
__setattr__的情况有点不同。由于设置属性始终创建它,所以在设置属性时始终会调用__setattr__。为了确保__setattr__方法始终存在,OBJECT类有一个__setattr__的定义。它的实现设置属性,将属性写入对象的字典。在某些情况下,这也使得用户定义的__setattr__可以委托给OBJECT .__ setattr__。
这两种特殊方法的测试如下:
def test_getattr():
# Python code
class A(object):
def __getattr__(self, name):
if name == "fahrenheit":
return self.celsius * 9. / 5. + 32
raise AttributeError(name)
def __setattr__(self, name, value):
if name == "fahrenheit":
self.celsius = (value - 32) * 5. / 9.
else:
# call the base implementation
object.__setattr__(self, name, value)
obj = A()
obj.celsius = 30
assert obj.fahrenheit == 86 # test __getattr__
obj.celsius = 40
assert obj.fahrenheit == 104
obj.fahrenheit = 86 # test __setattr__
assert obj.celsius == 30
assert obj.fahrenheit == 86
# Object model code
def __getattr__(self, name):
if name == "fahrenheit":
return self.read_attr("celsius") * 9. / 5. + 32
raise AttributeError(name)
def __setattr__(self, name, value):
if name == "fahrenheit":
self.write_attr("celsius", (value - 32) * 5. / 9.)
else:
# call the base implementation
OBJECT.read_attr("__setattr__")(self, name, value)
A = Class(name="A", base_class=OBJECT,
fields={"__getattr__": __getattr__, "__setattr__": __setattr__},
metaclass=TYPE)
obj = Instance(A)
obj.write_attr("celsius", 30)
assert obj.read_attr("fahrenheit") == 86 # test __getattr__
obj.write_attr("celsius", 40)
assert obj.read_attr("fahrenheit") == 104
obj.write_attr("fahrenheit", 86) # test __setattr__
assert obj.read_attr("celsius") == 30
assert obj.read_attr("fahrenheit") == 86
为了通过这些测试,需要改变Base.read_attr和Base.write_attr方法:
class Base(object):
...
def read_attr(self, fieldname):
""" read field 'fieldname' out of the object """
result = self._read_dict(fieldname)
if result is not MISSING:
return result
result = self.cls._read_from_class(fieldname)
if _is_bindable(result):
return _make_boundmethod(result, self)
if result is not MISSING:
return result
meth = self.cls._read_from_class("__getattr__")
if meth is not MISSING:
return meth(self, fieldname)
raise AttributeError(fieldname)
def write_attr(self, fieldname, value):
""" write field 'fieldname' into the object """
meth = self.cls._read_from_class("__setattr__")
return meth(self, fieldname, value)
如果方法存在,则调用__getattr__更改读取属性的过程,并使用fieldname作为参数,而不是引发错误。请注意,__getattr__仅在类中查找,而不是递归调用self.read_attr("__getattr__") 。那是因为如果没有在对象上定义__getattr__,后者会导致read_attr的无限递归。
属性的写入推到__setattr__方法里。为了使它工作,OBJECT需要一个__setattr__方法来调用默认行为,如下所示:
def OBJECT__setattr__(self, fieldname, value):
self._write_dict(fieldname, value)
OBJECT = Class("object", None, {"__setattr__": OBJECT__setattr__}, None)
OBJECT__setattr__的行为就像以前的write_attr行为。通过这些修改,通过新的测试。
描述符协议
上述测试提供了不同范围之间的自动转换,属性名称需要在__getattr__和__setattr__方法中显式检查。为了解决这个问题,描述符协议是在Python中引入的。
虽然在对象上调用__getattr__和__setattr__读取属性,但是描述符协议对从对象获取属性的结果调用了一种特殊方法。可以将其视为将方法绑定到一般化的对象 - 实际上,使用描述符协议来实现将方法绑定到对象。除了绑定的方法之外,Python中描述符协议的最重要的用例是staticmethod,classmethod和property的实现。
在本小节中,我们将介绍处理绑定对象的描述符协议的子集。这是使用特殊方法__get__完成的,最好用示例测试来解释:
