re module
Python re module provides regular expression functions.
# -*- coding: UTF-8 -*-
import re
# re.match
print(re.match('www', 'www.runoob.com').span())
print(re.match('com', 'www.runoob.com'))
# re.search
## partner
key = r"<html><body><h1>hello world<h1></body></html>"
p1 = r"(?<=<h1>).+?(?=<h1>)"## regular expression
pattern1 = re.compile(p1)
match1 = re.search(pattern1, key)
print match1.group(0)
# re.match means if the string is not match the pattern at the begining, then fail, return None
# re.search will search the whole string to find all
#re.sub to replace the match part
phone = "2004-959-559 # 这是一个国外电话号码"
# delete python comment
num = re.sub(r'#.*$', "", phone)
print "电话号码是: ", num
# delete -
num = re.sub(r'\D', "", phone)
print "电话号码是 : ", num
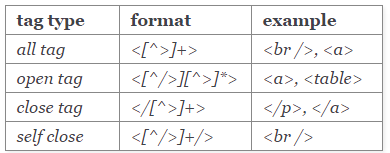
HTML tags
re.findall()
# split all string
source = "Hello World Ker HAHA"
print re.findall('[\w]+', source)
import urllib
s = urllib.urlopen('https://www.python.org')
html = s.read()
s.close()
print re.findall('<[^/>][^>]*>', html)[0:2]
Substitute String
# Substitute String
res = "1a2b3c"
print re.sub(r'[a-z]',' ', res)
# substitute with group reference
date = r'2016-01-01'
print re.sub(r'(\d{4})-(\d{2})-(\d{2})',r'\2/\3/\1/',date)
Full