def test_get():
# Python code
class FahrenheitGetter(object):
def __get__(self, inst, cls):
return inst.celsius * 9. / 5. + 32
class A(object):
fahrenheit = FahrenheitGetter()
obj = A()
obj.celsius = 30
assert obj.fahrenheit == 86
# Object model code
class FahrenheitGetter(object):
def __get__(self, inst, cls):
return inst.read_attr("celsius") * 9. / 5. + 32
A = Class(name="A", base_class=OBJECT,
fields={"fahrenheit": FahrenheitGetter()},
metaclass=TYPE)
obj = Instance(A)
obj.write_attr("celsius", 30)
assert obj.read_attr("fahrenheit") == 86
FahrenheitGetter实例中调用__get__方法,在obj类中查找之后。__get__的参数是查找完成的实例。
实现它很容易。我们只需要更改_is_bindable和_make_boundmethod:
def _is_bindable(meth):
return hasattr(meth, "__get__")
def _make_boundmethod(meth, self):
return meth.__get__(self, None)
这使测试通过。以前关于绑定方法的测试还是通过的,因为Python的函数有一个返回绑定方法对象的__get__方法。
在实践中,描述符协议相当复杂。它还支持__set__来覆盖属性之前的含义。此外,删减一部分代码。请注意,_make_boundmethod在实现级别调用__get__,而不是使用meth.read_attr("__get__")。这是必要的,因为我们的对象模型借用了Python的函数和方法,而不是使用对象模型的表示。更完整的对象模型将不得不解决这个问题。
实例优化
虽然对象模型的前三个变体涉及行为变化,但在最后一节中,我们将会对优化进行研究,而不会产生任何行为影响。这种优化被称为映射,并在虚拟机中开创了自编程语言6。它仍然是最重要的对象模型优化之一:它用于PyPy和所有现代JavaScript VM,如V8(优化称为隐藏类)。
优化从以下观察开始:在到目前为止所实现的对象模型中,所有实例都使用完整的字典来存储其属性。使用散列图实现字典,这需要大量的内存。此外,同一类的实例的字典通常也具有相同的键。例如,给定一个类Point,所有其实例的字典的键可能是“x”和“y”。
地图优化利用了这一事实。它将每个实例的字典有效地分成两部分。存储可以在具有相同属性名称集的所有实例之间共享的键(映射)的部分。然后,该实例仅存储对共享映射的引用和列表中的属性值(这在内存中比字典更紧凑)。该映射将从属性名称到索引的映射存储到该列表中。
对这种行为的简单测试如下所示:
def test_maps():
# white box test inspecting the implementation
Point = Class(name="Point", base_class=OBJECT, fields={}, metaclass=TYPE)
p1 = Instance(Point)
p1.write_attr("x", 1)
p1.write_attr("y", 2)
assert p1.storage == [1, 2]
assert p1.map.attrs == {"x": 0, "y": 1}
p2 = Instance(Point)
p2.write_attr("x", 5)
p2.write_attr("y", 6)
assert p1.map is p2.map
assert p2.storage == [5, 6]
p1.write_attr("x", -1)
p1.write_attr("y", -2)
assert p1.map is p2.map
assert p1.storage == [-1, -2]
p3 = Instance(Point)
p3.write_attr("x", 100)
p3.write_attr("z", -343)
assert p3.map is not p1.map
assert p3.map.attrs == {"x": 0, "z": 1}
请注意,这是一个不同于我们之前写的测试。所有以前的测试刚刚通过暴露的接口测试了类的行为。该测试通过读取内部属性并将其与预定义值进行比较来检查Instance类的实现细节。因此,这个测试称为白盒测试。
p1映射的attrs属性将实例的布局描述为存储在p1的位置0和1处的两个属性“x”和“y”。第二个实例p2,以相同的顺序添加相同的属性将使其结束同一个地图。如果添加了不同的属性,则不能共享地图。
Map类看起来像这样:
class Map(object):
def __init__(self, attrs):
self.attrs = attrs
self.next_maps = {}
def get_index(self, fieldname):
return self.attrs.get(fieldname, -1)
def next_map(self, fieldname):
assert fieldname not in self.attrs
if fieldname in self.next_maps:
return self.next_maps[fieldname]
attrs = self.attrs.copy()
attrs[fieldname] = len(attrs)
result = self.next_maps[fieldname] = Map(attrs)
return result
EMPTY_MAP = Map({})
Map有两种方法,get_index和next_map。 前者是用于查找对象存储中的属性名称的索引。后者添加到新属性对象。这种情况下,对象需要使用next_map计算的不同映射。该方法使用next_maps字典来缓存已创建的地图。这样,具有相同布局的对象也使用相同的Map对象。
![]()
Instance代码如下:
class Instance(Base):
"""Instance of a user-defined class. """
def __init__(self, cls):
assert isinstance(cls, Class)
Base.__init__(self, cls, None)
self.map = EMPTY_MAP
self.storage = []
def _read_dict(self, fieldname):
index = self.map.get_index(fieldname)
if index == -1:
return MISSING
return self.storage[index]
def _write_dict(self, fieldname, value):
index = self.map.get_index(fieldname)
if index != -1:
self.storage[index] = value
else:
new_map = self.map.next_map(fieldname)
self.storage.append(value)
self.map = new_map
该类传递None给Base,因为Instance将以另一种方式存储字典的内容。因此,它需要覆盖_read_dict和_write_dict方法。我们重构Base类,使其不再存储字段字典,但是现在的实例存储是不够的。
新创建的实例使用没有属性的EMPTY_MAP和空存储启动。要实现_read_dict,请求实例的映射关系到属性名称的索引。然后返回存储列表的相应条目。
写入字典有两种情况。一方面可以改变现有属性的值。这是通过简单更改相应索引处的存储来完成的。另一方面,如果属性不存在,则需要使用next_map方法进行映射转换(图14.2)。新属性的值附加到存储列表。
这个优化实现了什么?在具有相同布局的实例常见情况下,它优化了内存使用。这不是一个通用的优化:使用不同的属性集创建实例的代码将会比仅使用字典占用更大的内存。
这是在优化动态语言中的常见问题。通常都不可能找到更快的内存或更少内存的优化。实践中,选择的优化适用于通用语言,同时可能使使用动态特征的程序更糟。
地图的另一个有趣的方面是,虽然在这里它们只是优化内存使用,但是在使用JIT编译器的实际虚拟机中,它们也提高了程序的性能。为了实现这一点,JIT使用地图编译属性查找,为在固定偏移量的对象存储中的查找,从而完全摆脱字典查找。
潜在扩展
很容易扩展我们的对象模型和实验各种语言设计。还有其他可能:
-
最简单的方法是添加更多的特殊方法。添加一些容易有趣的是
__init__,__getattribute__,__set__。 -
该模型可以非常容易地扩展支持多重继承。为了做到这一点,每个类都会得到一个基类列表。需要更改
Class.method_resolution_order方法来支持查找方法。可以使用深度优先搜索来删除重复项。更复杂但更好的是C3算法,它增加了菱形多重继承层次的基础,并拒绝了不可靠的继承模式。 -
根本的变化是切换到原模型,其中涉及删除类和实例之间的区别。
结论
面向对象编程语言设计的核心是其对象模型的细节。编写小对象模型原型是更好地了解现有语言的内部工作,并深入了解面向对象语言的设计。使用对象模型是尝试不同语言设计思想的好方法,而不必担心实现无聊的部分,如解析和执行代码。
这样的对象模型在实践中也是有用的,而不仅仅是实验的载体。它们可以嵌入其他语言并为其他语言中使用。这种方法的例子是很常见的:用于GLib和Gnome库中的用C编写的GObject对象模型;或JavaScript中的各种类系统实现。
引用
-
P. Cointe, “Metaclasses are first class: The ObjVlisp Model,” SIGPLAN Not, vol. 22, no. 12, pp. 156–162, 1987.↩
-
It seems that the attribute-based model is conceptually more complex, because it needs both method lookup and call. In practice, calling something is defined by looking up and calling a special attribute call, so conceptual simplicity is regained. This won’t be implemented in this chapter, however.)↩
-
G. Kiczales, J. des Rivieres, and D. G. Bobrow, The Art of the Metaobject Protocol. Cambridge, Mass: The MIT Press, 1991.↩
-
A. Goldberg, Smalltalk-80: The Language and its Implementation. Addison-Wesley, 1983, page 61.↩
-
In Python the second argument is the class where the attribute was found, though we will ignore that here.↩
-
C. Chambers, D. Ungar, and E. Lee, “An efficient implementation of SELF, a dynamically-typed object-oriented language based on prototypes,” in OOPSLA, 1989, vol. 24.↩
-
How that works is beyond the scope of this chapter. I tried to give a reasonably readable account of it in a paper I wrote a few years ago. It uses an object model that is basically a variant of the one in this chapter: C. F. Bolz, A. Cuni, M. Fijałkowski, M. Leuschel, S. Pedroni, and A. Rigo, “Runtime feedback in a meta-tracing JIT for efficient dynamic languages,” in Proceedings of the 6th Workshop on Implementation, Compilation, Optimization of Object-Oriented Languages, Programs and Systems, New York, NY, USA, 2011, pp. 9:1–9:8.↩